前言
一篇早该完成的文章,中间因为一些事情断断续续补完。主要从源码分析截止25年初Apache Shiro的一些漏洞。
进度:
| CVE ID | 进度 |
|---|---|
| CVE-2010-3863 | √ |
| CVE-2014-0074 | |
| CVE-2016-4437(Shiro-550) | √ |
| CVE-2016-6802 | √ |
| CVE-2019-12422(Shiro-721 | √ |
| CVE-2020-1957(Shiro-682的绕过) | √ |
| CVE-2020-11989 | √ |
| CVE-2020-13933 | √ |
| CVE-2020-17510 | √ |
| CVE-2020-17523 | √ |
| CVE-2021-41303 | √ |
| CVE-2022-32532 | √ |
| CVE-2022-40664 | √ |
| CVE-2023-22602 | √ |
| CVE-2023-34478 | |
| CVE-2023-46749 | |
| CVE-2023-46750 | √ |
在开始写这篇的时候,迟迟不能动笔,因为不知道我该如何开始讲述接下来的内容,如果从框架的功能,流程一步步分析,会不会太过繁琐和乏味?只介绍漏洞又是否太让刚接触的同学感觉迷糊?
框架简介
就十分简略说一下吧,具体体关于Shiro的框架的知识可以看Shiro官方文档:Apache Shiro Reference Documentation | Apache Shiro。觉得看英文费劲可以看该中文文档:Apache Shiro 中文文档
Apache Shiro 是一个功能强大的易于使用的 Java 安全框架,主要用于处理以下四个核心方面:身份验证(Authentication)、授权(Authorization)、会话管理(Session Management)和加密(Cryptography)。

典型架构:
Shiro 的一个典型应用包括以下组件:
- Subject: 代表当前用户的安全操作者。
- SecurityManager: 核心接口,Shiro 的所有安全操作都通过它来协调。
- Realm: 用于从数据存储中获取安全数据(如用户、角色和权限信息),类似于桥梁。
框架流程
那么还是说明一下框架的一个流程,熟悉的同学可以跳过该部分哦。我将其分为初始化流程和启动之后拦截过滤的流程。
初始化流程
先简单说一下大致一个流程
创建 Shiro 配置
创建 Shiro 的
SecurityManager注册 Realm
配置 Filter
启动 Shiro
用朋友的一句话
所有的开始,都是从配置开始,配置的方式主要有两种:编程式配置,配置文件读取与解析(利用反射机制,调用构造函数,setter,getter),初始化的对象,主要是SecurityManager
由于我的环境主要用到了shiro-spring这个依赖包,是 Apache Shiro 项目为 Spring 框架提供的支持模块。因此配置可以写在java文件里,而无需shiro.ini。代码参考:Java Shiro 权限绕过多漏洞分析 | Drunkbaby’s Blog
1 |
|
上面的一个Shiro的配置类,我们是定义了三个bean。在默认情况下,Spring 初始化 Bean 的顺序通常是由依赖关系决定的。
userRealmBean:userRealm 是一个独立的 Bean,没有依赖其他 Bean,因此它将首先被创建。
securityManager Bean:securityManager Bean 依赖于 userRealm,因为它在构造时将 userRealm 作为参数传递。Spring 在创建 securityManager Bean 时会先实例化 userRealm,然后将它注入到 securityManager 中。
shiroFilterFactoryBean Bean:shiroFilterFactoryBean 依赖于 securityManager。在创建此 Bean 时,Spring 会先确保 securityManager 已经被创建并初始化,然后再将其注入到 shiroFilterFactoryBean 中。
因此,Bean 的初始化顺序为:
userRealm→ 首先被初始化。securityManager→ 依赖于userRealm,在userRealm初始化后初始化。shiroFilterFactoryBean→ 依赖于securityManager,在securityManager初始化后初始化。
userRealm
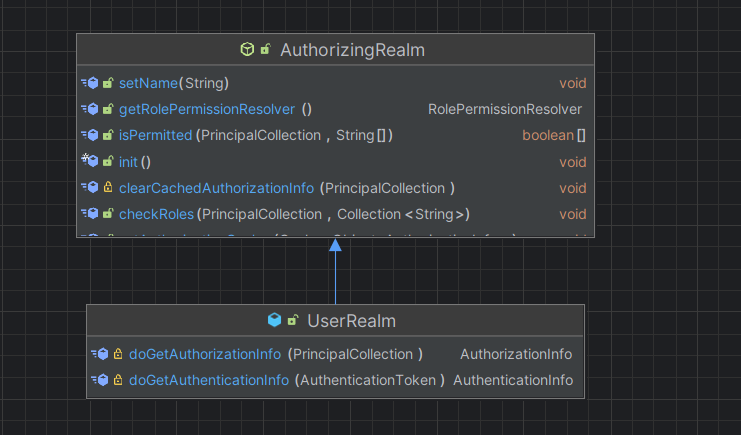
没啥好说的,继承自 Shiro 提供的 AuthorizingRealm 类,可以利用 Shiro 的内置方法进行认证和授权。比如通过重写的 doGetAuthorizationInfo 和 doGetAuthenticationInfo 方法,访问数据库,获取认证信息,并通过shiro的api进行认证或授权。正如之前所说 Realm 用于从数据存储中获取安全数据(如用户、角色和权限信息)。
securityManager
在方法中创建 DefaultWebSecurityManager 实例。设置其关联的 Realm 。这里主要是通过 securityManager.setRealm(userRealm); 语句,将自定义的 UserRealm 配置到 SecurityManager 中。
shiroFilterFactoryBean
这个就值得好好说一说了。首先我们这是配置了一个集成 Apache Shiro 安全框架的过滤器工厂 Bean。ShiroFilterFactoryBean实现了 Spring 的 FactoryBean 接口。 FactoryBean 提供了一种创建复杂或动态 Bean 实例的机制,允许延迟和定制实例化过程。通过实现 FactoryBean,ShiroFilterFactoryBean 可以通过重写 getObject() 方法来返回实际需要在 Spring 上下文中使用的对象,而不仅仅是 ShiroFilterFactoryBean 自身。在这里,我们可以追到 createInstance() 方法,发现返回的是 SpringShiroFilter。
1 | public Object getObject() throws Exception { |
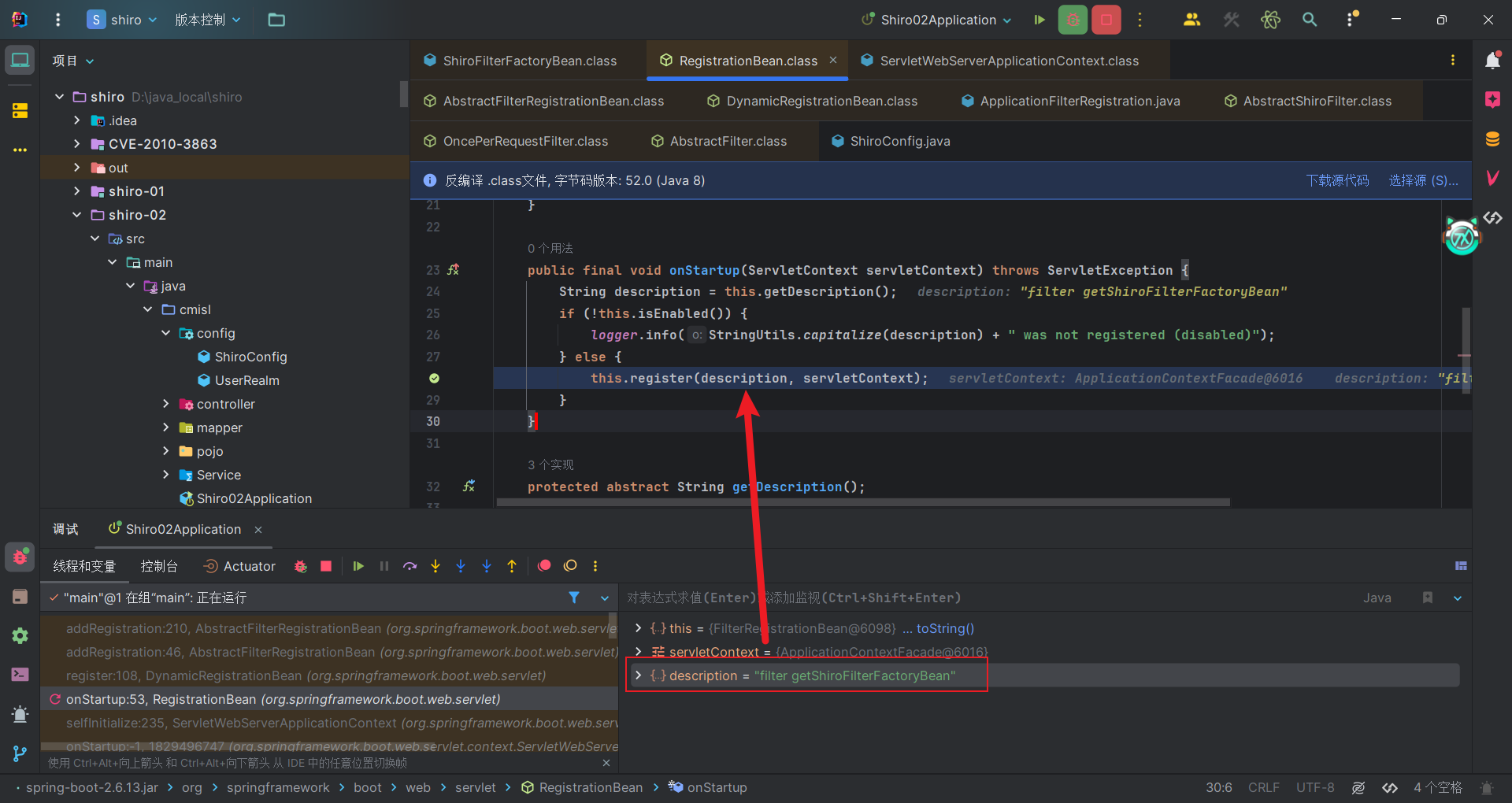
我们先整体看 SpringShiroFilter 类,是一个过滤器,继承了 javax.servlet.Filter,在Spring初始化的时候,会遍历每个Bean,并获取该Bean的 description(描述),而 SpringShiroFilter,由于继承关系,其描述为 filter getShiroFilterFactoryBean,可以看到前缀是filter,标识其为一个过滤器。然后会将其注册到Web应用程序上下文(ServletContext)中。
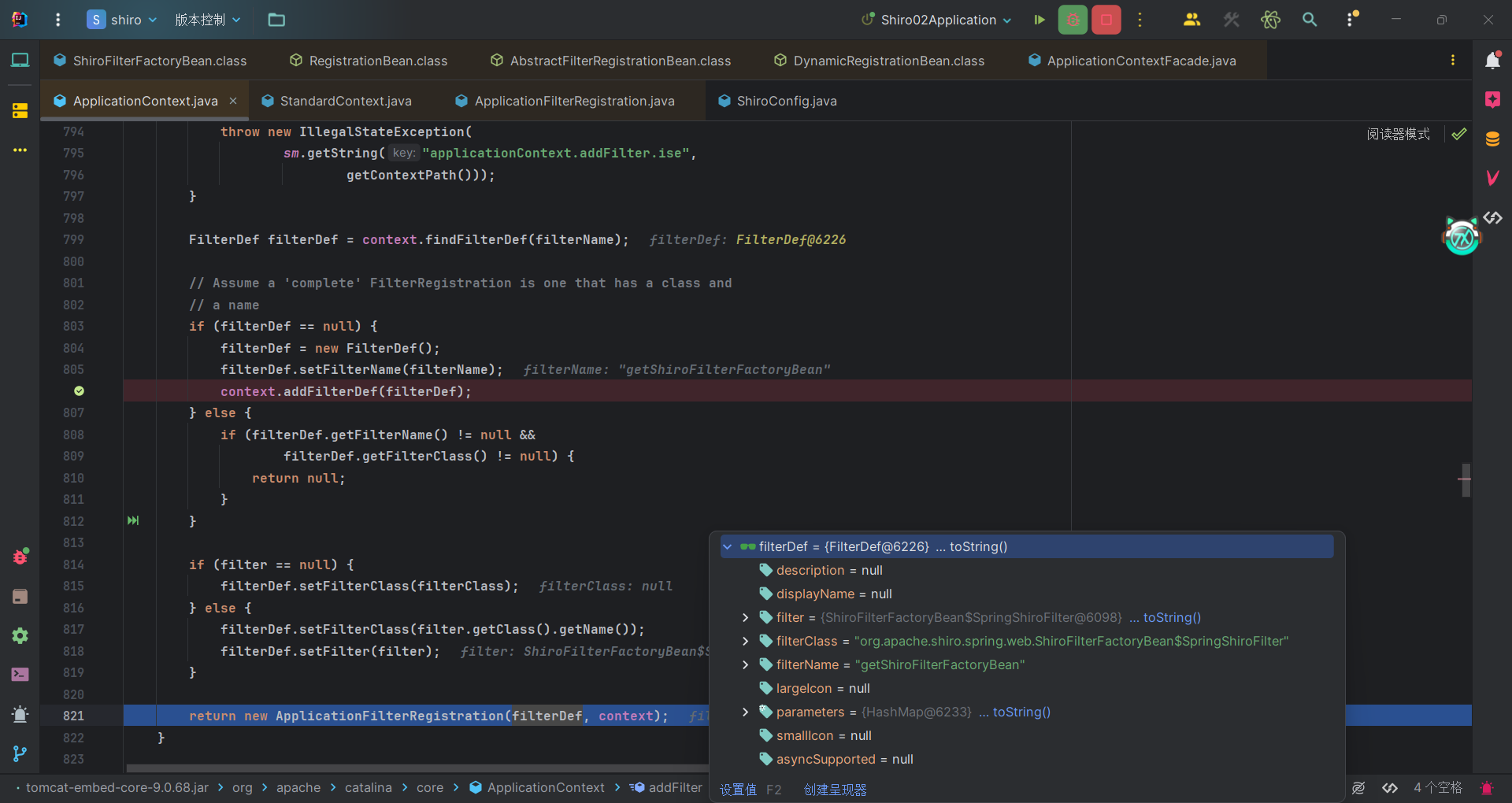
然后在org.apache.catalina.core.StandardContext#addFilterMapBefore中将过滤器的映射规则添加到应用程序中的映射集合中。可以看到SpringShiroFilter的urlPatterns属性是/*,即希望所有的请求都会通过该过滤器。因此我们所有的请求都会在shiro的过滤器中进行二次处理。
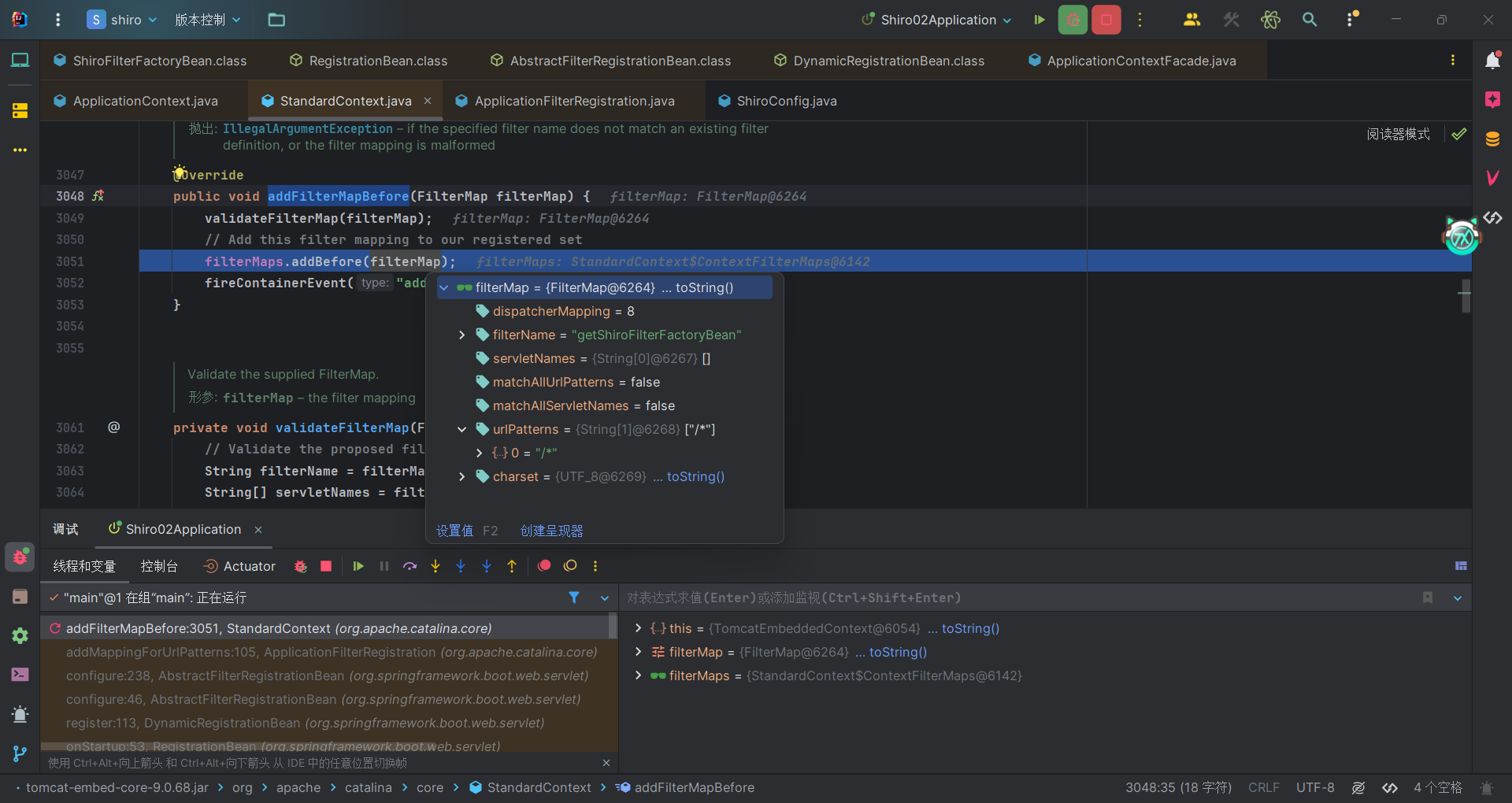
接着我们在细看 SpringShiroFilter 类的内部,前面提到了其实例化是通过调用重写的 FactoryBean 接口的 getObject 方法得到的。并且具体代码是在 getObject 方法调用的 createInstance 方法中,因此关注 ShiroFilterFactoryBean#createInstance 方法。那么提取出完整的该函数。
1 | protected AbstractShiroFilter createInstance() throws Exception { |
可以看到在构造SpringShiroFilter类的时候,调用其构造函数传入二楼两个变量,securityManager 和 chainResolver,securityManager 就是当前类的securityManager 属性,在我们的Shiro配置类中初始化的时候就设置了,其值就是Shiro配置类中我们设置的securityManager Bean的实例。如下:
1 | // 创建 DefaultWebSecurityManager |
chainResolver是一个PathMatchingFilterChainResolver类,大概意思是路径匹配过滤器链解析器。类图如下,初始化的时候会设置filterChainManager属性,当然如果初始化调用的是是无参构造函数,就会new一个FilterChainManager对象,不过后续任然可以调用其setFilterChainManager方法来设置自己配置的FilterChainManager对象。
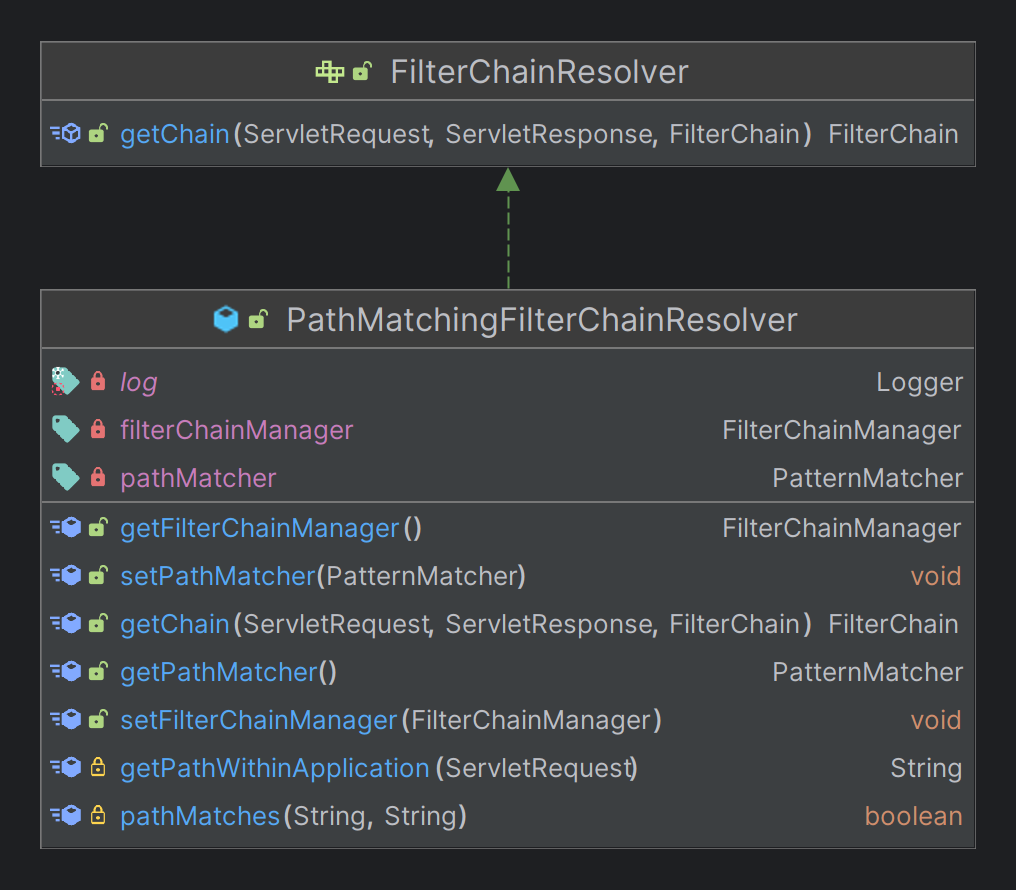
chainResolver就是通过setFilterChainManager方法设置filterChainManager的。具体的值是通过createFilterChainManager方法来获取的。
1 | protected FilterChainManager createFilterChainManager() { |
首先是创建默认的过滤器链管理器,初始化的时候,会把shiro的默认过滤器的Class对象都添加进去。
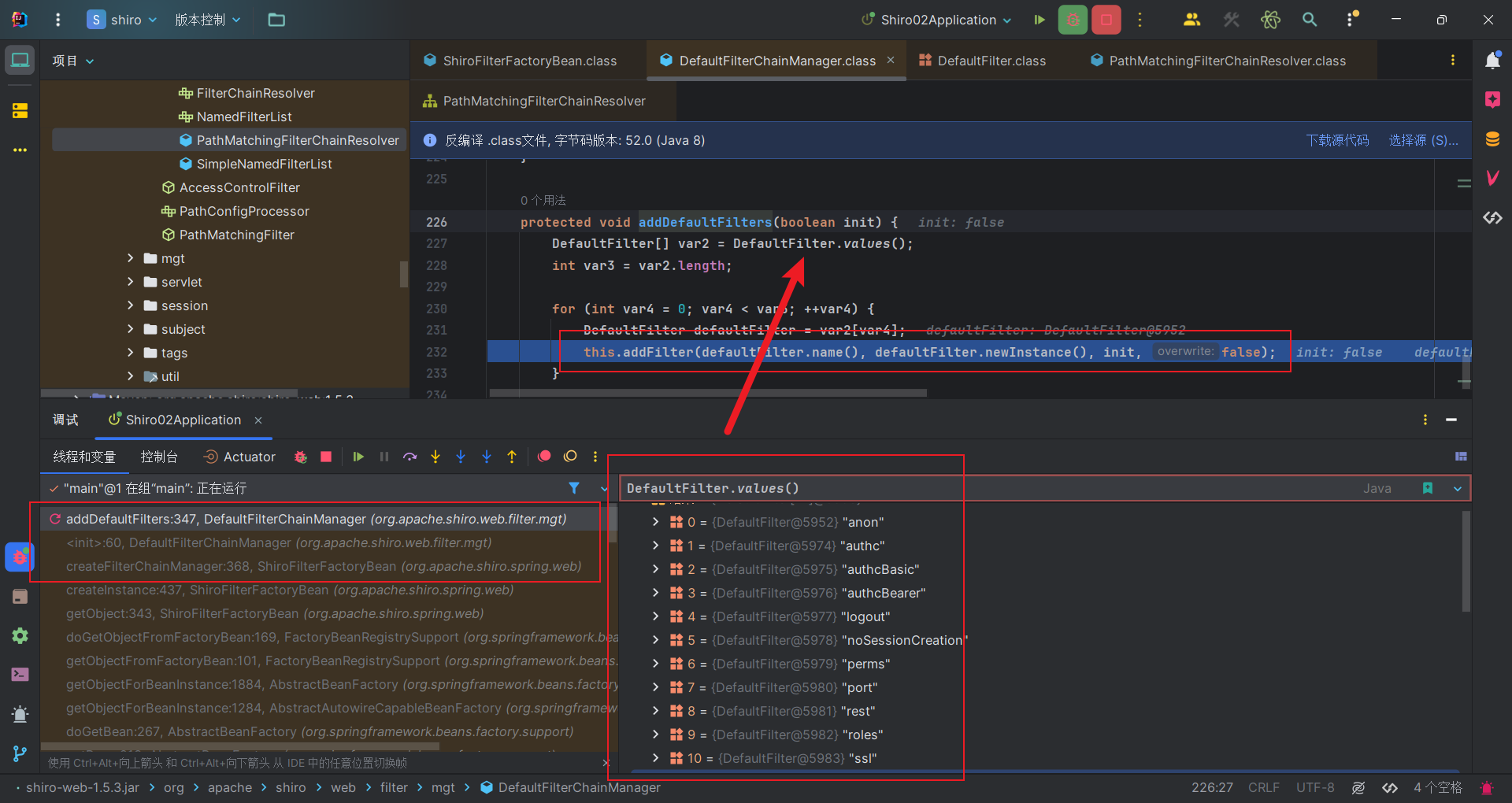
1 | public enum DefaultFilter { |
然后遍历每个过滤器,对其调用applyGlobalPropertiesIfNecessary方法,将每个过滤器应用全局属性。简单来说就是通过查看当前 URL 的设置是否为默认值或未设置,来决定是否应用一些全局配置的 URL。比如我修改某个url,就会遍历过滤器。这样所有相关的过滤器都会一起调整设置。我们设置的LoginUrl是/toLogin,可以看到会把所有相关过滤器的LoginUrl从/login.jsp设置成/toLogin
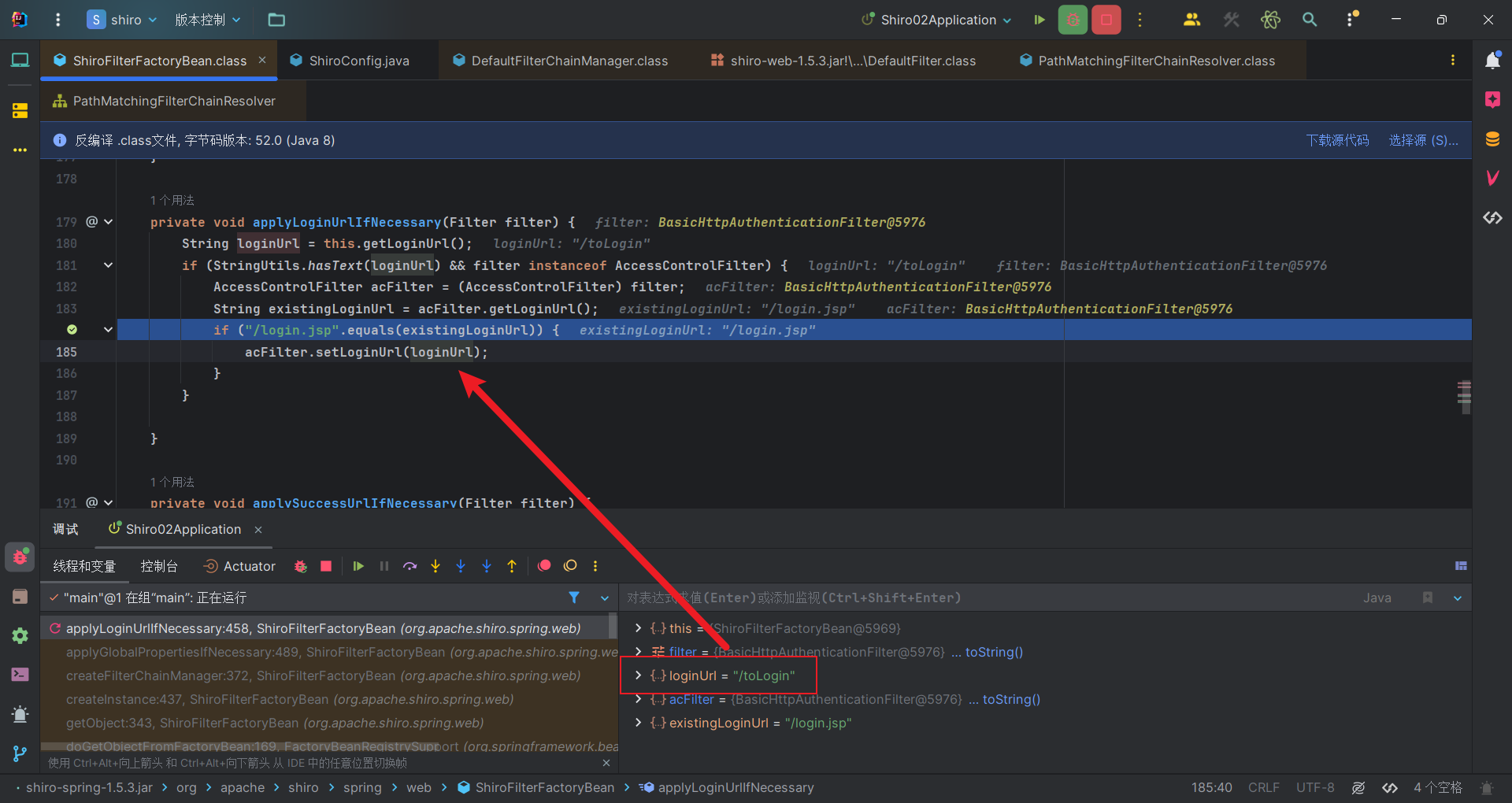
然后回到ShiroFilterFactoryBean#createFilterChainManager,检查其filters属性是否为空,这里是空,直接跳过if语句,刚刚我们只是处理了从默认过滤器链管理器得到的过滤器。接着获取过滤器链定义映射。对应我们前面这两行代码:
1 | filterMap.put("/user/*", "authc"); |
因此获取到的就是{/user/*=authc}这个Map,获取到键和值,将authc对应的过滤器与/user/*路径包装起来。这样才算完成一个过滤链管理器FilterChainManager的初始化,其属性不仅有Shiro的默认过滤器,还将过滤器和url包装在了一起。
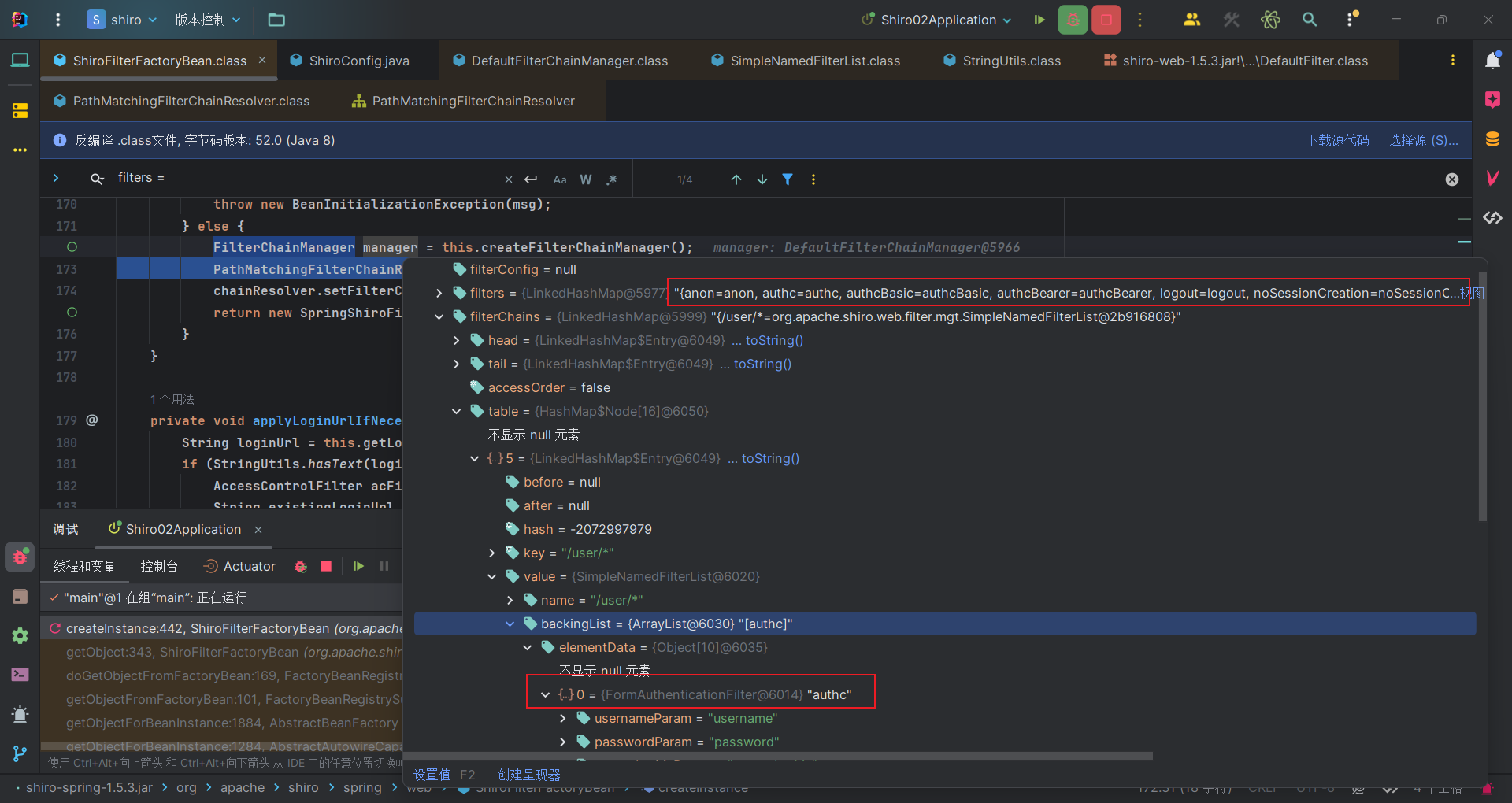
将路径匹配过滤器链解析器chainResolver的FilterChainManager属性设置为刚刚创建出来的过滤链管理器manager。然后就是我们最开始提到的securityManager 和 chainResolver设置进SpringShiroFilter了。
过滤流程
关于Tomcat Filter的一些知识可以参考:JAVA内存马系列 - cmisl_破站
那么Tomcat会调用过滤链filterChain的doFilter方法,从第一个过滤器的doFilter链式调用下去。而过滤器链filterChain的创建是从filterMaps获取过滤器的名称,再用名称去上下文得到对应过滤器的配置去生成的。
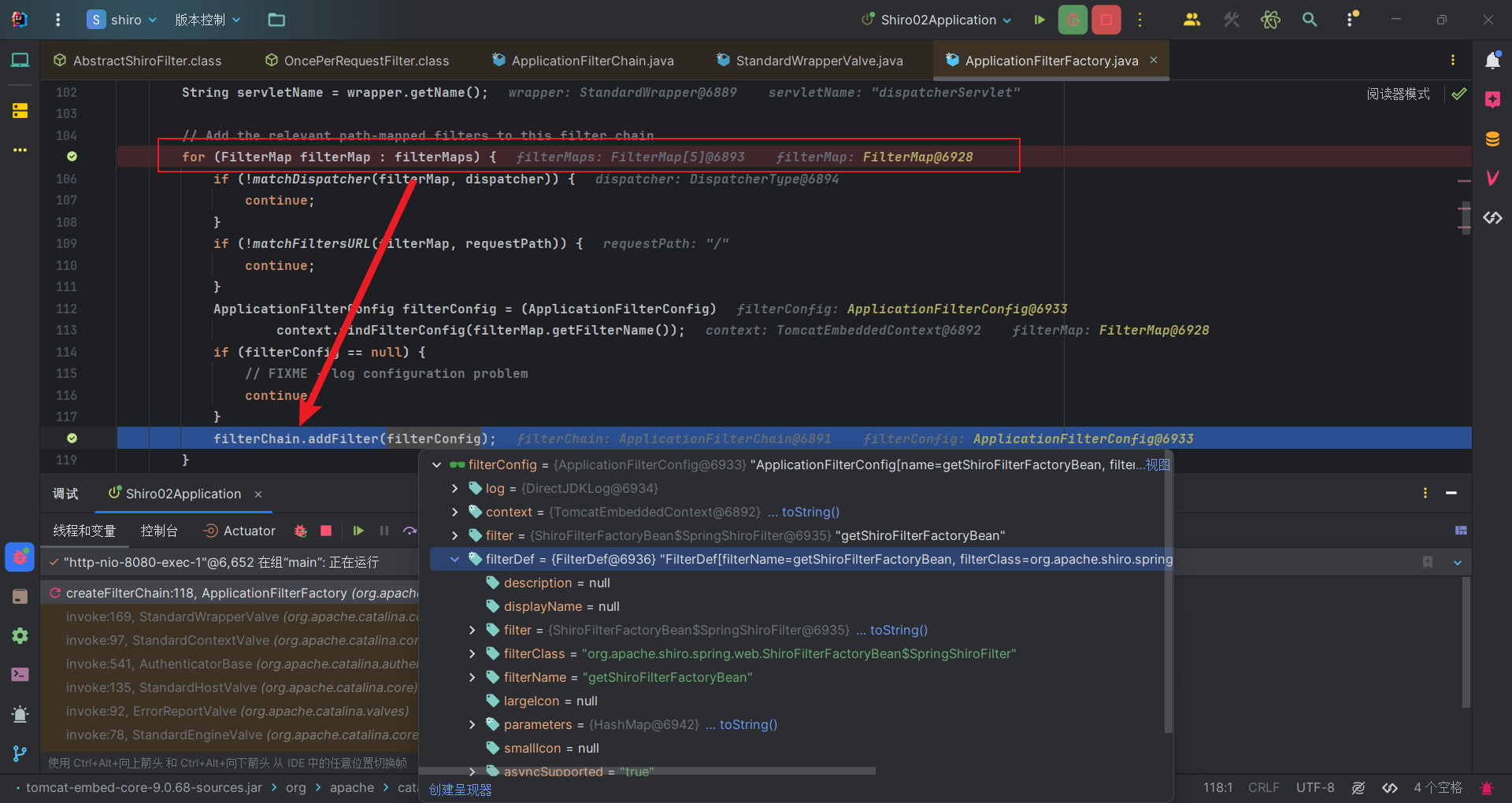
由前面初始化流程的分析,我们的SpringShiroFilter会被配置进filterMaps,那么在过滤链中也有其一席之地。所以,在链式调用doFilter时,也会调到SpringShiroFilter。而由于其本身没有doFilter方法,所以会调到其父类的父类OncePerRequestFilter的doFilter方法中。
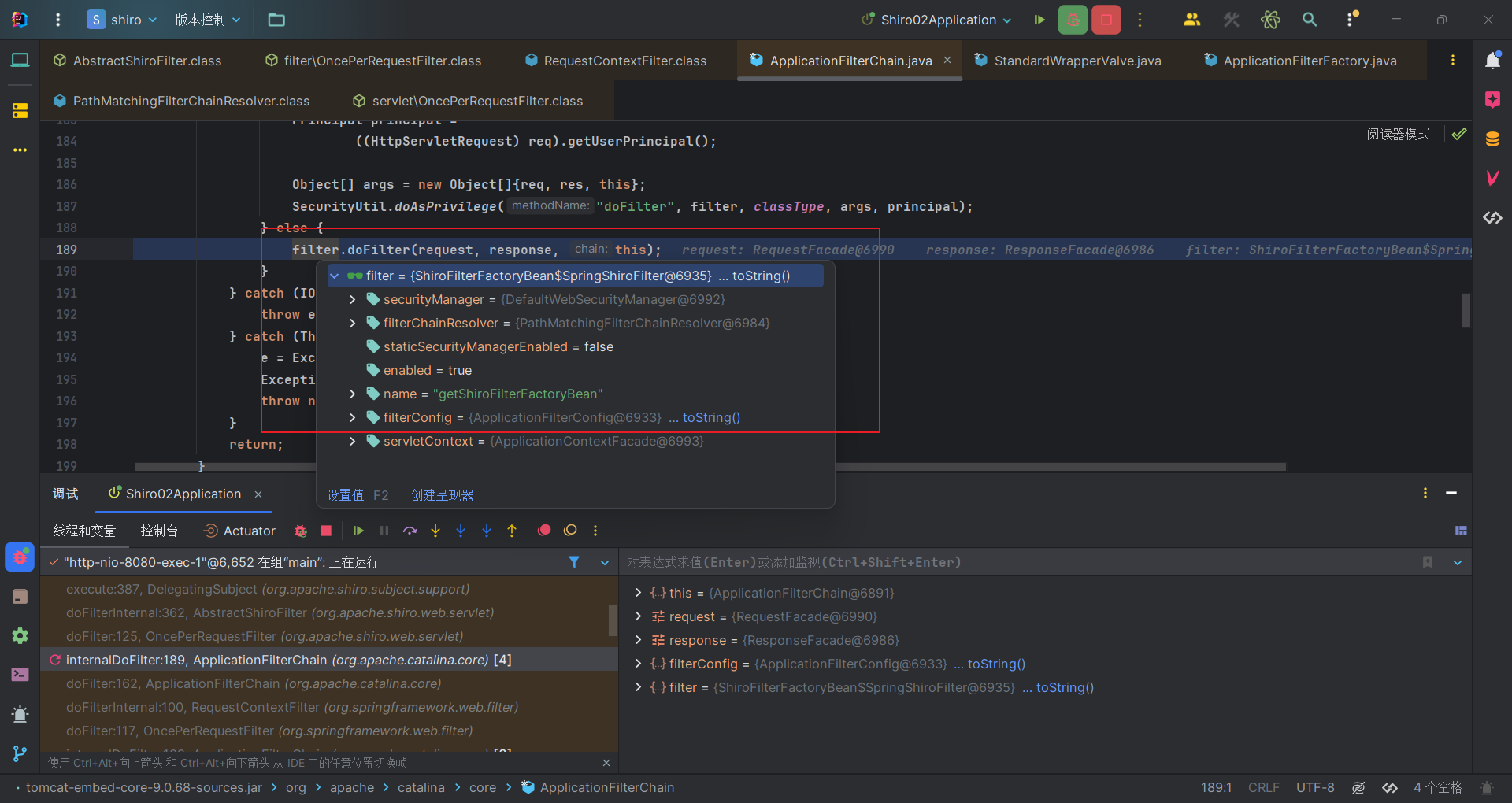
OncePerRequestFilter#doFilter方法调用doFilterInternal方法,SpringShiroFilter又没有,而其父类有,那就调到了其父类,也是一个抽象类的AbstractShiroFilter#doFilterInternal中。
1 | protected void doFilterInternal(ServletRequest servletRequest, ServletResponse servletResponse, final FilterChain chain) throws ServletException, IOException { |
从请求中创建一个subject,代表当前会话,然后调用execute进行可执行操作。接着就是一顺调用,直到AbstractShiroFilter#getExecutionChain
1 | protected FilterChain getExecutionChain(ServletRequest request, ServletResponse response, FilterChain origChain) { |
获取过滤链解析器resolver,其值正是初始化时的 chainResolver。是一个PathMatchingFilterChainResolver类,因此顺着来到了PathMatchingFilterChainResolver#getChain。
1 | public FilterChain getChain(ServletRequest request, ServletResponse response, FilterChain originalChain) { |
上面这段代码首先获取一个filterChainManager,同样,值是我们初始化SpringShiroFilter时的securityManager参数。然后会获取请求url,然后经过一个简单的判断保证url不以/符号结尾(根目录除外)。遍历 filterChainManager 中所有的路径模式,寻找与 requestURI 匹配的路径模式。路径匹配是通过调用 pathMatches(pathPattern, requestURI) 方法来实现。具体可以追到AntPathMatcher#doMatch方法中。
然后匹配成功调用filterChainManager.proxy(originalChain, pathPattern)第一个参数是原始过滤连,第二个是匹配到的路径。比如我访问/user/add,而由我们前面的配置,访问/user/*会进入authc对应的过滤器,即FormAuthenticationFilter。所以我们会匹配到/user/*这个路径,因此进入这个方法。
1 | `public FilterChain proxy(FilterChain original, String chainName) { |
根据匹配的路径获取与其相关联的 NamedFilterList,这是一个过滤器列表,代表了一组有序的过滤器。据此去SimpleNamedFilterList#proxy获取一个代理过滤链,封装了原始过滤链和匹配路径与其过滤器。
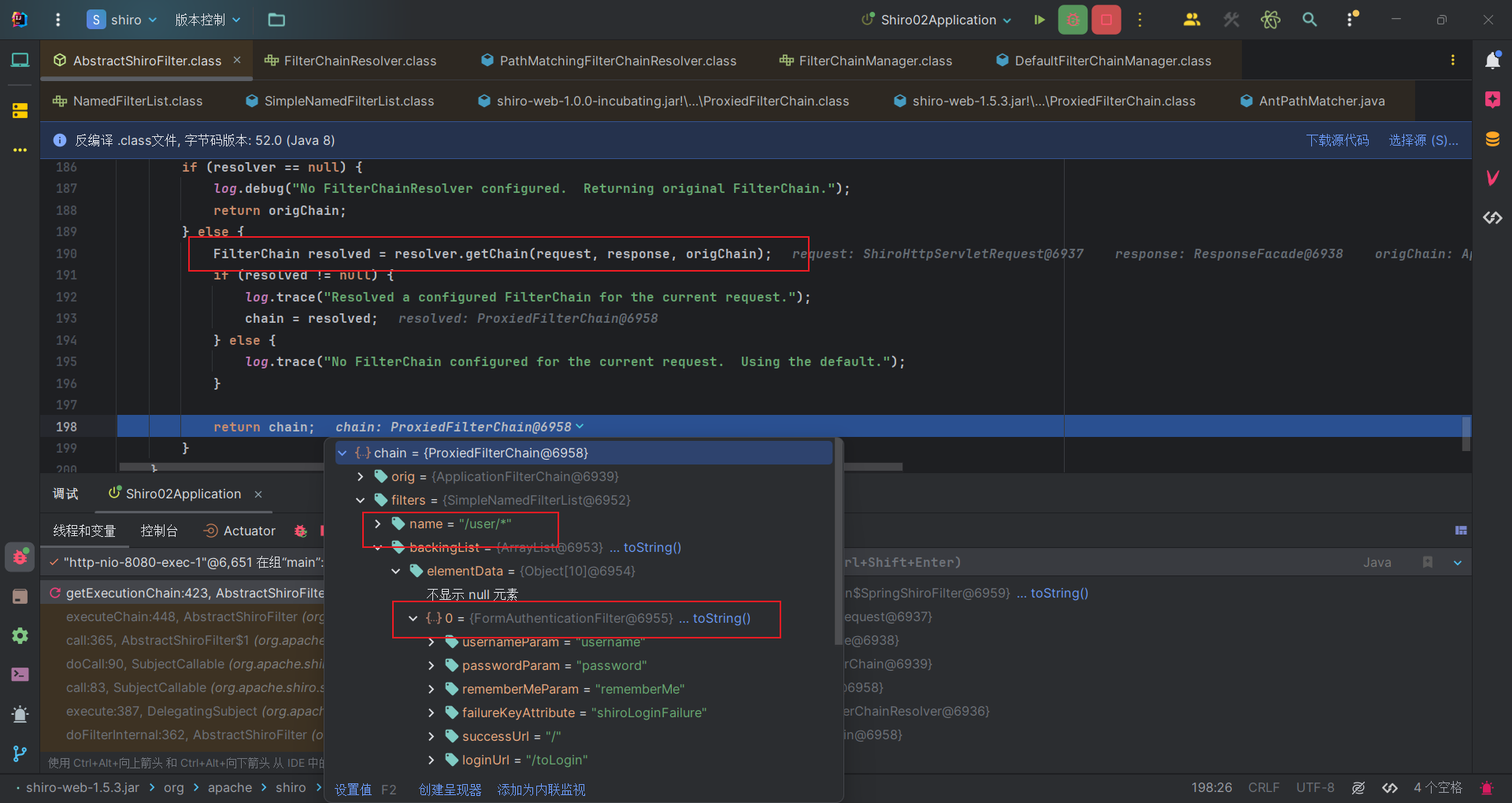
返回后调用其doFiler方法。并在其中调用FormAuthenticationFilter的doFilter方法。此时也是成功调到对应的Shiro过滤器了。
登录流程(个人补充)
在复现CVE-2016-4437(Shiro-550反序列化漏洞)的时候,想了解一下正常登录的流程,于是补充了这里的内容,因此用到的环境也是shiro-spring1.2.4。
经过过滤器过滤之后,请求就会被Springboot的serlvet处理,而我们是登录请求,根据接口就会来到UserController#doLoginPage方法。用user、password、rememberMe创建token后,用org.apache.shiro.subject.support.DelegatingSubject#login方法进行登录处理。可以顺着直接来到org.apache.shiro.mgt.DefaultSecurityManager#login方法。
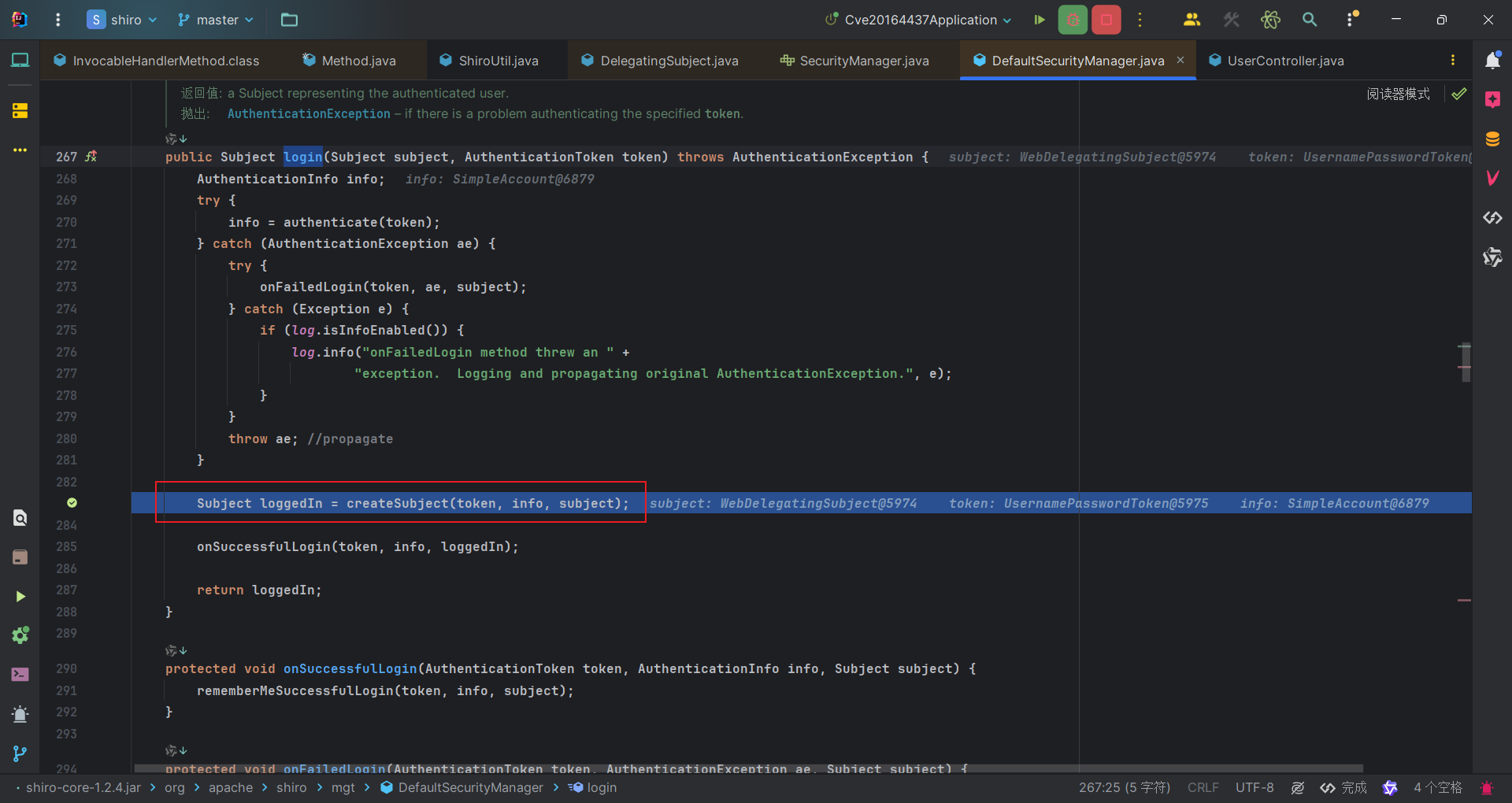
当前的subject只是一个对于http请求的subject,只是用来处理了访问路径权限调用过滤器的。现在就需要用它作为参数,创造一个新的subject,而创造出来的这个新的subject是通过身份验证后创建或更新的,表示一个已认证的用户。
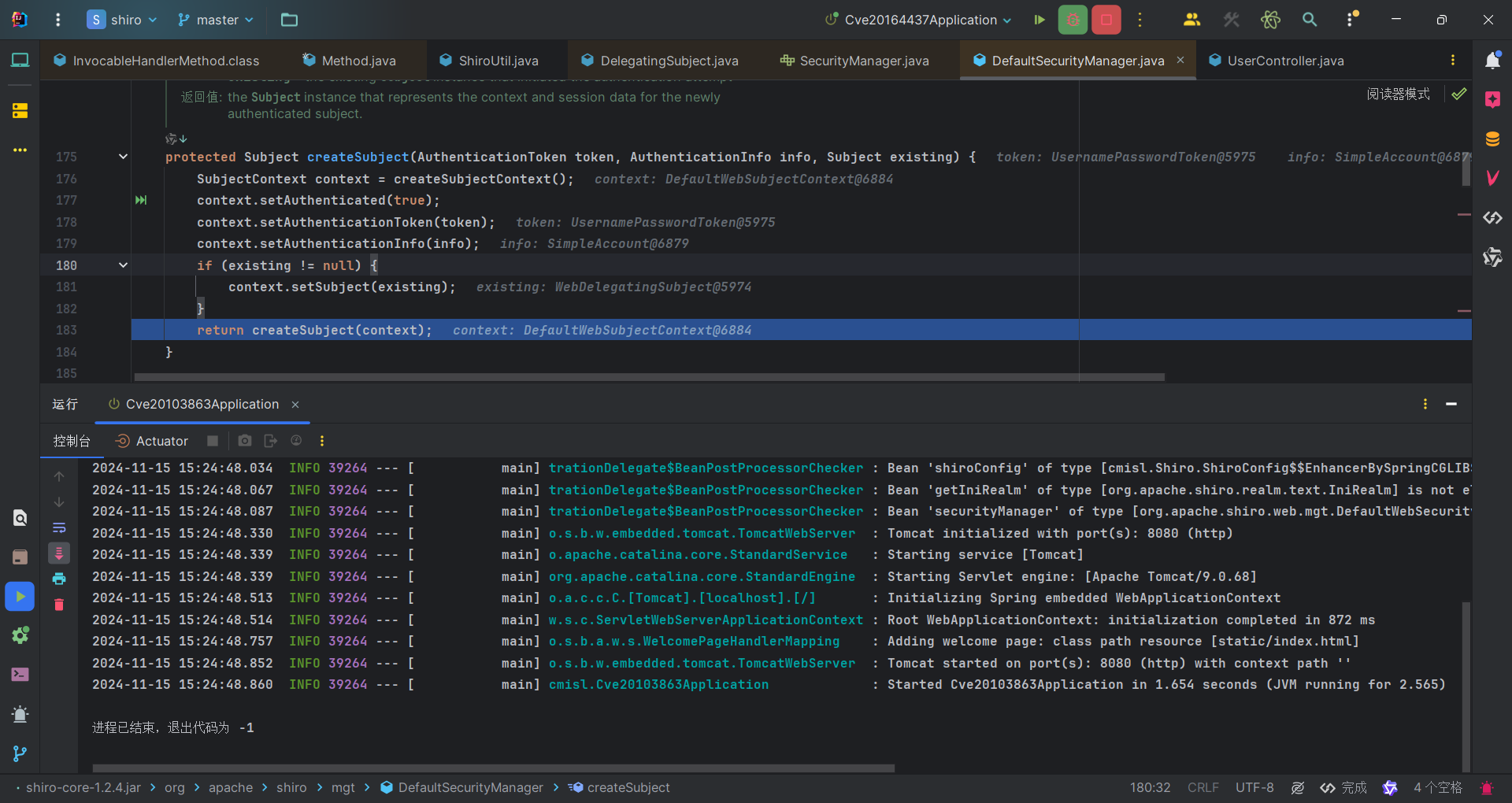
创建一个 SubjectContext,设置了一些认证信息。使用重写的 createSubject 方法根据 SubjectContext 创建并返回一个新的 Subject 对象。又是一顿解析认证信息,我们可以关注一些对Principals的解析,因为Shiro550就是该值的反序列化问题。
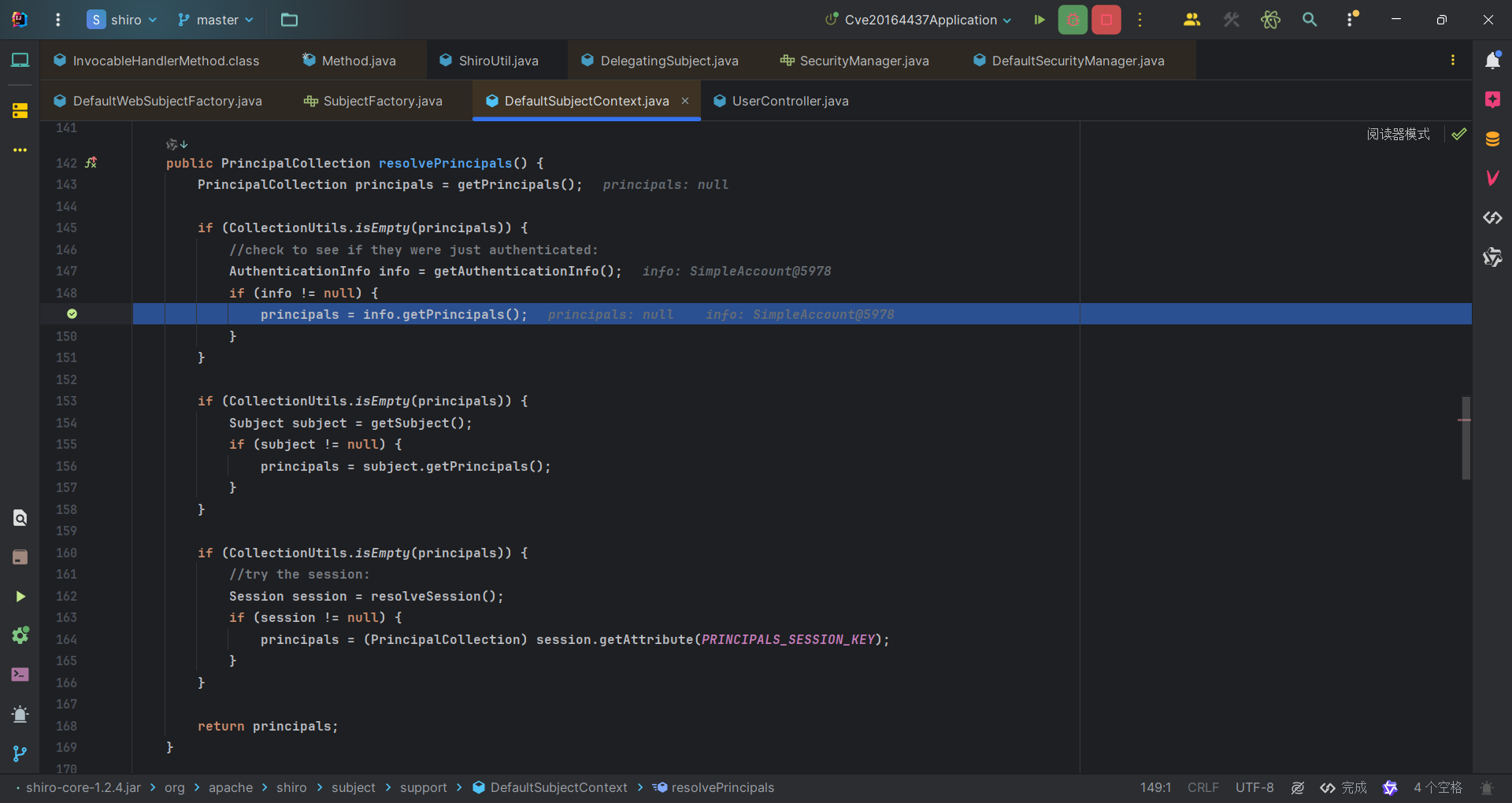
从身份验证信息中提取Principals。后续就是调用org.apache.shiro.web.mgt.DefaultWebSubjectFactory#createSubject,将解析过后的context作为参数,通过再一次解析,new一个subject出来。
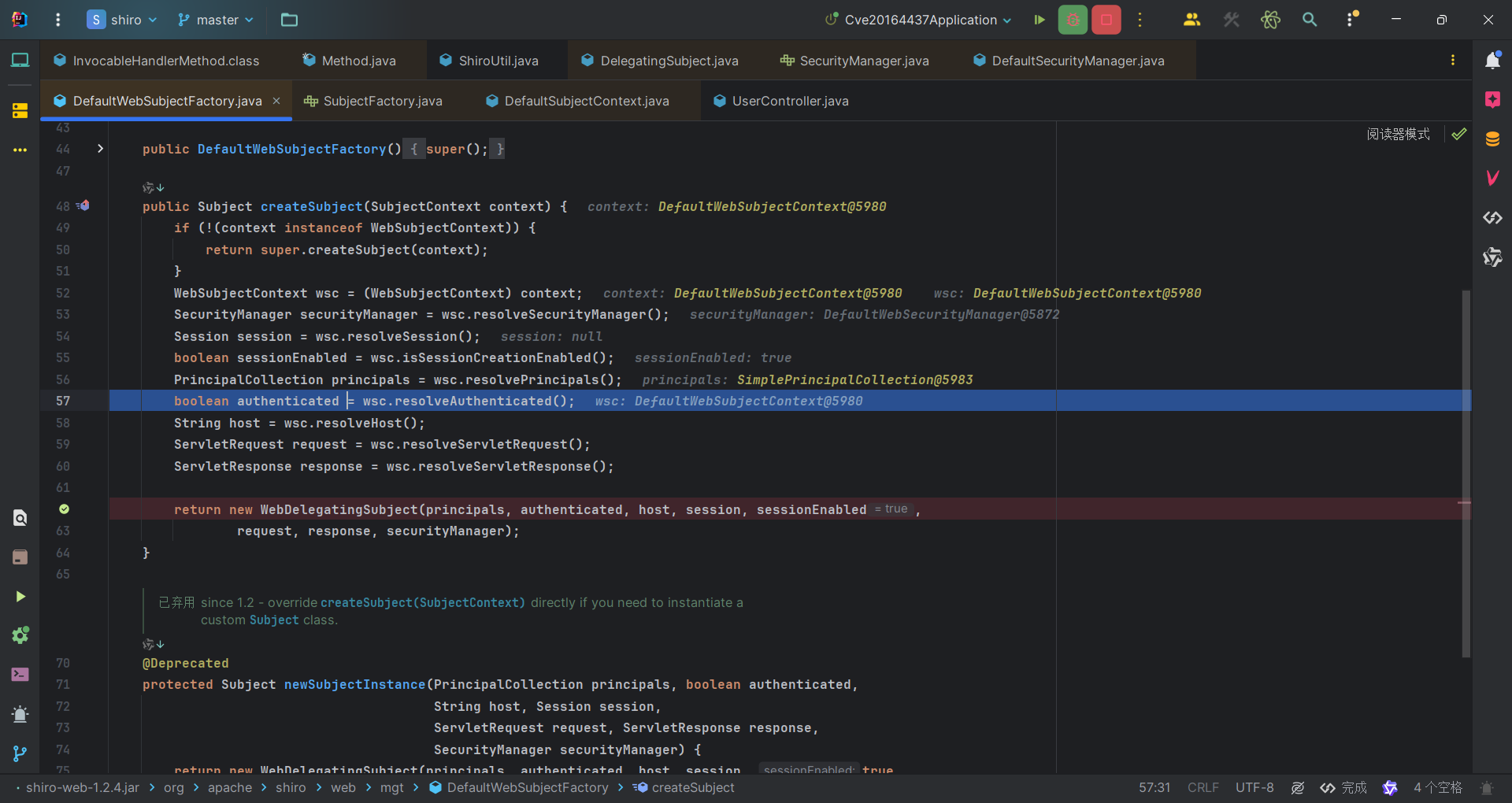
回到org.apache.shiro.mgt.DefaultSecurityManager#login方法,调用onSuccessfulLogin,用于处理登录后的一些操作。我们直接来到关键部分。调用序列化器去序列化Principals。并且将序列化的结果用encrypt方法加密之后再返回。
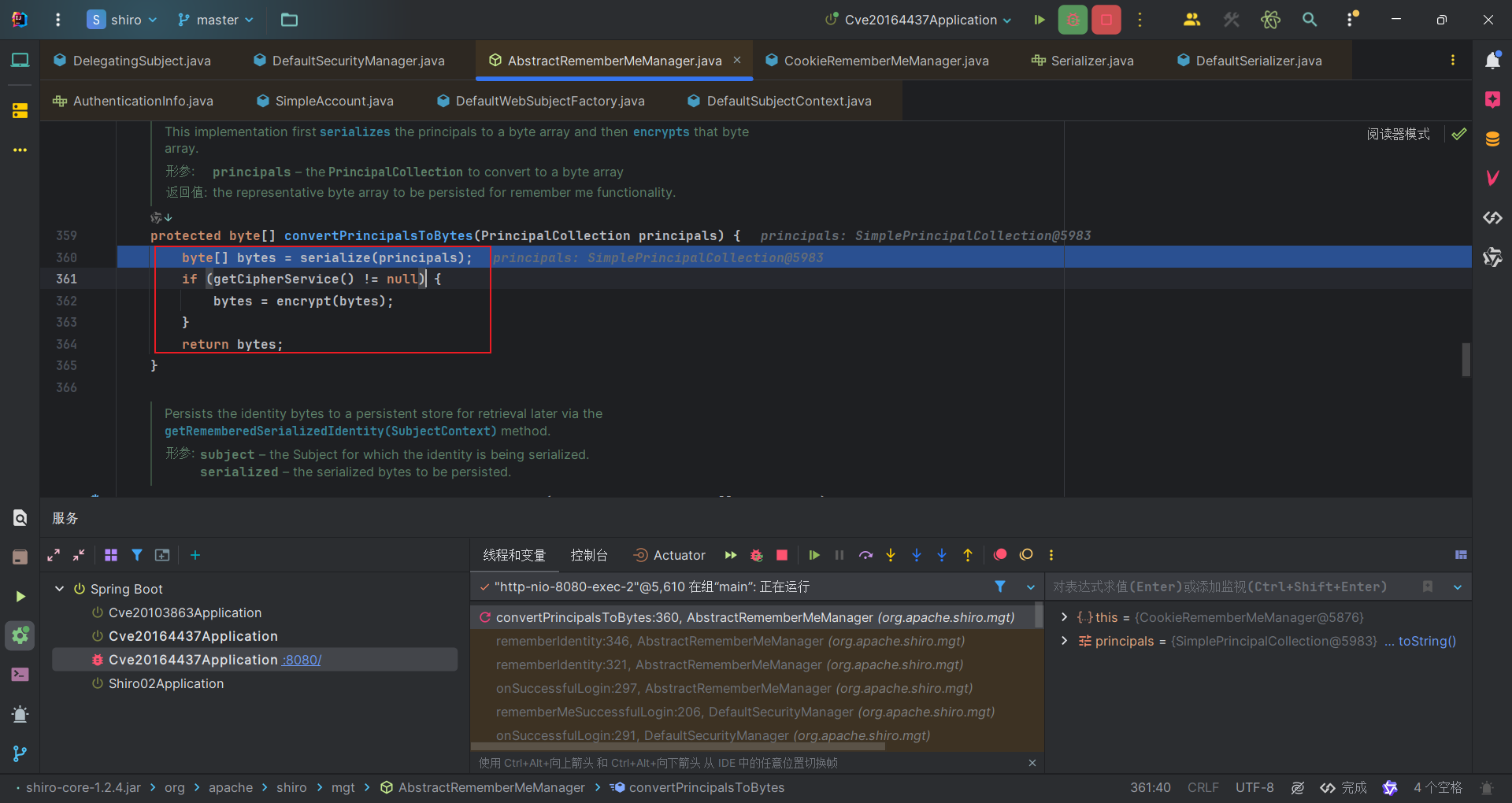
序列化的结果拿去Base64编码然后设置为Cookie。该类时CookieRememberMeManager,初始化的时候cookie的name就是rememberMe。所以赋值的就是赋给了rememberMe。
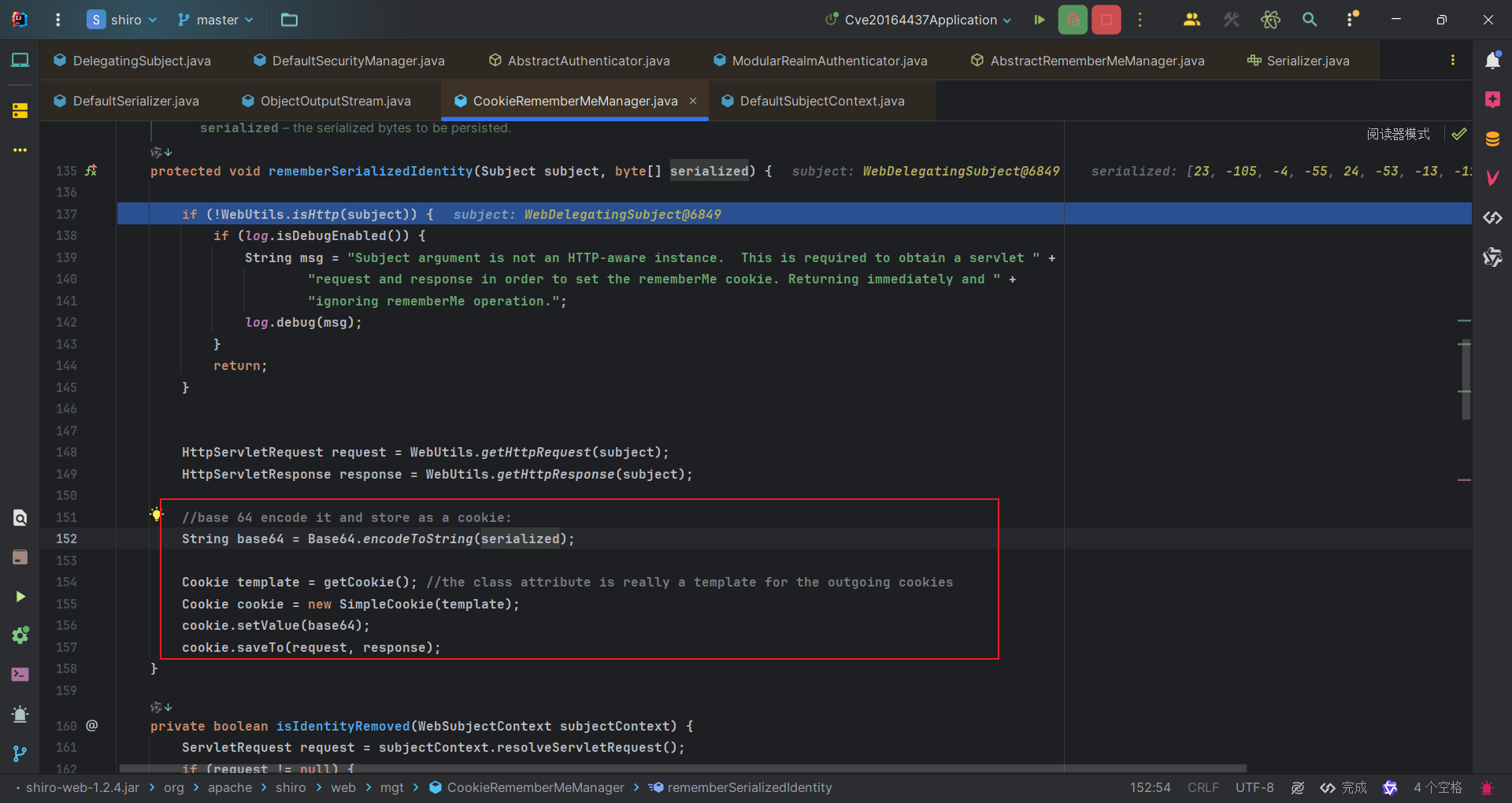
加密的过程中,可以看到我们会用getEncryptionCipherKey()方法获得秘钥,也就是当前类的encryptionCipherKey属性。它是怎么来的呢?
1 | protected byte[] encrypt(byte[] serialized) { |
我从当前类截取了下面部分代码,那么其实就很清楚了。代码会有一个默认的Shiro秘钥,当前类初始化的时候就会通过setCipherKey方法吧加解密秘钥都设置为默认秘钥。
1 | private static final byte[] DEFAULT_CIPHER_KEY_BYTES = Base64.decode("kPH+bIxk5D2deZiIxcaaaA=="); |
Shiro历史漏洞
官网漏洞报告:Security Reports | Apache Shiro
CVE-2010-3863
Apache Shiro before 1.1.0, and JSecurity 0.9.x, does not canonicalize URI paths before comparing them to entries in the shiro.ini file, which allows remote attackers to bypass intended access restrictions via a crafted request, as demonstrated by the /./account/index.jsp URI.
漏洞信息
影响版本:shiro < 1.1.0 和JSecurity 0.9.x
漏洞成因:没有对URI路径进行标准化处理(即未进行规范化),这使得远程攻击者可以通过构造特定的请求来绕过预期的访问限制。
漏洞补丁:https://github.com/apache/shiro/commit/ab8294940a19743583d91f0c7e29b405d197cc34
漏洞环境
先新建一个Springboot模块,导入依赖
1 | <dependency> |
部分代码参考:vulnEnv/CVE-2010-3863(shiro)/ShiroDemo at main · dota-st/vulnEnv
shiro.ini
1 | [users] |
ShiroConfig.java
1 |
|
文件结构
1 | main |
所有的具体代码随后放在github上
漏洞复现
根据我们的配置,我们访问/admin/**和/admin.html都是需要认证admin权限的。当我们访问的时候就会重定向到登录页面,需要我们完成认证,之后再去访问/admin.html才会显示内容。

如果没有认证,我们去访问需要认证的资源/页面,就会出现302跳转让我们去登录。
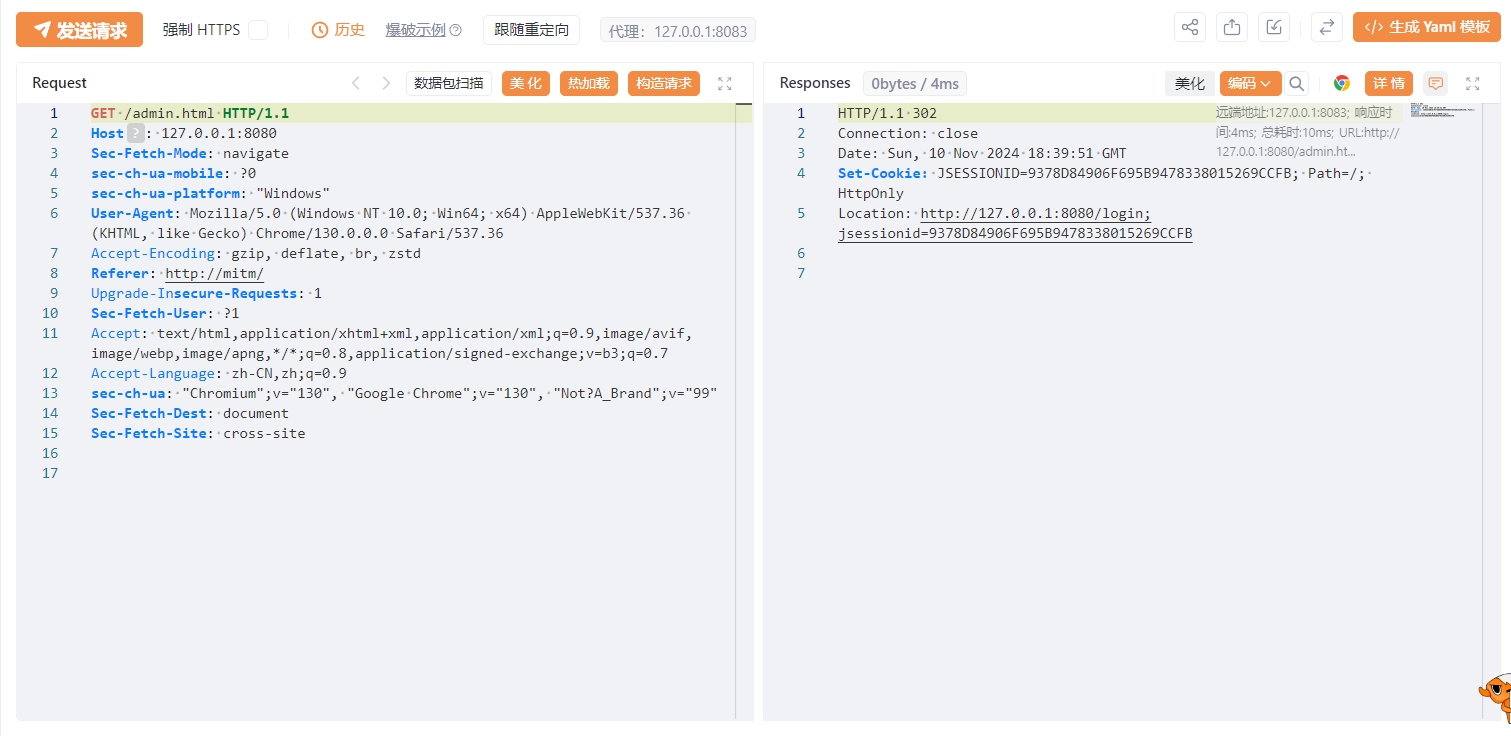
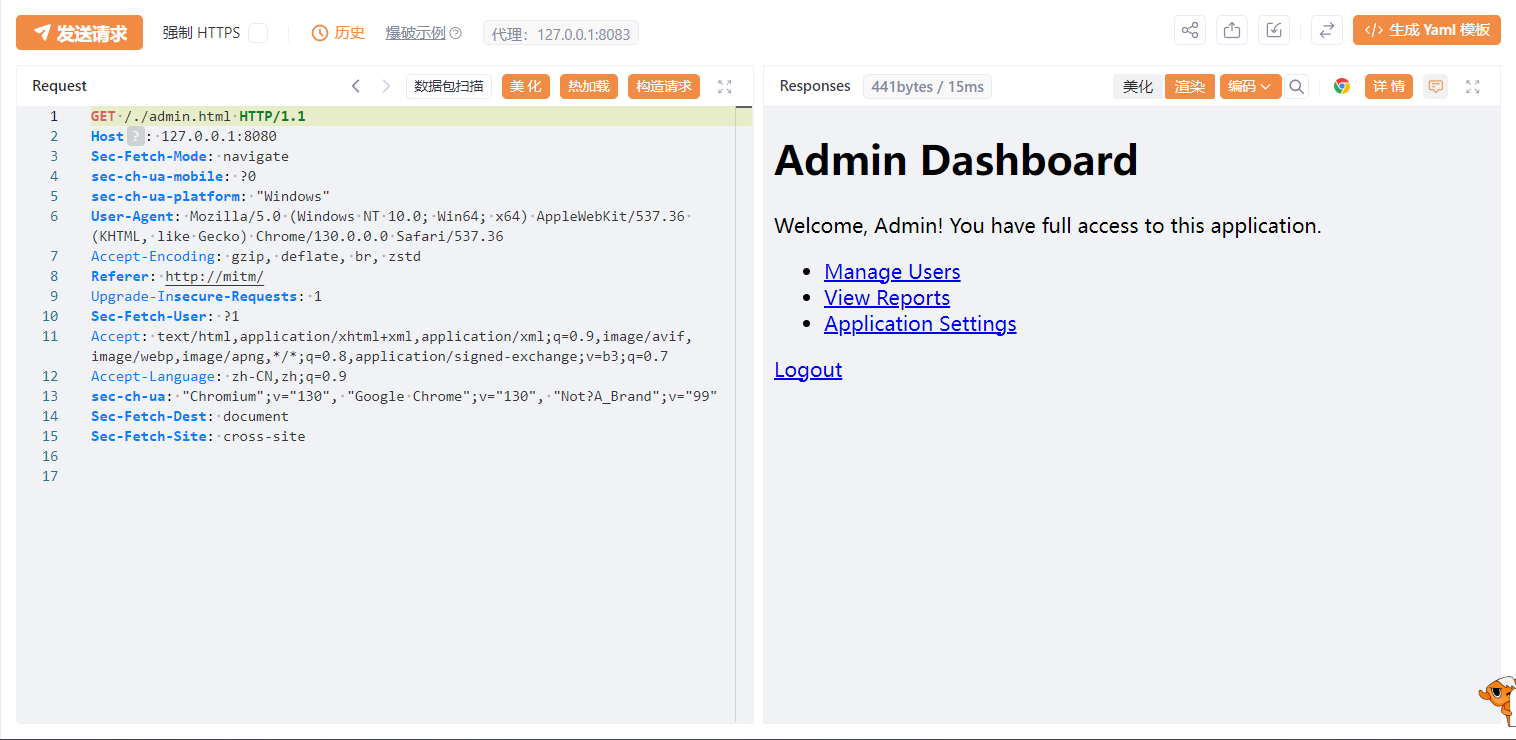
而根据该漏洞POC,我们将/admin.html改为/./admin.html即可访问到资源。
漏洞分析
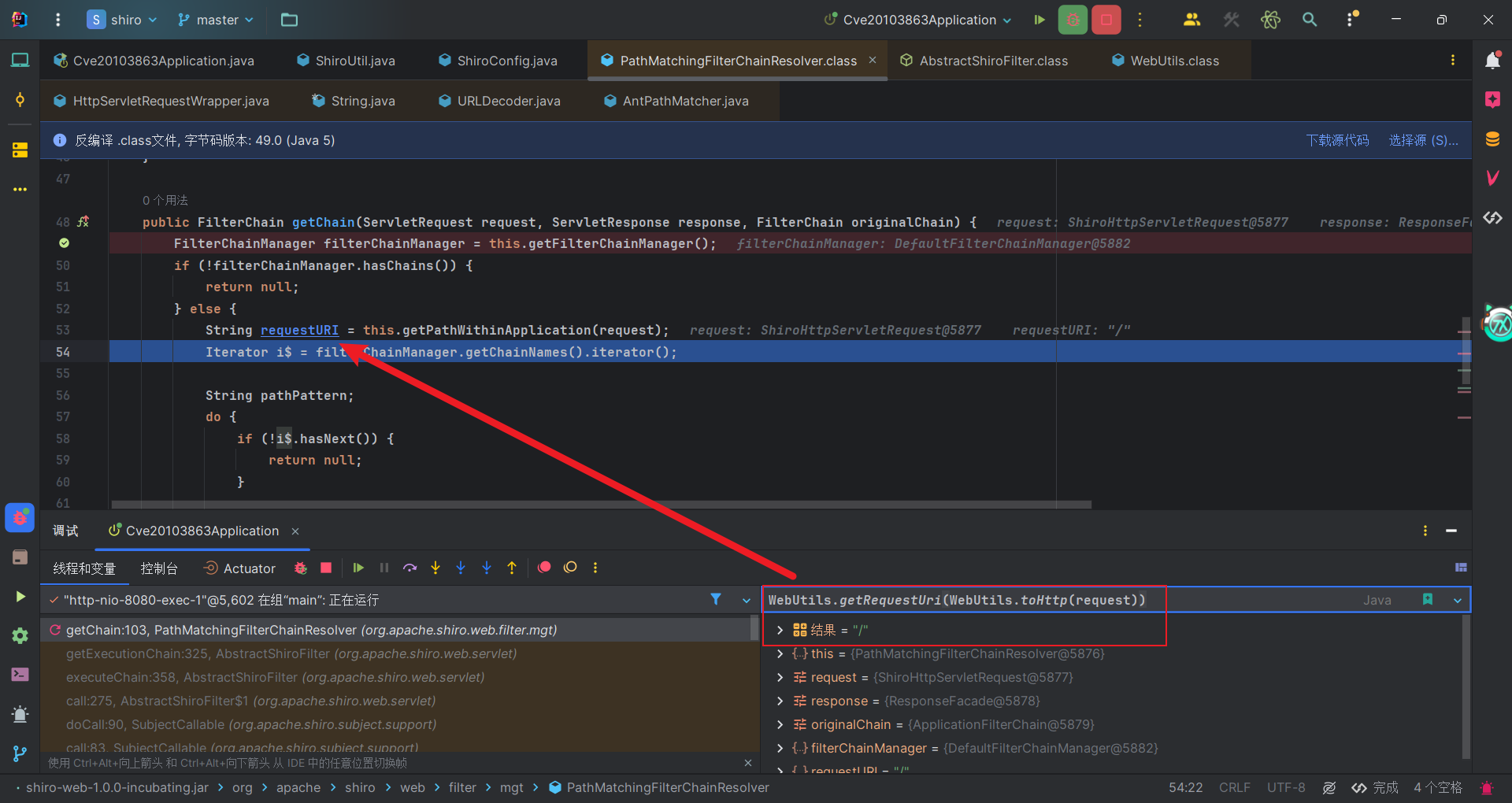
从上面的分析可以知道,通过匹配url确定过滤器,上面的poc很显然试试通过url绕过匹配,从而跳过过滤器的过滤。url的匹配开始于org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain方法。可以直接打上断点。
首先把请求作为参数调用PathMatchingFilterChainResolver#getPathWithinApplication方法获取请求url。其中涉及的调用堆栈如下:
1 | decode:168, URLDecoder (java.net) |
其中我比较关注的方法如下:
1 | protected String getPathWithinApplication(ServletRequest request) { |
我省略了一些代码,详细代码可以自己跟进对应的方法。上面的一系列方法中,可以看到,我们会先用URLDecoder#decode解码。比如如果遇到了+号,就会替换为空格,还有百分号%,会进行URL解码。然后到decodeAndCleanUriString方法,uri.indexOf(59)代码会去获取该url中ascii码为59对应符号的索引,然后只返回分号;前面的url。
所以其实分析到这里,我们似乎可以用另一个方式绕过,比如访问/;/admin.html,只要分号在tomcat服务器的代码中不被影响,就会获取到/路径,从而匹配到的是anon对应的过滤器,即匿名访问过滤器AnonymousFilter,可以直接访问需要Shiro鉴权认证的资源和路径了。
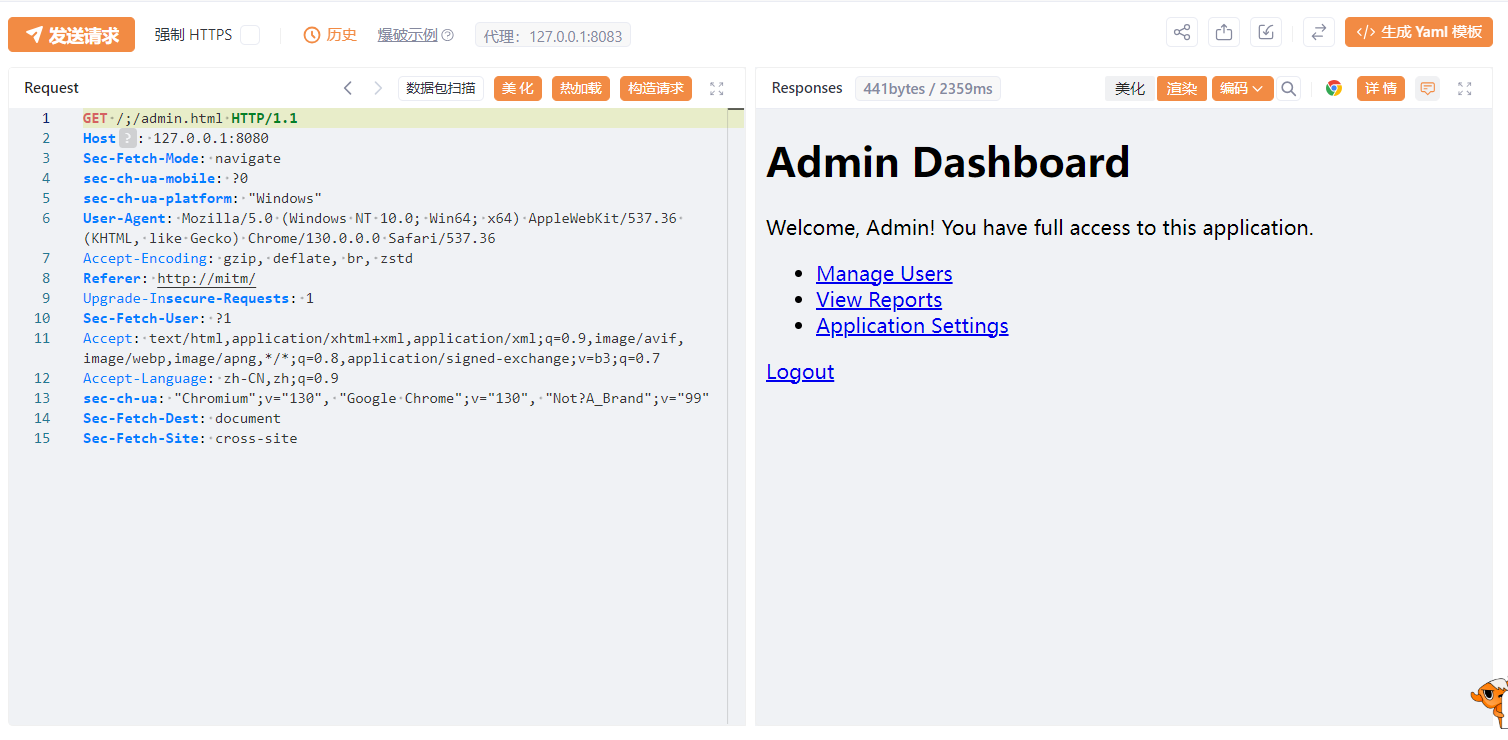
我们再来继续关注/./admin.html。这个url会被完整提取,主要在AntPathMatcher#doMatch进行详细匹配,具体调用堆栈如下:
1 | doMatch:112, AntPathMatcher (org.apache.shiro.util) |
1 | protected boolean doMatch(String pattern, String path, boolean fullMatch) { |
首先会根据/符号分解URL为数组,/admin.html分解为[admin.html],/./admin.html分解为[".", "admin.html"]。然后会去比较分解出来的数组,匹配所有元素直到第一个 **,然后这两个数组,第一个元素就不相等,因此直接返回false。代表匹配失败,所以,不会匹配上/admin.html对应的Shiro过滤器。从而使得Shiro设置的权限检查失效。
漏洞修复
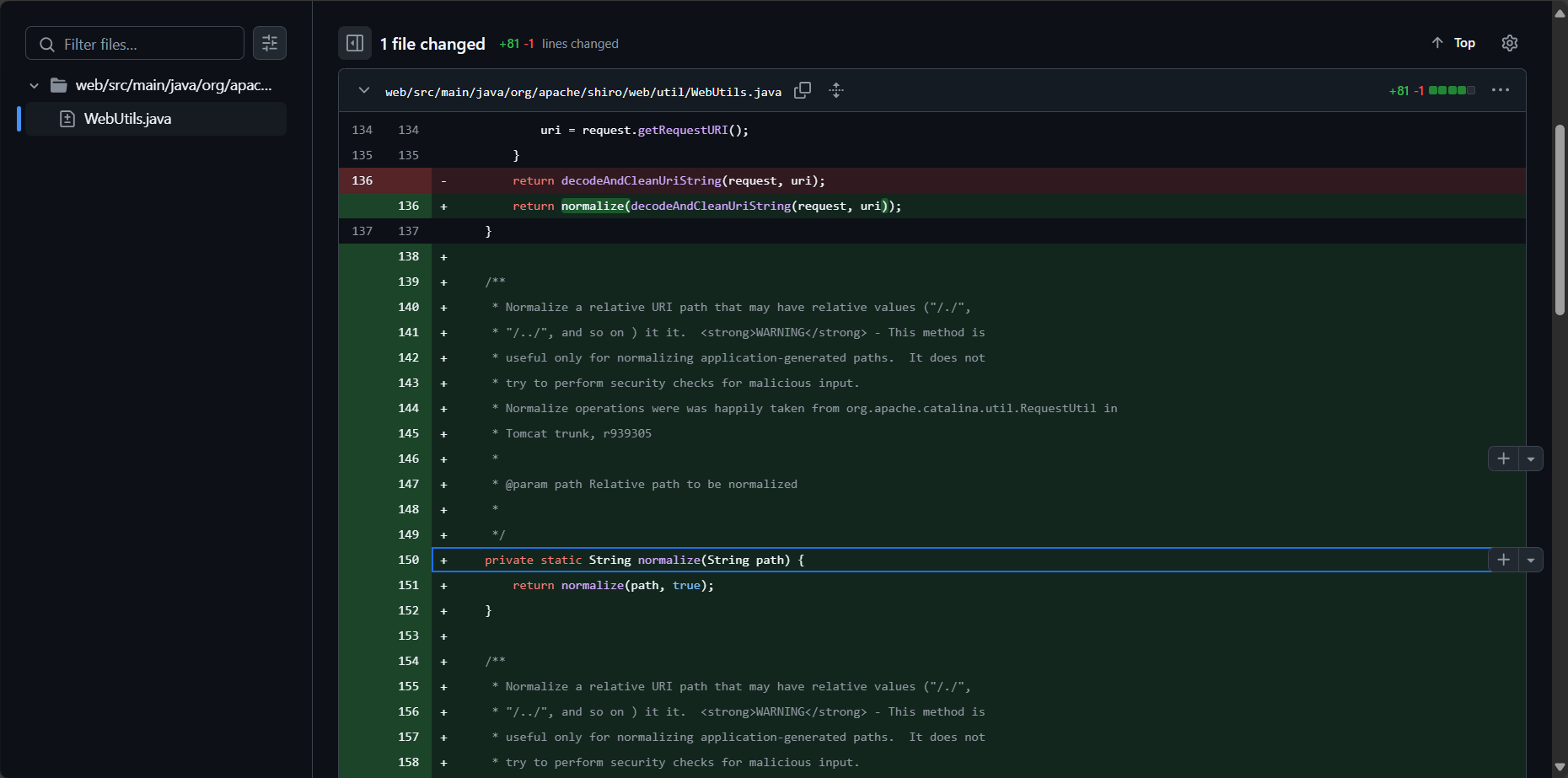
Normalize requestURI in getRequestURI using normalize() operations or… · apache/shiro@ab82949
删除了decodeAndCleanUriString方法替换为normalize方法,根据注释很容易理解该方法用于规范化可能包含相对值(如 “/./”“/../” 等)的相对 URI 路径。同时因为没有了decodeAndCleanUriString方法,所有/;/admin.html也不行了,因为取分号前面路径的处理操作在decodeAndCleanUriString方法中。
参考链接
CVE-2016-4437(Shiro-550反序列化漏洞)
Apache Shiro before 1.2.5, when a cipher key has not been configured for the “remember me” feature, allows remote attackers to execute arbitrary code or bypass intended access restrictions via an unspecified request parameter.
漏洞信息
影响版本:shiro 1.x < 1.2.5
漏洞成因:密钥被硬编码在shiro组件中,如果秘钥泄露或者被爆破出来,将会导致rememberMe参数反序列化漏洞。
漏洞补丁:Force RememberMe cipher to be set to survive JVM restart. · apache/shiro@4d5bb00
漏洞环境
1 | <dependency> |
前置知识
漏洞描述提到该漏洞与RememberMe配置有关,那么我们这里补充一些该部分的知识。
RememberMe 允许用户在下次访问时无需再次登录。它通过在用户的设备上存储一个持久化的标识符(通常是一个 cookie)来实现。这个标识符可以在再次访问时用于自动登录。
我们全局搜索RememberMe,找到与其相关的类如下:
RememberMeManager
这个类(org.apache.shiro.mgt.RememberMeManager)是一个用于管理用户身份记住(Remember Me)功能的接口。下面是该接口提供的方法:
- 获取记住的身份:
getRememberedPrincipals(SubjectContext subjectContext):根据提供的主题上下文,返回先前记住的用户身份。如果没有记住的身份,则返回null。
- 遗忘身份:
forgetIdentity(SubjectContext subjectContext):根据提供的主题上下文,遗忘与该上下文对应的用户身份信息。
- 处理成功的身份验证:
onSuccessfulLogin(Subject subject, AuthenticationToken token, AuthenticationInfo info):在用户成功登录后,调用该方法以保存用户的身份信息。
- 处理失败的身份验证:
onFailedLogin(Subject subject, AuthenticationToken token, AuthenticationException ae):在用户登录失败时,调用该方法以忘记先前记住的身份信息。
- 处理登出:
onLogout(Subject subject):在用户登出时调用该方法,忘记与用户相关的身份信息。
AbstractRememberMeManager
org.apache.shiro.mgt.AbstractRememberMeManager 接口是 RememberMeManager 接口的一个抽象实现。它提供了一些字段和方法,以便于记住用户身份(“RememberMe”)功能的实现。以下是该类的关键的功能及其结构的介绍:
主要字段
DEFAULT_CIPHER_KEY_BYTES是一个默认的 Base64 编码 AES 密钥。也就是漏洞描述中提到的密钥。serializer:Shiro 的序列化器,用于将 PrincipalCollection 实例转换为/转换为字节数组的序列器。默认情况下,它使用DefaultSerializer,但可以通过setSerializer方法提供自定义序列化器。
关键方法
rememberIdentity: 记住指定的身份信息。getRememberedPrincipals: 根据上下文检索已记住的身份信息。forgetIdentity: 从持久存储中删除身份信息。isRememberMe: 检查身份验证令牌是否请求“记住我”功能。
CookieRememberMeManager
org.apache.shiro.web.mgt.CookieRememberMeManager 是AbstractRememberMeManager的实现类, 通过将用户的身份信息(Subject 的 getPrincipals() 返回的结果)序列化并存储在一个 Cookie 中来实现“记住我”功能。下次用户访问时,可以从 Cookie 中恢复用户身份。
相关方法
rememberSerializedIdentity(Subject subject, byte[] serialized):- 该方法将序列化的用户身份信息(字节数组)进行 Base64 编码后,设置为 Cookie 的值。它首先检查给定的
Subject是否是 HTTP-aware 的实例(即是否具有 HTTP 请求和响应),然后通过 HTTP 响应将 Cookie 设置为包含编码后的身份信息。
- 该方法将序列化的用户身份信息(字节数组)进行 Base64 编码后,设置为 Cookie 的值。它首先检查给定的
getRememberedSerializedIdentity(SubjectContext subjectContext):- 该方法从 HTTP Cookie 中获取之前存储的身份信息,进行 Base64 解码并返回字节数组。
漏洞复现
这个漏洞不需要正确的账号密码,也不需要登录,但是为了获取需要的数据包,我们先要来正确登录一下。记得勾选Remember me选项。
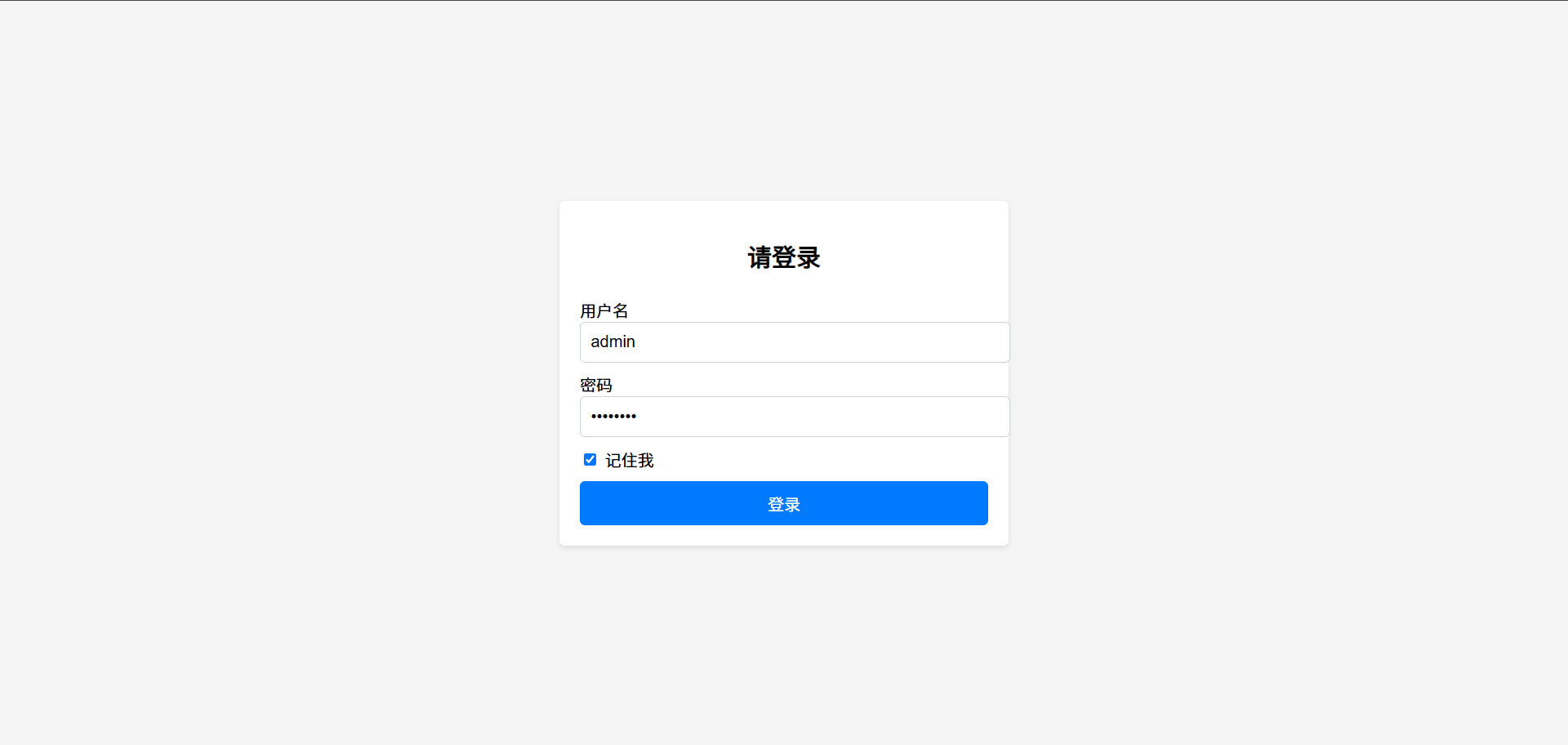
登录之后,我们的返回包是一个302跳转,会让我们跳转到登录成功的页面去,同时会设置Cookie,分别设置了JSESSIONID和rememberMe参数。
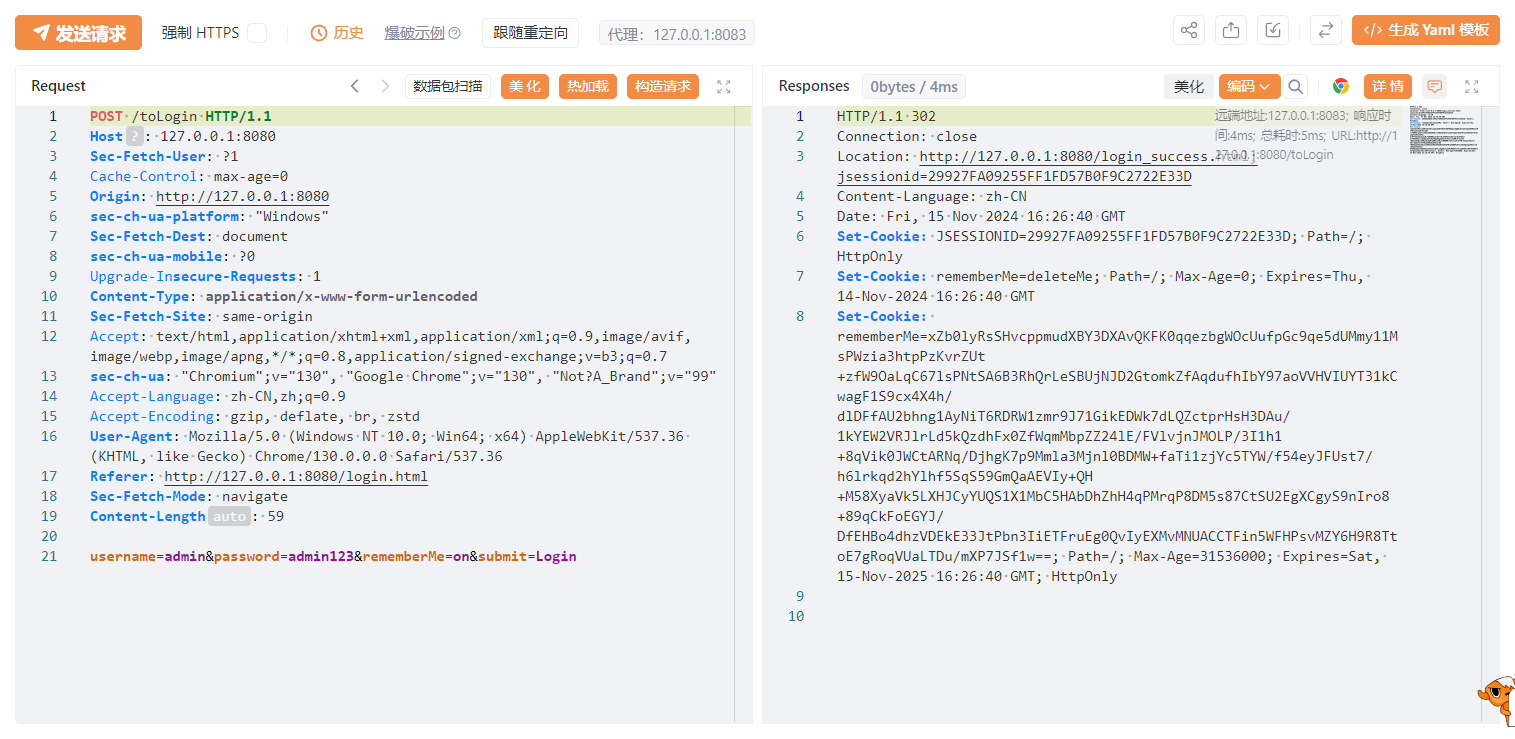
我们再访问登录页面,数据包如下,可以看到是携带Cookie的,这个数据包就是我们需要的,我们可以通过Shiro默认秘钥构造恶意编码,触发反序列化漏洞执行命令。
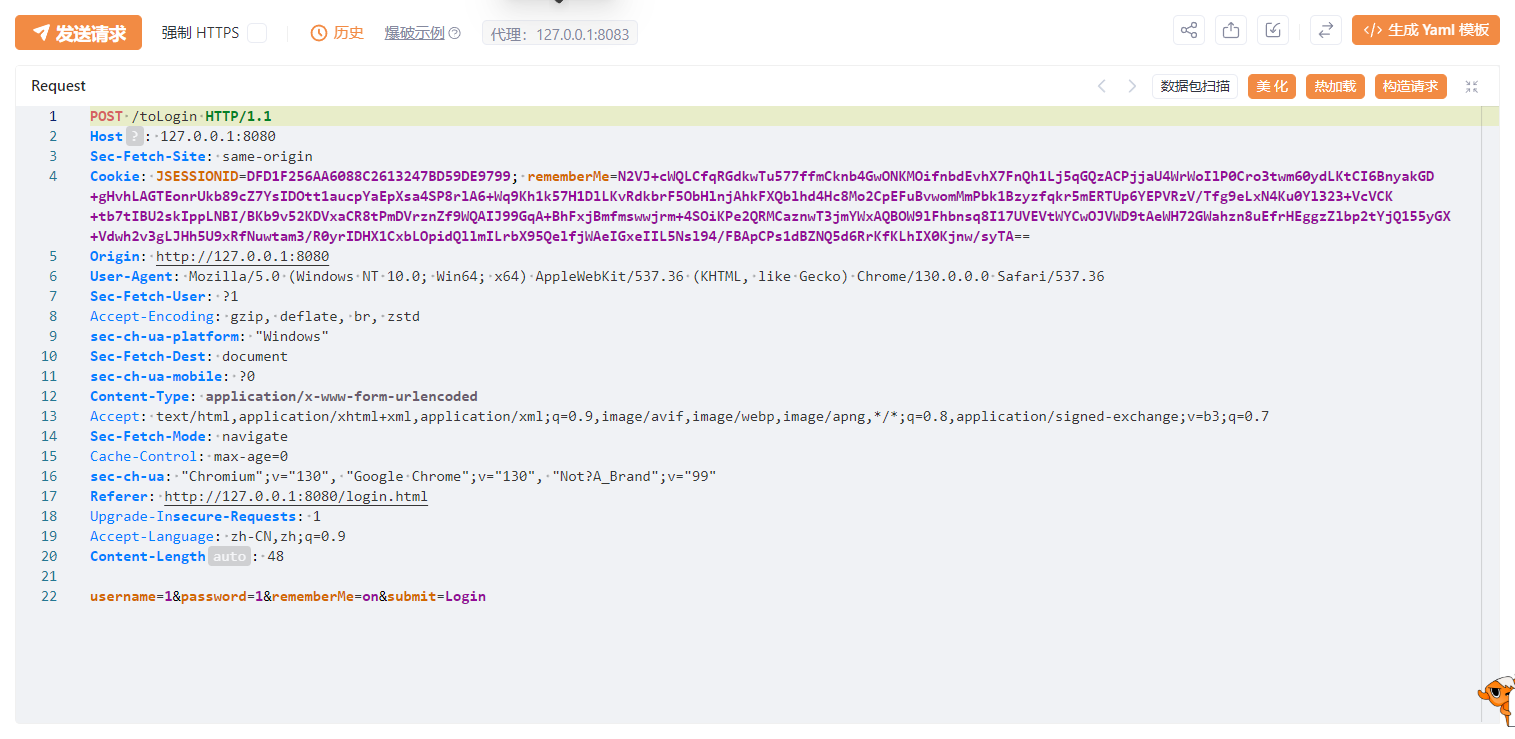
那么我们现在重启Springboot,清理缓存,重新发送该数据包。
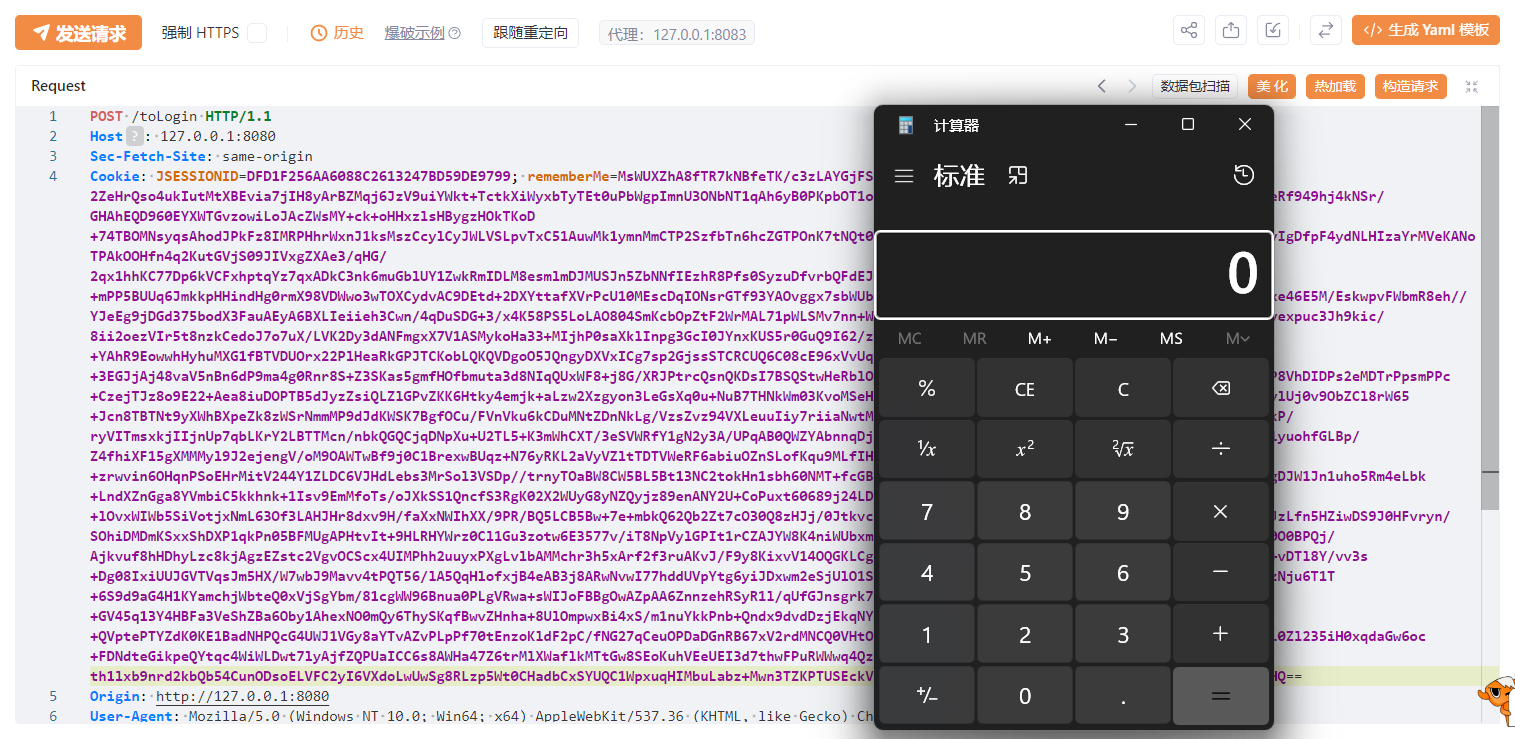
成功执行,并且无需正确的账号密码,只需要秘钥,构造恶意rememberMe值即可。
漏洞分析
我们要注意的是每一次发起请求的时候,都会来到org.apache.shiro.web.servlet#doFilterInternal,在前面的分析中很容易知道,而这个方法中会根据当前请求去创建一个subject,我们当时注意的是下面的代码,而现在我们关注的是createSubject方法。
1 | protected void doFilterInternal(ServletRequest servletRequest, ServletResponse servletResponse, final FilterChain chain) |
顺着方法调用来到org.apache.shiro.mgt.DefaultSecurityManager#createSubject,会调用resolvePrincipals方法从subjectContext中解析出Principals。
1 | public Subject createSubject(SubjectContext subjectContext) { |
可以看到首先从上下文获取principals,但是我们当前的context是新new出来的,只设置了securityManager和request、respone。所以获取的结果为null,所以调用getRememberedIdentity方法,获取CookieRememberMeManager,并调用其getRememberedPrincipals方法去获取principals。可以跟进去看看。
1 | protected SubjectContext resolvePrincipals(SubjectContext context) { |
直接跟进,然后再跟进到org.apache.shiro.mgt.CookieRememberMeManager#getRememberedSerializedIdentity。这个方法会从Http请求和响应中获取Cookie中的rememberMe值。也就是我们构造的恶意编码。然后进行解码,将得到的数据返回。这时候解码出来的数据还是加密的。接着会把得到的数据用org.apache.shiro.mgt.AbstractRememberMeManager#convertBytesToPrincipals进行最后的处理。
1 | protected byte[] getRememberedSerializedIdentity(SubjectContext subjectContext) { |
可以看到先解密,然后将解密的序列化数据进行反序列化。
1 | protected PrincipalCollection convertBytesToPrincipals(byte[] bytes, SubjectContext subjectContext) { |
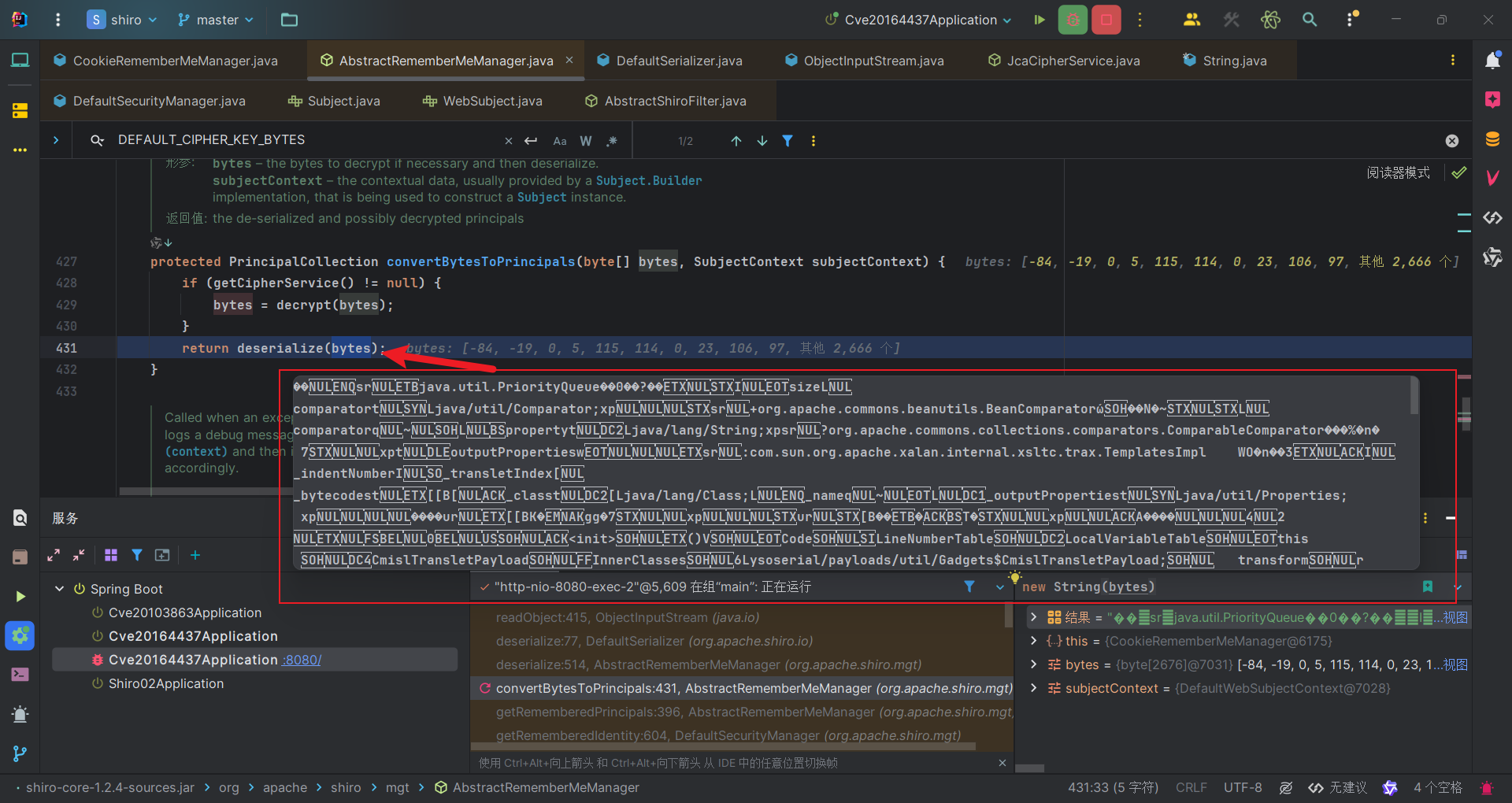
部分调用堆栈:
1 | readObject:415, ObjectInputStream (java.io) |
一些问题
我们环境为什么导入CC依赖?
如果不导入的话,我们使用原来的POC会有如下异常:
1 | Caused by: org.apache.shiro.util.UnknownClassException: Unable to load class named [org.apache.commons.collections.comparators.ComparableComparator] from the thread context, current, or system/application ClassLoaders. All heuristics have been exhausted. Class could not be found. |
意思是ComparableComparator这个类没有找到。可以看到BeanComparator类的构造函数里,如果没有指定comparator就会用CC依赖库里面的ComparableComparator。
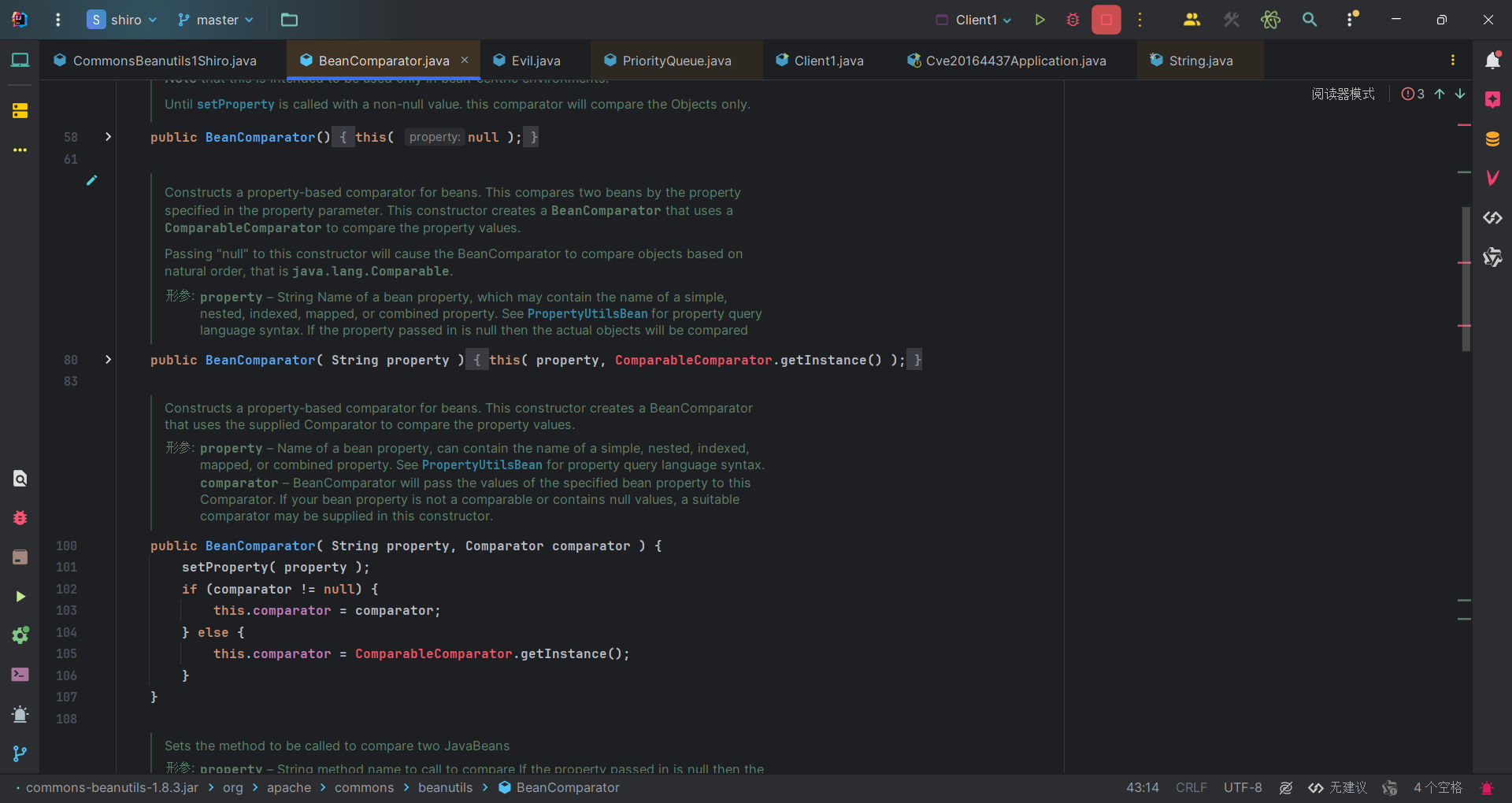
commons-collections的 <optional> 标签被设置为 true,表示这是个可选依赖。
可选依赖通常表示该依赖不是项目运行的必需部分,而是提供额外的功能或增强。如果使用者希望使用这些可选功能,他们可以在自己的项目中显式地声明该依赖。如果不声明,项目仍然可以正常运行而不会因为缺少可选依赖而出错。
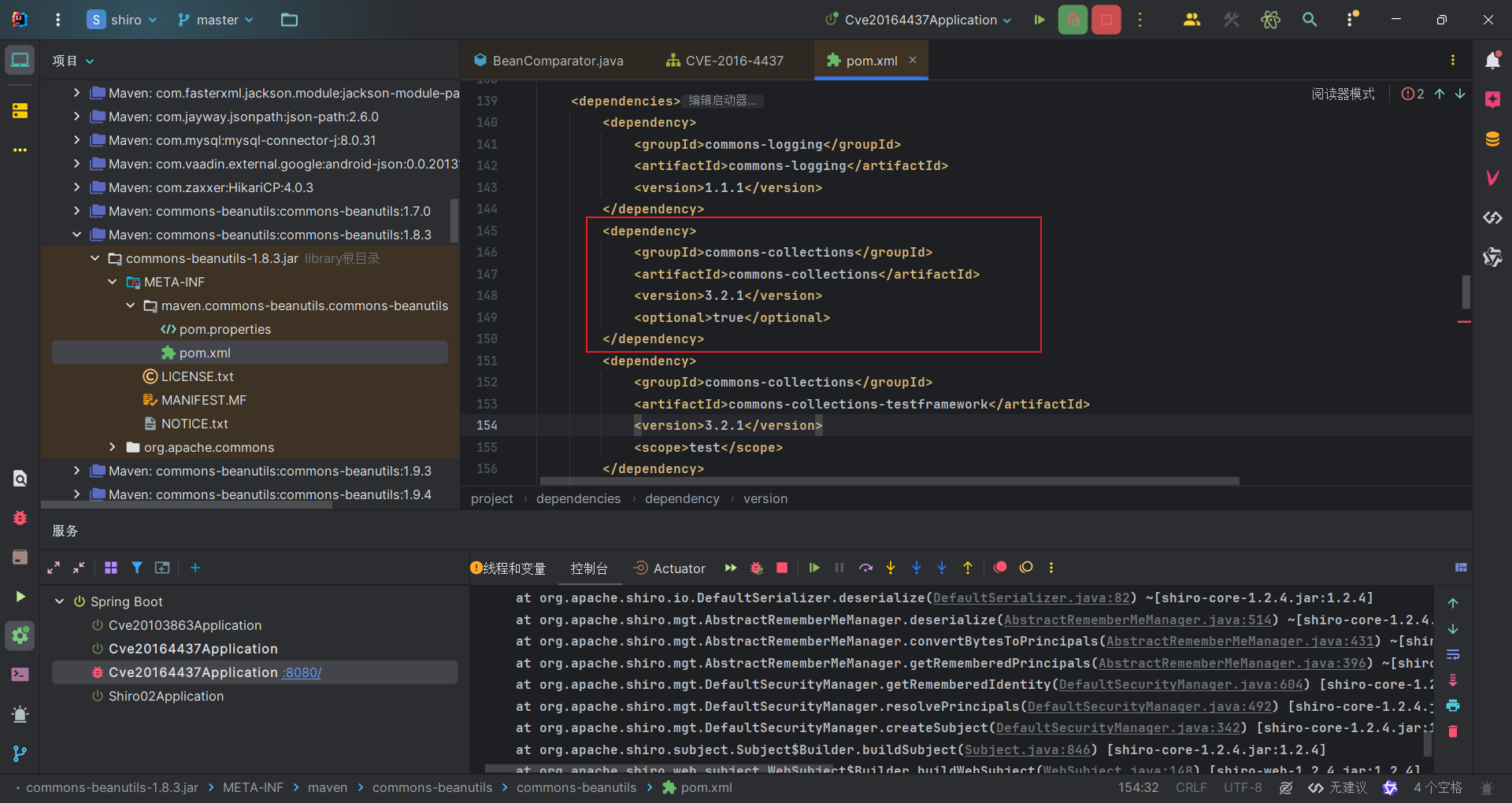
既然如此我们就去指定一个java原生库或者CB依赖里面的comparator,这个Comparator满足下面条件:
- 实现 java.util.Comparator 接口
- 实现 java.io.Serializable 接口
- Java、shiro或commons-beanutils自带,且兼容性强
可以找到CaseInsensitiveComparator类,并且java内部核心类String.java中存在一个该类的静态变量。
生成序列化数据poc,加密可以找个AES加密脚本或者直接用java的库函数。
1 | public class CB1_Shiro { |
漏洞修复
Force RememberMe cipher to be set to survive JVM restart. · apache/shiro@4d5bb00
删掉了默认的静态秘钥,改用AesCipherService#generateNewKey生成秘钥。

参考链接
Shiro安全(三):Shiro自身利用链之CommonsBeanutils_shiro利用链-CSDN博客
shiro-web CVE-2016-4437 - FreeBuf网络安全行业门户
CVE-2016-6802
Apache Shiro before 1.3.2 allows attackers to bypass intended servlet filters and gain access by leveraging use of a non-root servlet context path.
漏洞信息
影响版本:shiro < 1.3.2
漏洞成因:Shiro未对ContextPath做路径标准化导致权限绕过
漏洞补丁:Added fix to adjust how the servlet context path is handled · apache/shiro@b15ab92
漏洞环境
该漏洞需要用到Java Servlet 应用程序环境,依赖如下:
1 | <dependencies> |
具体配置可以参考我的github,改自p神的shirodemo。
项目结构树:
1 | src |
打包

使用Tomcat启动即可,需要设置应用程序根路径,我们设置的是/CVE_2016_6802_war_exploded

漏洞复现
我们尝试访问需要鉴权的页面index.jsp,会302跳转到登录页面让我们登录对应权限。

我们使用漏洞poc发送请求,也就是在请求url前面加上/xxx/..(xxx随意填写),可以看到我们没有权限却可以访问需要权限的页面。

漏洞分析
漏洞核心位置是一个很熟悉的地方,org.apache.shiro.web.util.WebUtils#getPathWithinApplication:

该函数用于获取请求路径在应用内的相对路径:
- 获取请求的上下文路径(
contextPath)和请求URI(requestUri)。 - 检查
requestUri是否以contextPath开头:- 如果是,则去掉
contextPath部分,返回剩余路径;如果没有剩余路径,则返回/。 - 如果不是,则直接返回
requestUri。
- 如果是,则去掉
可以看到按照POC发送url请求,上下文路径contextPath是/cmisl/../CVE_2016_6802_war_exploded,请求 URI requestUri是/CVE_2016_6802_war_exploded/index.jsp,显然requestUri并不是以contextPath开头,因此进入else直接返回requestUri,也就是直接返回了/CVE_2016_6802_war_exploded/index.jsp。
一直返回到org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain。

可以看到我们过滤器匹配的路径是/index.jsp,与返回来的/CVE_2016_6802_war_exploded/index.jsp匹配不上,所以这次请求不会经过权限检查的过滤器。所以可以访问到原本需要权限的资源。
contextPath问题
那么为什么上下文路径contextPath是/cmisl/../CVE_2016_6802_war_exploded呢?
这里主要就是tomcat代码的问题了。我们可以跟进获取contextPath的方法getContextPath。一直跟进到org.apache.catalina.connector.Request#getContextPath

因为我们设置Tomcat服务器时,设置的应用程序根路径是/CVE_2016_6802_war_exploded,所以lastSlash(代表斜杠数目)的值为1。
然后会经过多重斜杠检查,我们可以跳过直接看造成漏洞的关键部分。

首先匹配canonicalContextPath和candidate,也就是匹配程序根路径/CVE_2016_6802_war_exploded和取出来第一个斜杠所对应的路径/cmisl。
发现匹配不上,于是会加上第二个斜杠所对应的路径,也就是/cmisl/..,匹配之前规范化,变成/。
发现/和/CVE_2016_6802_war_exploded匹配不上。在加上第三个斜杠对应的路径,/cmisl/../CVE_2016_6802_war_exploded,匹配前规范化变成/CVE_2016_6802_war_exploded。
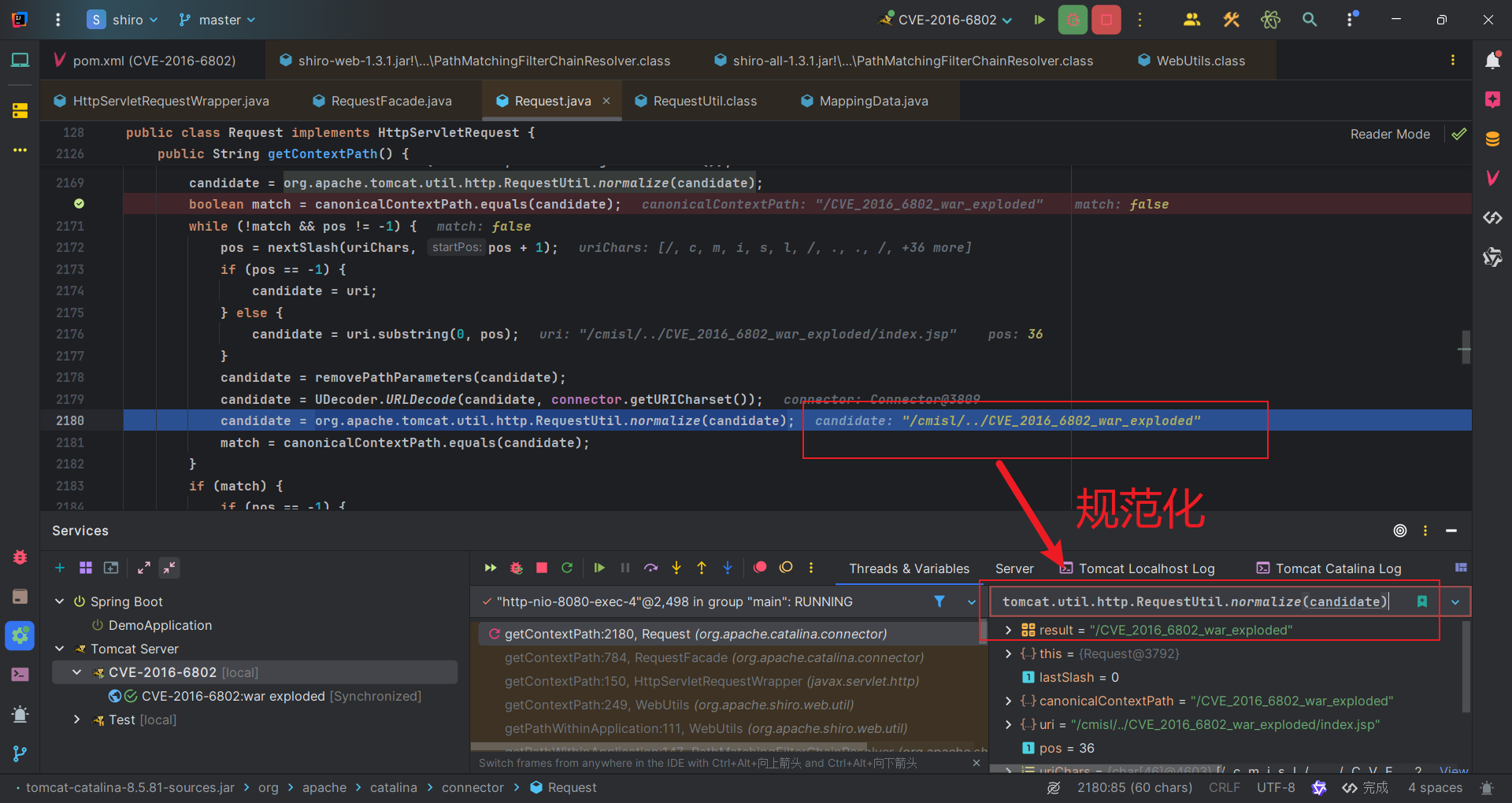
此时规范化后的路径/CVE_2016_6802_war_exploded就和程序根路径/CVE_2016_6802_war_exploded匹配上了。
匹配上之后,就会返回从开始到第三个斜杠对应的路径,额就是/cmisl/../CVE_2016_6802_war_exploded,返回这个作为上下文路径contextPath。
另一种绕过
参考:Java Shiro 权限绕过多漏洞分析 | Drunkbaby’s Blog

可以看到/;/CVE_2016_6802_war_exploded经过removePathParameters函数之后变成//CVE_2016_6802_war_exploded,这个在后面规范化会变成/CVE_2016_6802_war_exploded 而绕过。

1 | private String removePathParameters(String input) { |
逻辑如下:
- 查找输入字符串中的第一个分号(
;)。 - 如果没有找到分号,直接返回原始字符串。
- 如果找到了分号,则创建一个
StringBuilder,并将分号之前的部分添加到结果中。 - 然后,继续查找路径中从分号之后开始的部分,直到没有更多的路径分隔符(
/)为止。 - 将找到的路径部分(不包含路径参数)添加到结果中。
漏洞修复
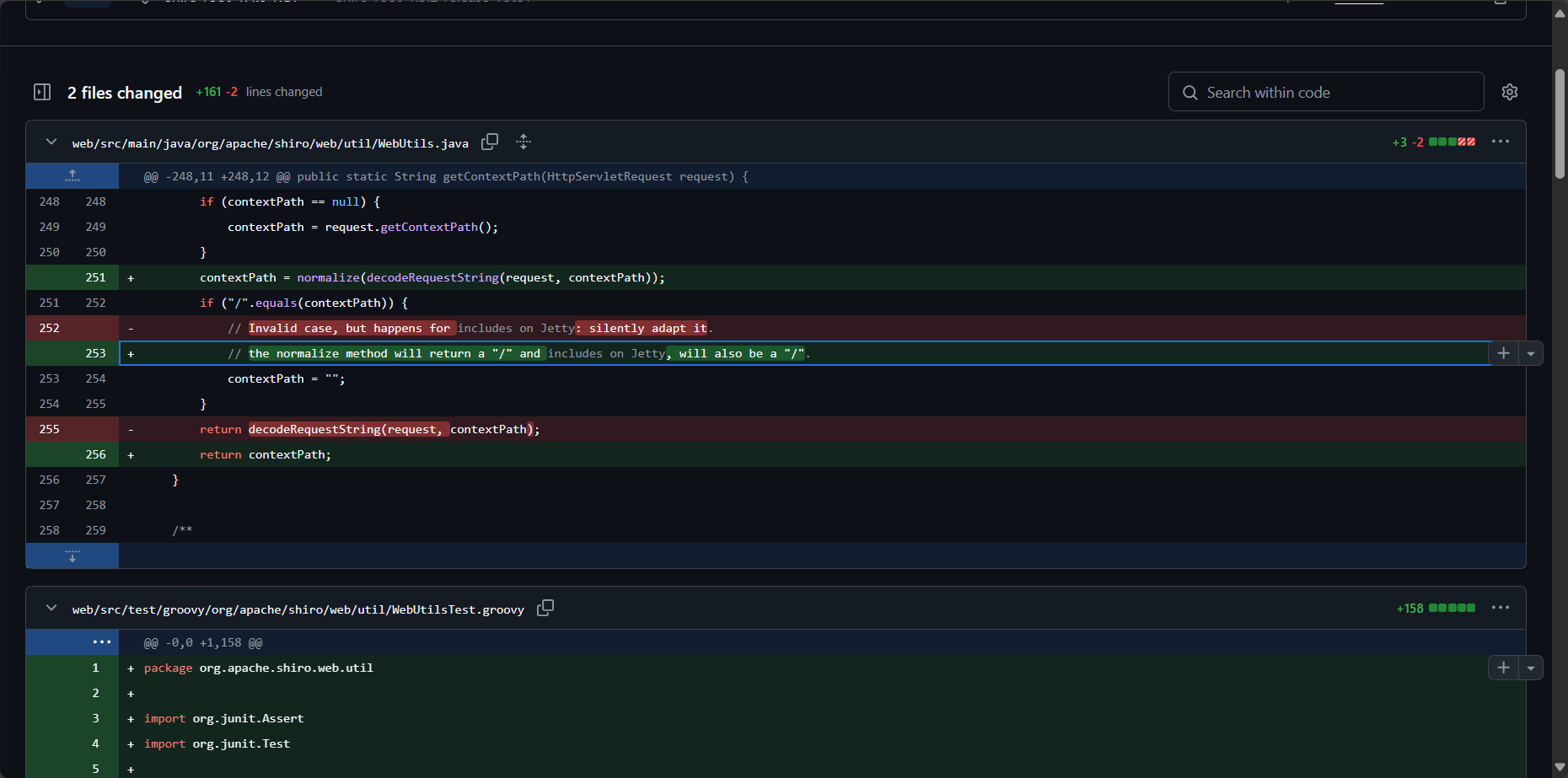
使用了修复 CVE-2010-3863 时更新的路径标准化方法 normalize 来处理 Context Path 之后再返回。
CVE-2019-12422(Shiro-721反序列化漏洞)
Apache Shiro before 1.4.2, when using the default “remember me” configuration, cookies could be susceptible to a padding attack.
漏洞信息
影响版本:shiro < 1.4.2
漏洞成因:RememberMe使用 AES-128-CBC 模式加密,易受Padding Oracle Attack攻击,攻击者可以构造RememberMe Cookie 值来实现反序列化漏洞攻击。
漏洞补丁:Updates the default Cipher mode to GCM in AesCipherService · apache/shiro@a801878
漏洞环境
和CVE-2016-4437(Shiro-550反序列化漏洞)的环境类似,改一下依赖版本。同时添加一个运行exp时需要的依赖包处理http请求。因为我喜欢把exp和漏洞环境放在一块避免文件混乱。可以将exp和漏洞环境分
1 | <!--shiro--> |
漏洞复现
参考网上的exp,编写了更为方便的java版本exp,为了方便测试用了爆破时间低的URLDNS链。根据自己的环境配置一下基本信息,运行即可获得可进行攻击的加密数据。
开始尝试java自带的HttpURLConnection进行http请求,发现会因为爆破次数太多,导致请求端口全部使用过,从而没有请求的端口资源了。但是HttpClient库可以解决这个问题。
1 | package cmisl.exp; |
运行结果

将获取的数据作为Cookie的rememberMe值:


前置知识
CBC字节翻转攻击
CBC字节翻转攻击是一种利用CBC(Cipher Block Chaining)加密模式特性的攻击方式。在CBC模式中,密文块之间的依赖关系允许攻击者通过修改初始向量iv或密文中的特定字节,来操控解密后的明文内容。我们先来介绍CBC加密模式。
CBC模式
CBC(Cipher Block Chaining,密码块链接)是一种对称加密模式。它通过将每个明文块与前一个密文块进行链接,增强了加密的安全性。
这是一个CBC加密过程:
我们会将明文进行分组划分,对每个组都调用加密算法。但是在明文块加密之前,会先与上一组的密文块(明文块的加密结果)进行异或,然后将异或的结果用加密算法加密。对于第一个明文块由于没有上一个密文块,会有一个初始向量IV来对它进行异或。

数学公式:
$$
\begin{equation}
\begin{aligned}
C_0 = E_k(P_0 \oplus IV) \
C_1 = E_k(P_1 \oplus C_0) \
C_2 = E_k(P_2 \oplus C_1) \
……………..
\end{aligned}
\end{equation}
$$
解密过程则相反,第一组密文块解密之后与初始向量IV异或得到明文块,后续密文块的解密结果与上一个密文块进行异或得到明文块。

数学公式:
$$
\begin{equation}
\begin{aligned}
P_0 = D_k(C_0) \oplus IV\
P_1 = D_k(C_1) \oplus C_0\
P_2 = D_k(C_2) \oplus C_1\
……………..
\end{aligned}
\end{equation}
$$
攻击原理
从上面知道了CBC模式解密时,该组密文用解密算法解密后得到的值,需要与上一组的密文异或才能得到明文,第一组则是需要与初始向量IV异或。
假设攻击者能够控制传输中的密文,并希望改变解密后某个明文块的特定字节:
- 攻击者修改密文块 $C_{i-1}$ 中的某些字节。
- 由于明文块 $P_i$的生成与 $C_{i-1}$ 有关,攻击者可以通过改变 $C_{i-1}$ ,操控解密时 $P_i$ 的特定字节。
举一个例子,假设我们有以下明文块(每块8字节):
- $P_0$:
admin=fa - $P_1$:
lse.....
CBC模式加密后的密文块:
- $C_0 = E_k(P_0 \oplus IV)$
- $C_1 = E_k(P_1 \oplus C_0)$
修改密文块: 假设攻击者可以获取密文,并有可能对其进行修改。攻击者的目标是通过修改密文,让解密后的明文成为
admin=true。比特翻转: 攻击者关注的密文块是 $C_0$,因为它影响 $P_1$ 的解密结果。假设 $P_1$ 的某个字节对应 $f$ 的ASCII编码(102),攻击者可以翻转任意一个比特来改变其值以透露不同的字符,在这种情况下想要达到 $t$(ASCII编码116)。
通过计算:
$$
116_{10} = 102_{10} \oplus x
$$
这里 (x) 是攻击者需要翻转的比特模式,通过计算得出:
$$
x = 116 \oplus 102 = 18
$$
攻击者修改 $C_0$ 中相应的字节,将其异或18,就可以将 $P_1$ 中的 $f$ 改为 $t$。整个详细的推导过程很简单,可以自行推导一下。

填充算法
常见的对称加密算法一般分组加密,将明文按照规定的bit位数划分为一个个的明文块。然后用加密算法对每个明文块加密,经过不同的工作模式处理得到密文。下面介绍Shiro使用的PKCS#7,
PKCS#7
在填充时,所有填充值的字节被设为填充字节数的值。例如,如果需要填充4个字节,那么每个填充值都是
0x04。例子:如果块大小是8字节,明文是
"HELLO"(5字节),则填充后的结果是"HELLO\x03\x03\x03"。下面是在翻阅文章见过很多的一张图,也可以直观看出填充算法是如何填充的:

下面内容来自:PKCS#1、PKCS#5、PKCS#7、PKCS#8到底是什么?_pkcs1-CSDN博客
PKCS7
PKCS7与PKCS5的区别在于PKCS5只填充到8字节,而PKCS7可以在1-255之间任意填充。
简单地说, PKCS5, PKCS7和SSL3, 以及CMS(Cryptographic Message Syntax)
注意:
当只讨论了 8字节(64位) 块的加密, 对其他块大小没有做说明,其PKCS5填充算法跟 PKCS7是一样的。
但是后来 AES 等算法, 把BlockSize扩充到 16个字节。因为AES并没有64位的块, 如果采用PKCS5, 那么实质上就是采用PKCS7。
理解:
PKCS#5填充是PKCS#7填充的一个子集,在PKCS#7填充时BlockSize为8的时候,PKCS#5与PKCS#7填充是一样的,
在BlockSize不同时PKCS#5与PKCS#7填充是不同的,PKCS#5填充是将数据填充到8的倍数,填充后数据长度的计算公式是
定于元数据长度为x, 填充后的长度是 x + (8 - (x % 8)), 填充的数据是 8 - (x % 8)
因此所以,PKCS#5可以向上转换为PKCS#7,但是PKCS#7不一定可以转换到PKCS#5(用PKCS#7填充加密的密文,用PKCS#5解出来是错误的)。
所以现在有些算法写的是PKCS#5,但是输出的确实PKCS#7。
因此虽然源码中使用PKCS5Padding检测填充的规范性,但是不要被类名迷惑了,实际填充算法还是PKCS#7。
Padding Oracle Attack
Padding Oracle Attack是一种针对使用填充模式的加密协议的攻击,尤其在对称加密算法中,比如AES的CBC模式。当使用这些模式进行加密时,明文需要被填充到适合块大小的长度。在解密过程中,如果填充不正确,应用程序可能会返回一个错误信息。Padding Oracle Attack利用这一特性,通过观察应用程序是否返回填充错误来推测加密数据的内容。
所以该 Padding Oracle Attack需要的条件:
- 攻击者知道并且能控制密文以及初始向量IV。
- 可以通过发送密文触发解密过程,并且解密过程中填充不正确时,系统需要返回一个特定的错误或者区别于填充正确的标记。
举一个很多文章出现的场景,由于此图片出现很多文章中,所以并未找到出处。
这是一段密文的解密过程,我们发送密文7B216A634951170FF851D6CC68FC9537858795A28ED4AAC6给服务器进行一个认证。(一般IV是携带发送的,作为密文块的前缀)服务器会去解密该密文。因此会有下面情况:
- 当收到一个有效的密文(一个被正确填充并包含有效数据的密文)时,应用程序正常响应(200 OK)
- 当收到无效的密文时(解密时填充错误的密文),应用程序会抛出加密异常(500 内部服务器错误)
- 当收到一个有效密文(解密时正确填充的密文)但解密为无效值时,应用程序会显示自定义错误消息 (200 OK)

Encrypted Input:输入的密文Intermediary Value:计算的中间值Initialization Vector:初始化向量Plain-Text(Padded)/Decrypted Value:解密出的明文
流程
我们作为发送方,根据密文知道的是如下信息。
1 | 初始化向量: 7B 21 6A 63 49 51 17 0F |
尝试破解第一组密文,将初始化向量设为0,即0000000000000000F851D6CC68FC9537,此时会解密失败,服务器也会返回请求异常或错误。因为解密出来的值不符合PKCS#7。

爆破IV的最后一个字节,直到其为0x3C时,也就是发送数据是0000000000000066F851D6CC68FC9537时,解密的值为0x01,符合PKCS#7,此时服务器会正常返回。

从两次与服务器交互,因为解密异常造成返回的差异可以知道:
$$
0x3C\oplus对应字节位的中间值=0x01
$$
可以计算出该中间值为0x3D,因此可以确定一个中间值了,而中间值是不会变的,因为我们的密文不变。我们可以重复上面的操作,比如假设解出来的明文最后两位是0x02,符合PKCS#7,因此有下面式子:
$$
0x3D\oplus IV对应的字节位=0x02\
0x26\oplus对应字节位的中间值=0x02
$$
此时我们又可以接触一位中间值为0x2E。
重复该过程,直到假设的明文值为0x08 0x08 0x08 0x08 0x08 0x08 0x08 0x08 :
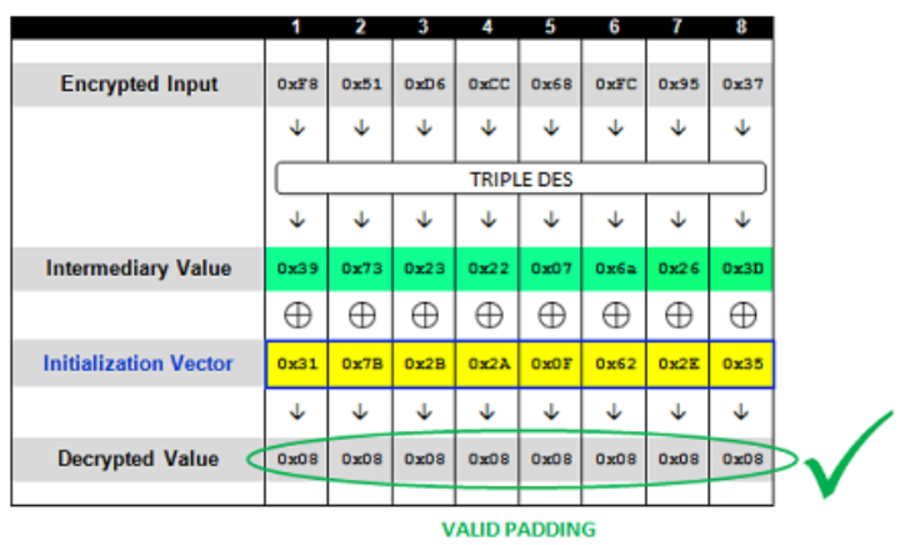
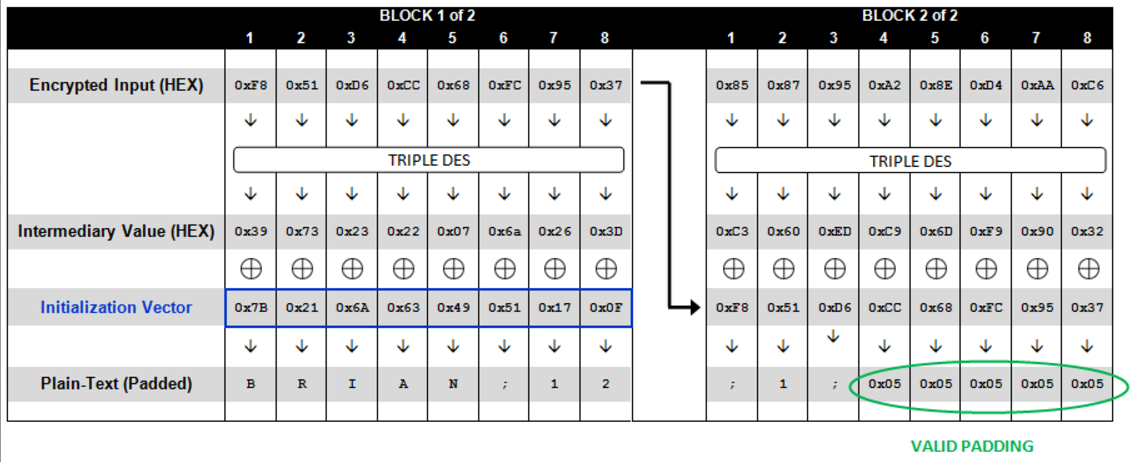
此时就得到了该组所有中间值,将其与初始向量IV异或即可得到真正的明文。并且我们获取了中间值,可以构造IV来达到解密出想要的明文效果,因为明文是中间值与IV异或得来的。
对于多组加密,需要从最后一组,构造出IV,然后把构造的IV作为上一组的密文,重复上述流程,得到中间值,继续根据想要解密出的明文构造IV,然后重复该做法即可。
漏洞分析
根据前置知识的学习,配合POC源码,大概就可以懂该漏洞的原理了。
首先通过发送登录请求获取接下来交互所需的Cookie,也就是AES-CBC加密的密文。然后通过前置知识中提到的攻击方法,爆破篡改密文,使得解密出来的明文是我们序列化数据。
和CVE-2016-4437(Shiro-550反序列化漏洞)一样我们直接在CookieRememberMeManager#getRememberedSerializedIdentity打上断点。
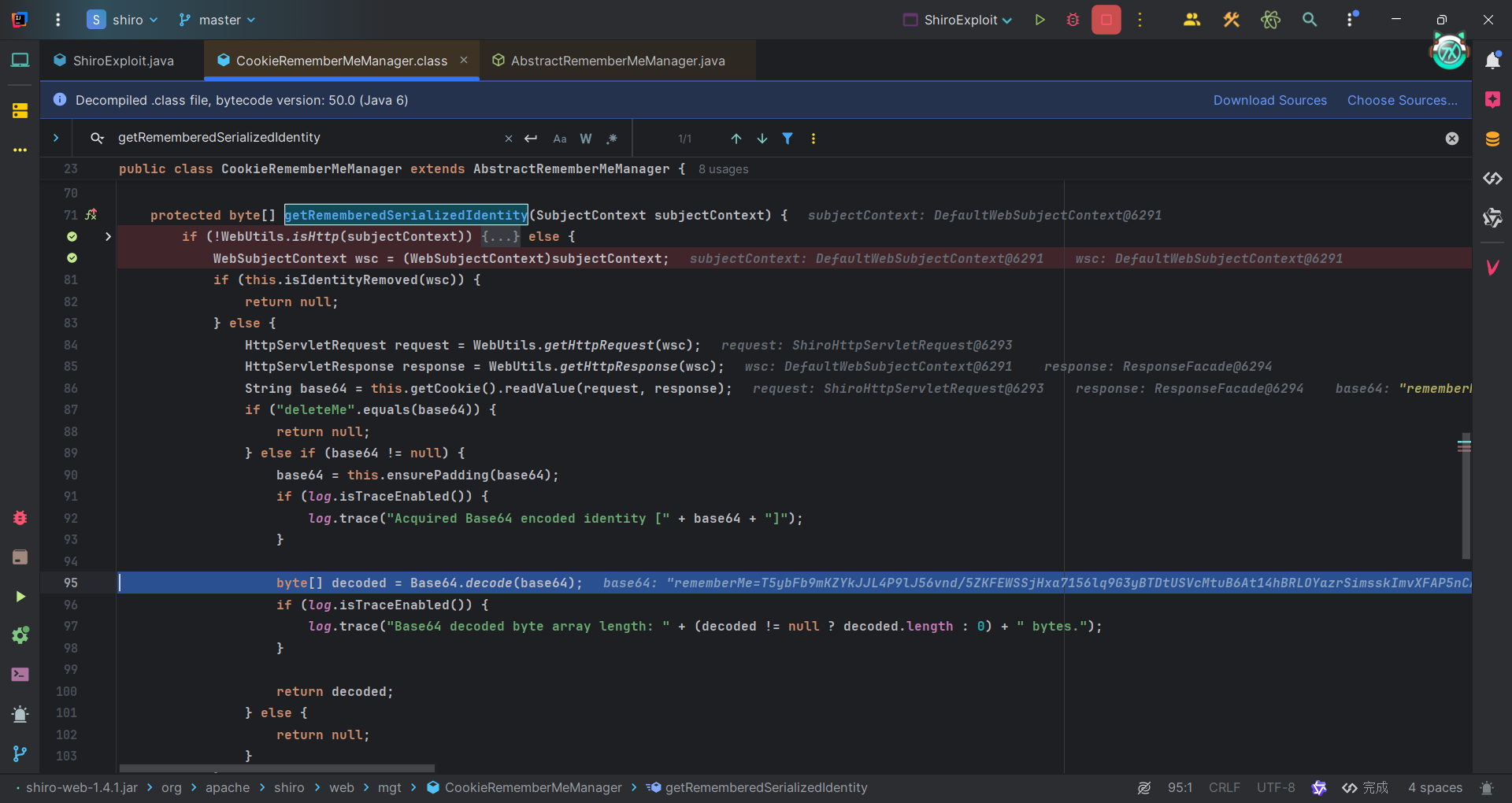
获取Cookie之后去用ensurePadding方法确认数据的填充,然后Base64解码返回给上去。然后调用AbstractRememberMeManager#convertBytesToPrincipals函数,一路往下调用解封装和检查。
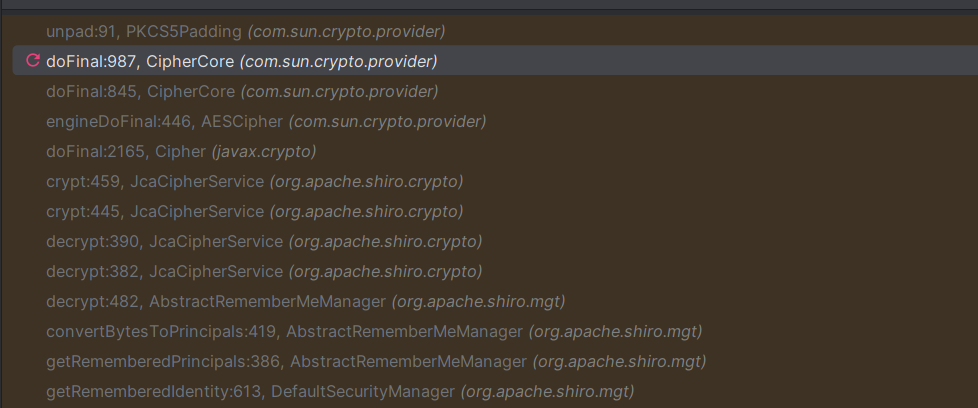
PKCS5Padding#unpad方法检测填充是否符合要求,不符合就返回-1,然后向上抛异常,直到回到AbstractRememberMeManager#onRememberedPrincipalFailure,会去把cookie设置为deleteMe。

后续过程其实和shiro550差不多,解密的数据拿去反序列化。
漏洞修复

直接用AES-CBC加密模式换成了AES-GCM加密模式。因为攻击是基于AES-CBC加密模式的漏洞攻击的。
参考链接
Padding Oracle Attack(填充提示攻击)详解及验证 - 简书
Padding oracle attack | Infosec
CBC字节翻转攻击&Padding Oracle Attack原理解析 - 枫のBlog
CBC byte flipping attack—101 approach | Infosec
浅析CBC字节翻转攻击与Padding Oracle Attack [ Mi1k7ea ]
Shiro-682
没有具体的CVE编号,是一个Apache Shiro 项目的一个问题报告。报告链接:[SHIRO-682] fix the potential threat when use “uri = uri + ‘/‘ “ to bypassed shiro protect - ASF JIRA
漏洞信息
影响版本:shiro < 1.5.0
漏洞成因:在 Spring Web 环境中,访问 URI /resource/menus 和 /resource/menus/ 都可以访问相同的资源,但 Shiro 的路径模式匹配机制未能正确处理这两种情况。导致用户可以通过在请求 URI 后添加 / 来绕过 Shiro 的过滤器。
漏洞环境
1 | <dependency> |
漏洞复现
正常访问需要权限的页面/Shiro682,会302跳转到登录页面。

如果在访问url后加一个/,即访问/Shiro682/,可以无需权限访问。

漏洞分析
Shiro对于url的处理前面已经提到过了。通过在PathMatchingFilterChainResolver#getChain方法中,会去调用getPathWithinApplication方法从request请求中获取请求URI,得到的是/Shiro682/。而我们设置的需要鉴权的URI是/Shiro682。而因为请求URI后多一个斜杠,所以无法匹配上,因此不会进过Shiro过滤器。
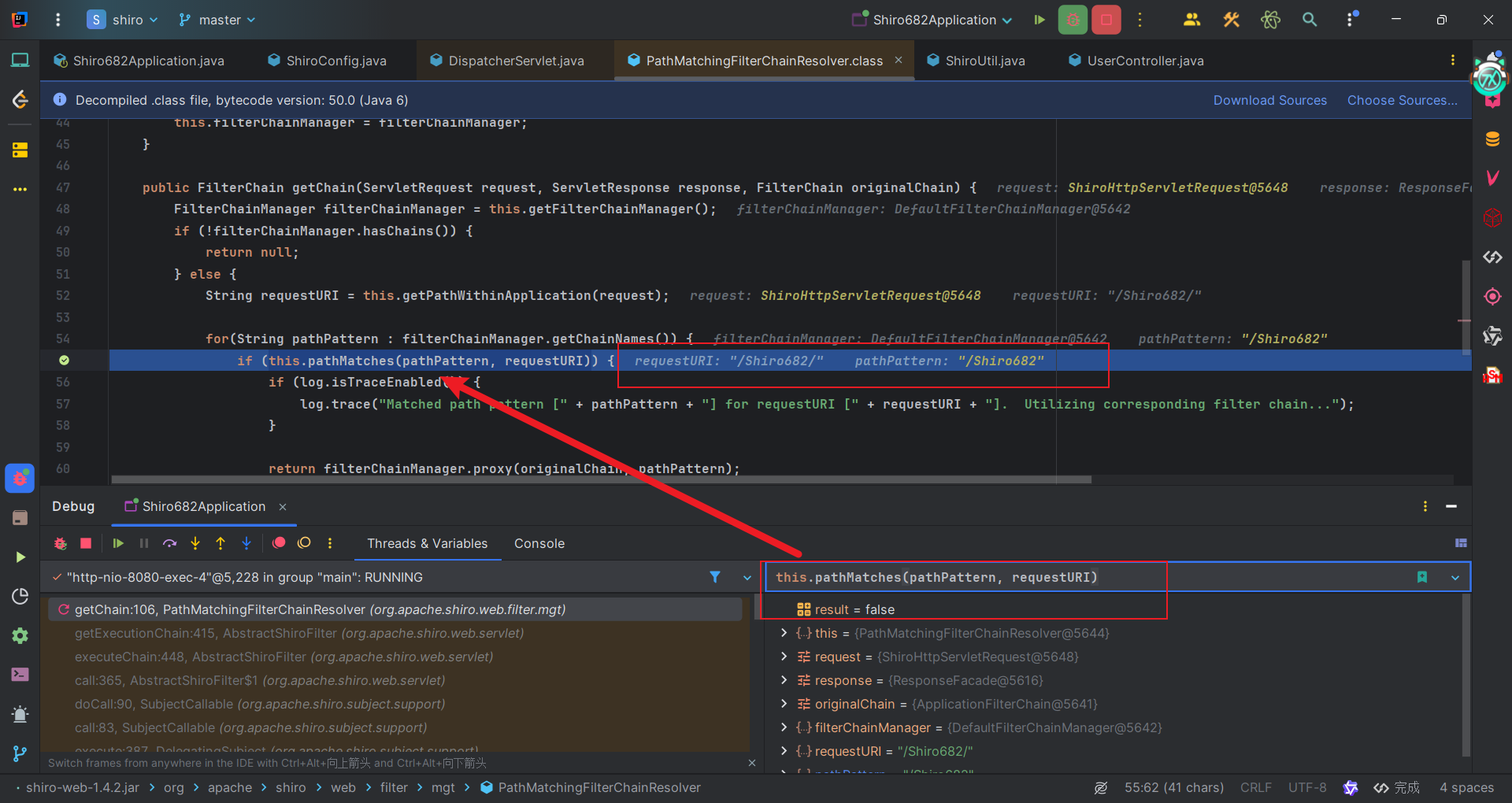
对于spring的URI处理,会发现它将/Shiro682/和/Shiro682匹配上,因此spring会认为/Shiro682/访问的就是/Shiro682。

对于/admin.html这种访问资源的方法同样有效,会匹配到/** 上,后续会将admin.html取出来,再去resources目录下寻找该资源。具体流程可以自行调试。

漏洞修复
在PathMatchingFilter和PathMatchingFilterChainResolver设置了一个默认路径分隔符DEFAULT_PATH_SEPARATOR,即为/,如果路径以此结尾,会截取掉。


CVE-2020-1957(Shiro-682的绕过)
Apache Shiro before 1.5.2, when using Apache Shiro with Spring dynamic controllers, a specially crafted request may cause an authentication bypass.
漏洞信息
影响版本:shiro < 1.5.2
漏洞成因: Shiro 和 Spring 对 URL 的处理的差异化。
漏洞补丁:Add tests for WebUtils · apache/shiro@3708d79
漏洞环境
注意我这里的SprintBoot版本是2.1.5.RELEASE,网上常见的POC,即/xxx/../admin,在版本较高的SprintBoot中会返回报错页面。测试发现2.3.12.RELEASE不行,而2.1.5.RELEASE可以。
1 | <properties> |
补:关于版本的原因后续在该篇文章看到解答——Spring Boot中关于%2e的Trick - Ruilin
当 Spring Boot 版本在小于等于 2.3.0.RELEASE 的情况下,alwaysUseFullPath 为默认值 false,这会使得其获取 ServletPath ,所以在路由匹配时相当于会进行路径标准化包括对 %2e 解码以及处理跨目录,这可能导致身份验证绕过。而反过来由于高版本将 alwaysUseFullPath 自动配置成了 true 从而开启全路径,又可能导致一些安全问题。
漏洞复现
对于路径/CVE-2020-1957,使用以下方式绕过。
1 | /xxx/..;/CVE-2020-1957 |


对于路径/cmisl/CVE-2020-1957,可以使用以下方式绕过。
1 | /cmisl;/CVE-2020-1957 |

漏洞分析
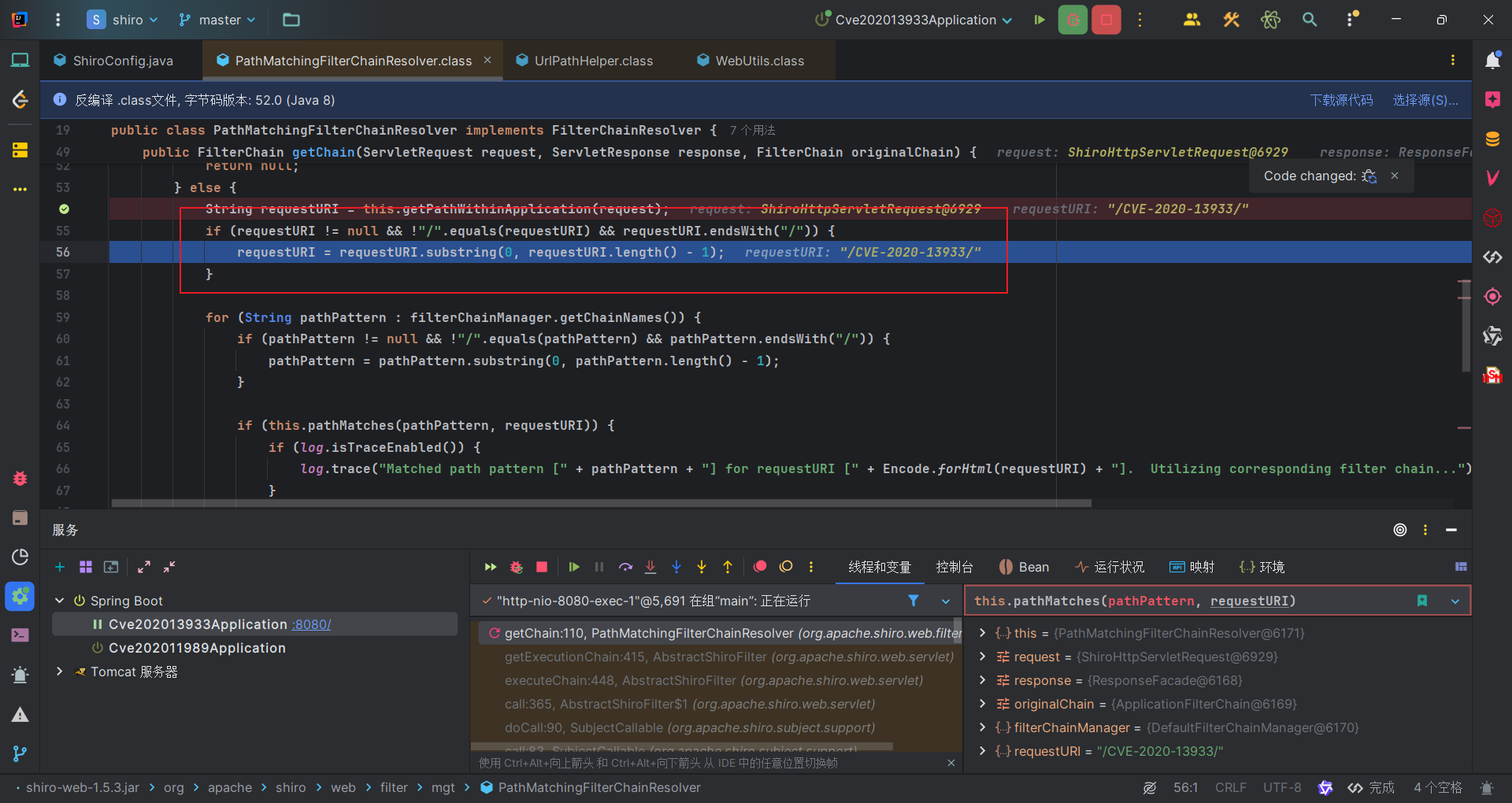
与Shiro-682是因为shiro和spring对路径分隔符/处理的差异化类似。该漏洞是由于shiro和spring对于分号;的差异化处理造成的。就用/xx/..;/CVE-2020-1957来分析
大致一看是在PathMatchingFilterChainResolver#getChain方法中,通过getPathWithinApplication方法获取请求URI时,只得到分号之前的URI,也就是/xx/..。因此没有对应的过滤路径与其匹配。

具体就可以跟进去,到WebUtils#decodeAndCleanUriString,会获取分号的位置,然后截取前面的内容并且返回。
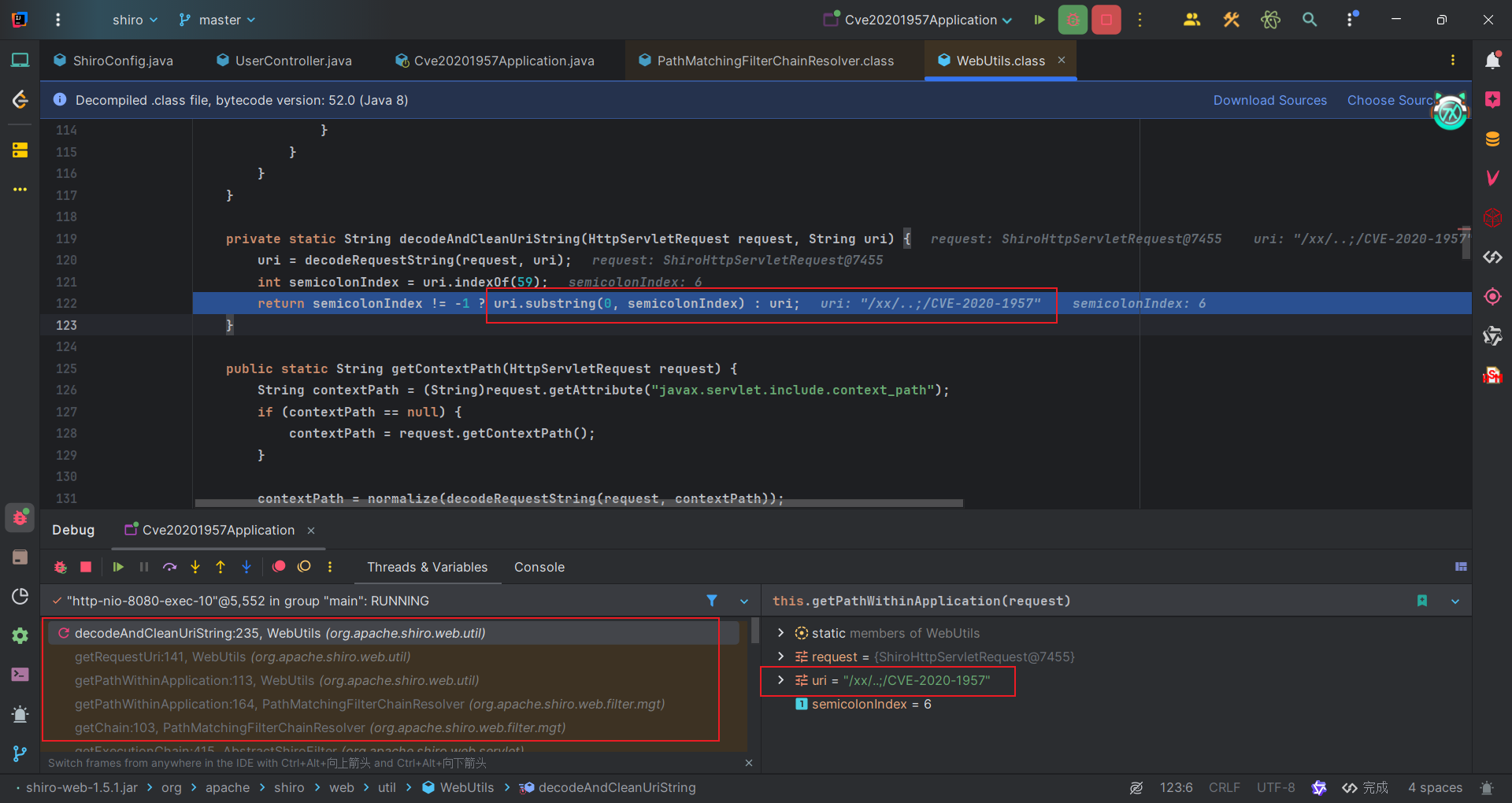
而spring的处理是在UrlPathHelper#decodeAndCleanUriString,可以看到对uri的处理主要是三个方法进行处理。分别是:
- removeSemicolonContent:删除分号后到分隔符之间的内容。(包含分号)
- decodeRequestString:URL解码。
- getSanitizedPath:规范路径。(比如//aaa->/aaa)
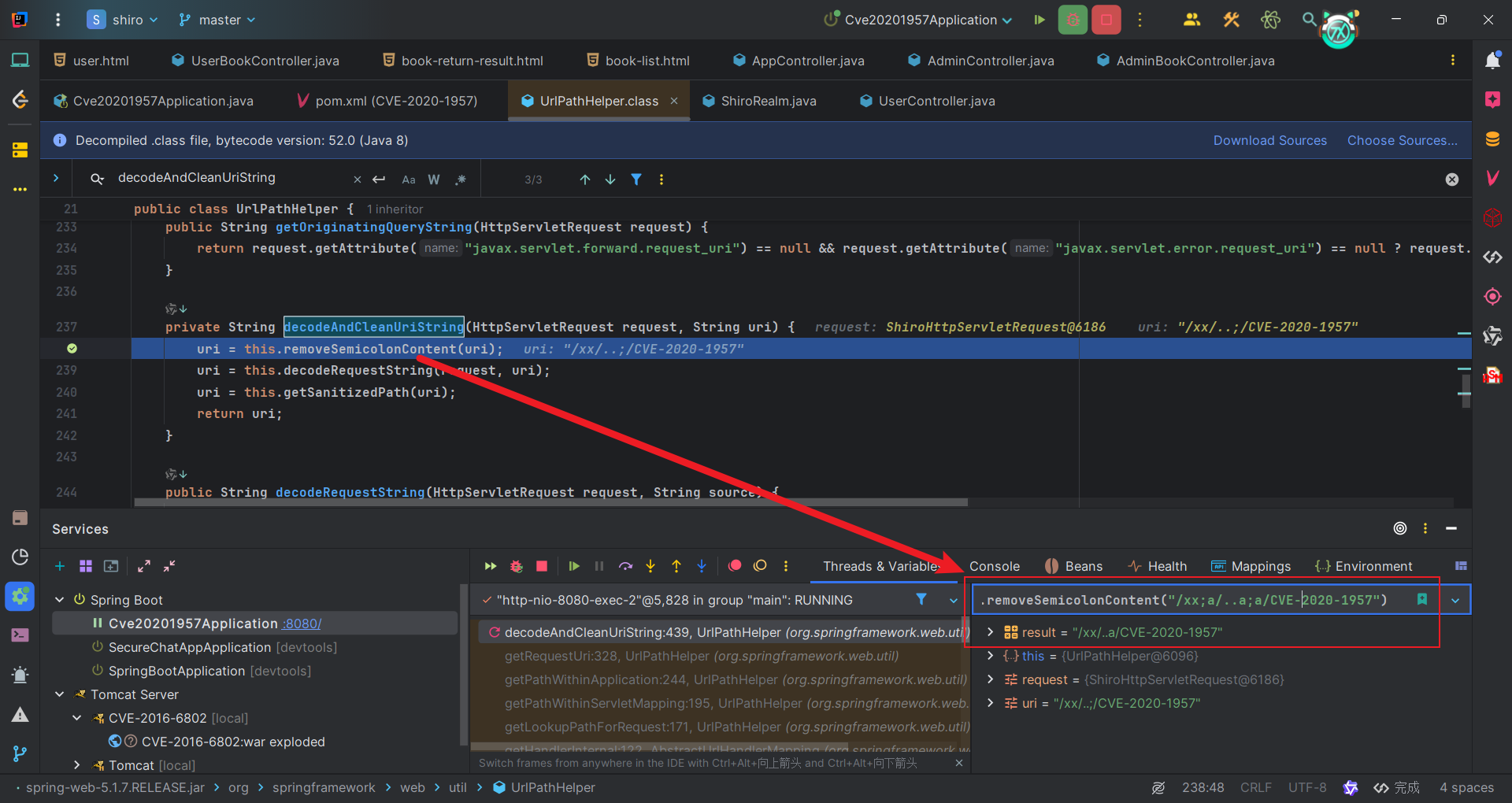
根据上面三个方法的解释,我们可以设计一个绕过路径。比如:/aaa;aaa///..;abc/test。
首先会把分号到分隔符之间的内容(包括分号)直接内容去除,上面路径则变成/aaa///../test,然后解码、规范化,上面路径变成/aaa/../test。后续便会标准化成/test。
而我们的访问路径/xx/..;/CVE-2020-1957,就是/CVE-2020-1957。
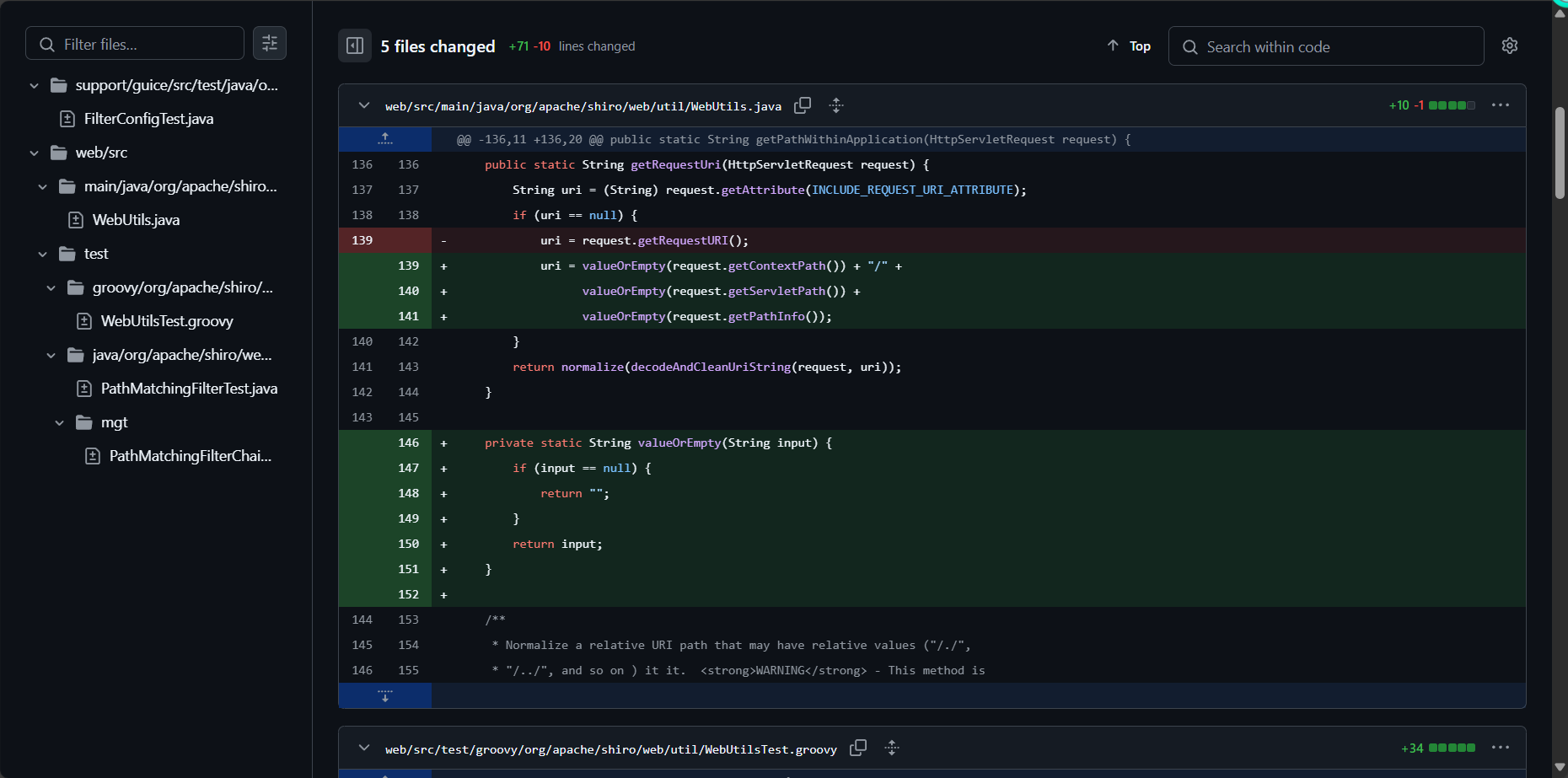
漏洞修复
通过request.getContextPath()、request.getServletPath()、request.getPathInfo() 进行拼接,获取经过处理后的URI。
参考链接
Spring Boot中关于%2e的Trick - Ruilin
Java Shiro 权限绕过多漏洞分析 | Drunkbaby’s Blog
CVE-2020-11989
Apache Shiro before 1.5.3, when using Apache Shiro with Spring dynamic controllers, a specially crafted request may cause an authentication bypass.
漏洞信息
影响版本:shiro < 1.5.3
漏洞成因:Shiro对URL二次解码造成的绕过以及Shiro与Spring处理路径的差异化导致的绕过。
漏洞补丁:Merge pull request #211 from apache/SHIRO-753 · apache/shiro@01887f6
绕过方式一:URL二次解码
漏洞环境
1 | <dependency> |
添加访问接口:
1 |
|
权限路径配置:
1 | Map<String, String> filterChainDefinitionMap = new LinkedHashMap<>(); |
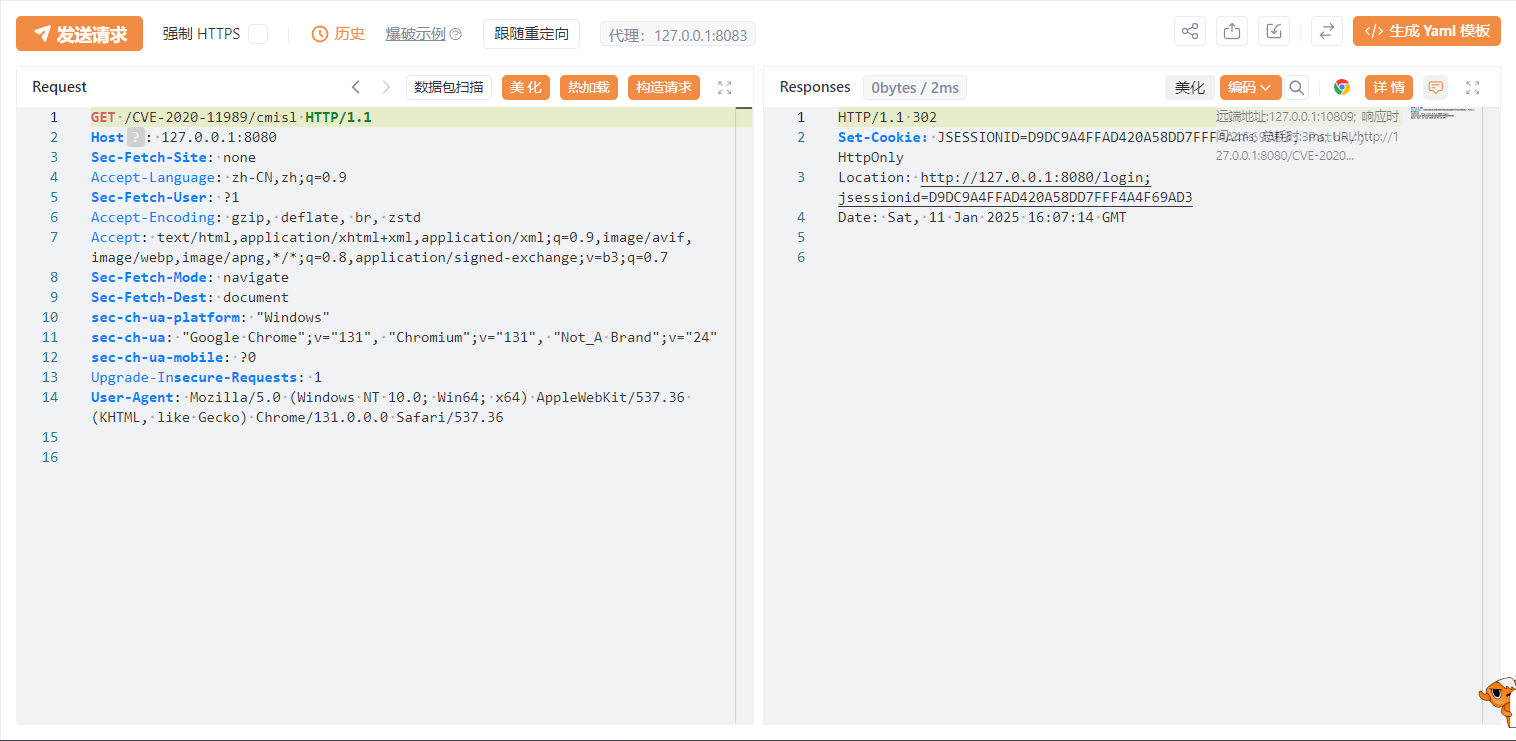
漏洞复现
我们是将/CVE-2020-1957/*设置需要权限才能访问的路径,所以我们正常访问因为是会跳转到登录页面的。
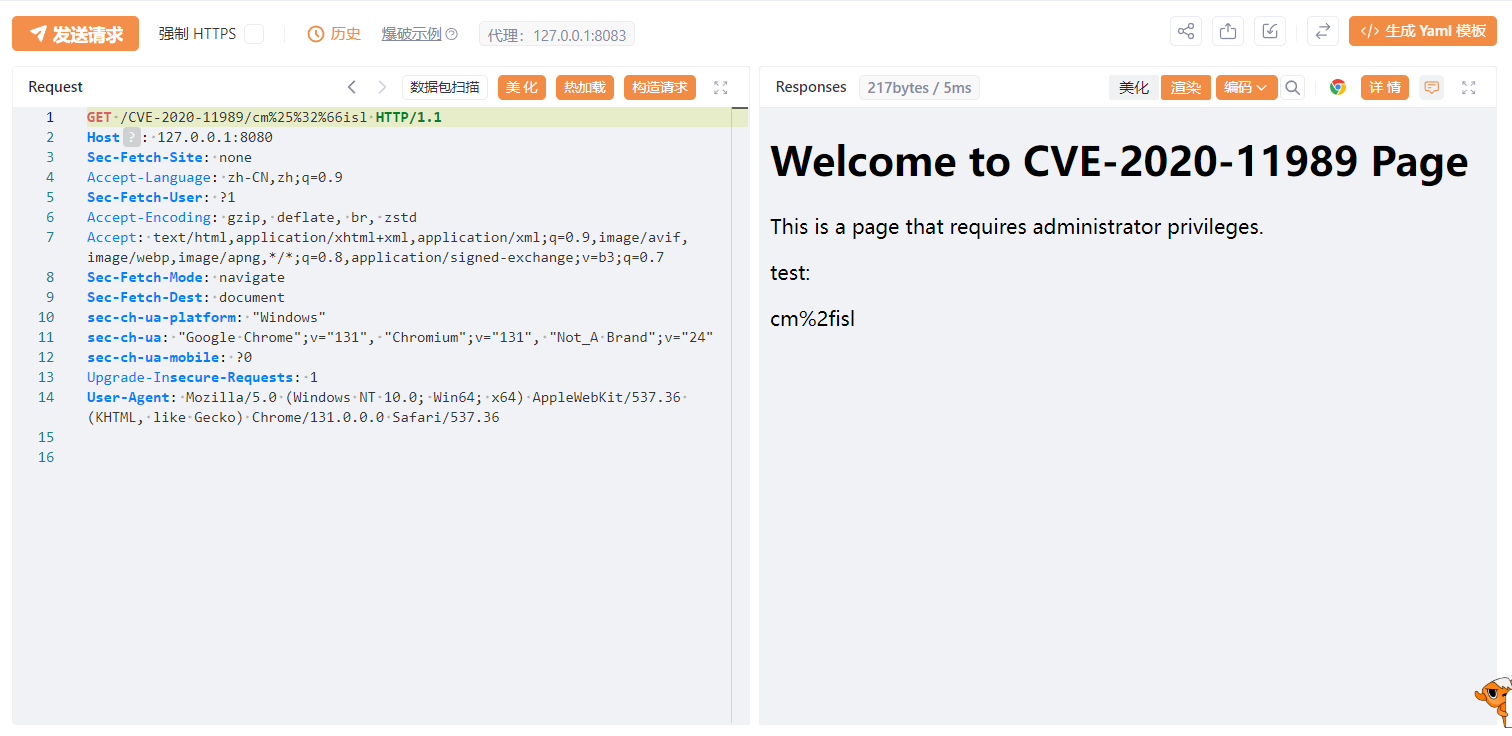
如果我们把变量部分,也就是cmisl中间插入%25%32%66,就可以绕过了。
URL编码:
/->%2f->%25%32%66拆分:(%25->/、%32->2、%66->f)
漏洞分析
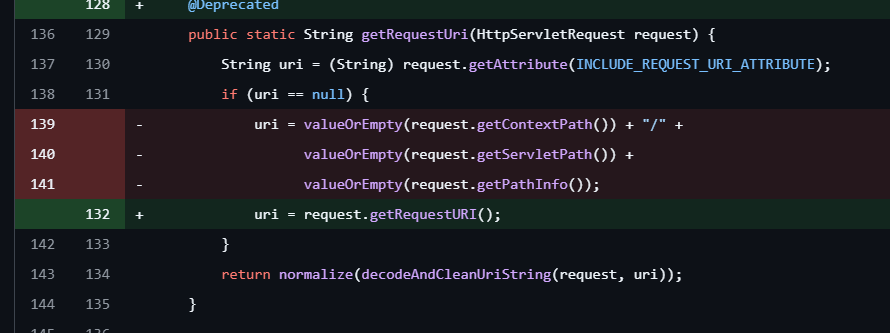
从PathMatchingFilterChainResolver#getChain进入WebUtils#getRequestUri,很熟悉的地方,是shiro用来获取requestURI来对比拦截器链中的URI。

我们在CVE-2020-1957中知道,shiro不再使用request.getRequestURI(),而是通过request.getContextPath()、request.getServletPath()、request.getPathInfo() 进行拼接,获取请求的URI。
而这几个方法的差异可以参考mi1k7ea师傅的Tomcat URL解析差异性导致的安全问题 - 先知社区

request.getRequestURI()不会进行URL解码,而request.getServletPath(),我们请求的URI是/CVE-2020-11989/cm%25%32%66isl,进行解码后得到的是/CVE-2020-11989/cm%2fisl。
%25->/、%32->2、%66->f%25%32%66->%2f
后续将得到的路径,然后会调用decodeAndCleanUriString方法对路径进行解码,并且去掉分号之后的部分。然后返回交给normalize方法规范化。
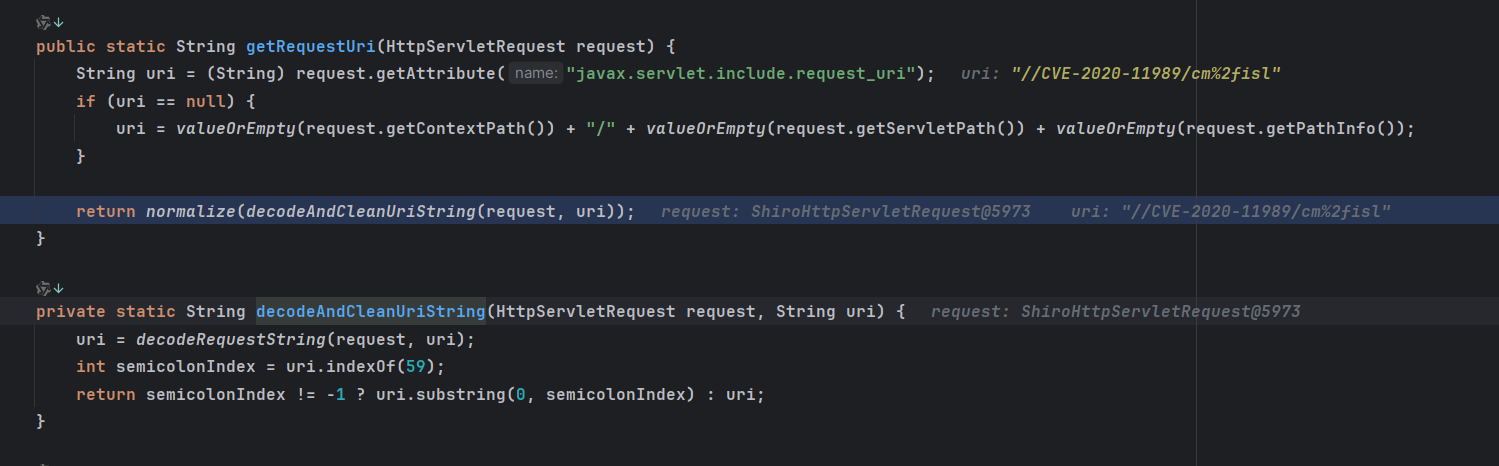
因此最后得到的路径是/CVE-2020-11989/cm/isl。
我们配置的拦截规则是/CVE-2020-1957/*,对于这种规则,Shiro会使用AntPathMatcher这个匹配器进行路径的匹配。
匹配方法大致是,将匹配规则和访问路径都分成数组。然后两个数组每个元素进行匹配,这个过程中,如果发现匹配规则取出来的是**,就跳出这个循环,在下一个循环中进行匹配。如果是*就在matchStrings方法中处理。
具体规则如下:
比如拦截规则是/cmisl/*,那就可以和/cmisl/abc匹配,但是不能和/cmisl/a/b匹配。
如果拦截规则是/cmisl/**,那就可以和/cmisl/abc以及/cmisl/a/b匹配。
因此我们的路径/CVE-2020-11989/cm/isl就无法和/CVE-2020-11989/*匹配上。从而绕过了shiro的权限认证。
绕过方式二:Shiro与Spring处理路径差异化
漏洞环境
1 | <dependency> |
设置访问根路径(application.properties):
1 | server.servlet.context-path : /cmisl |
添加访问接口:
1 |
|
权限路径配置:
1 | Map<String, String> filterChainDefinitionMap = new LinkedHashMap<>(); |
漏洞复现
直接访问/cmisl/CVE-2020-11989,跳转到登录页面。
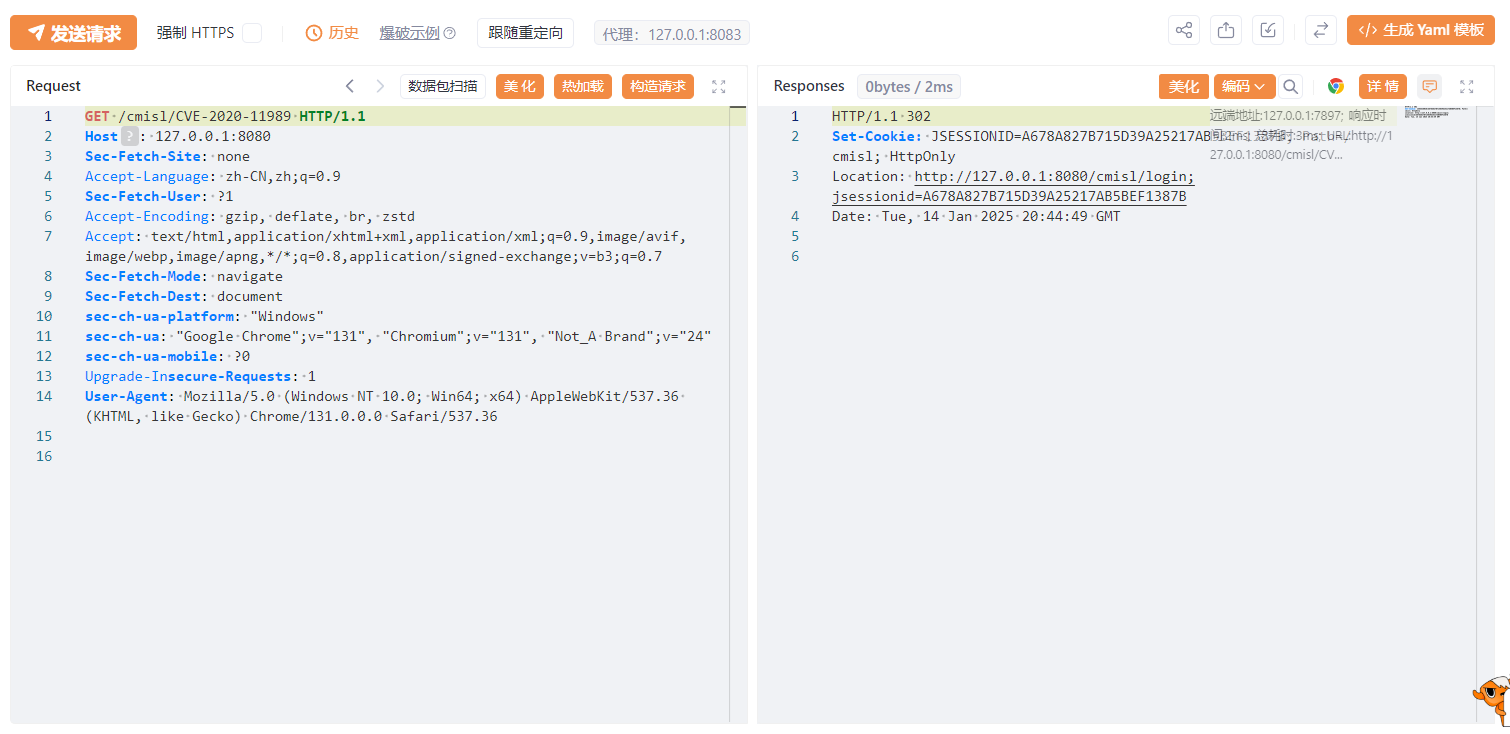
访问/;/cmisl/CVE-2020-11989,可以访问到需要权限的目录。
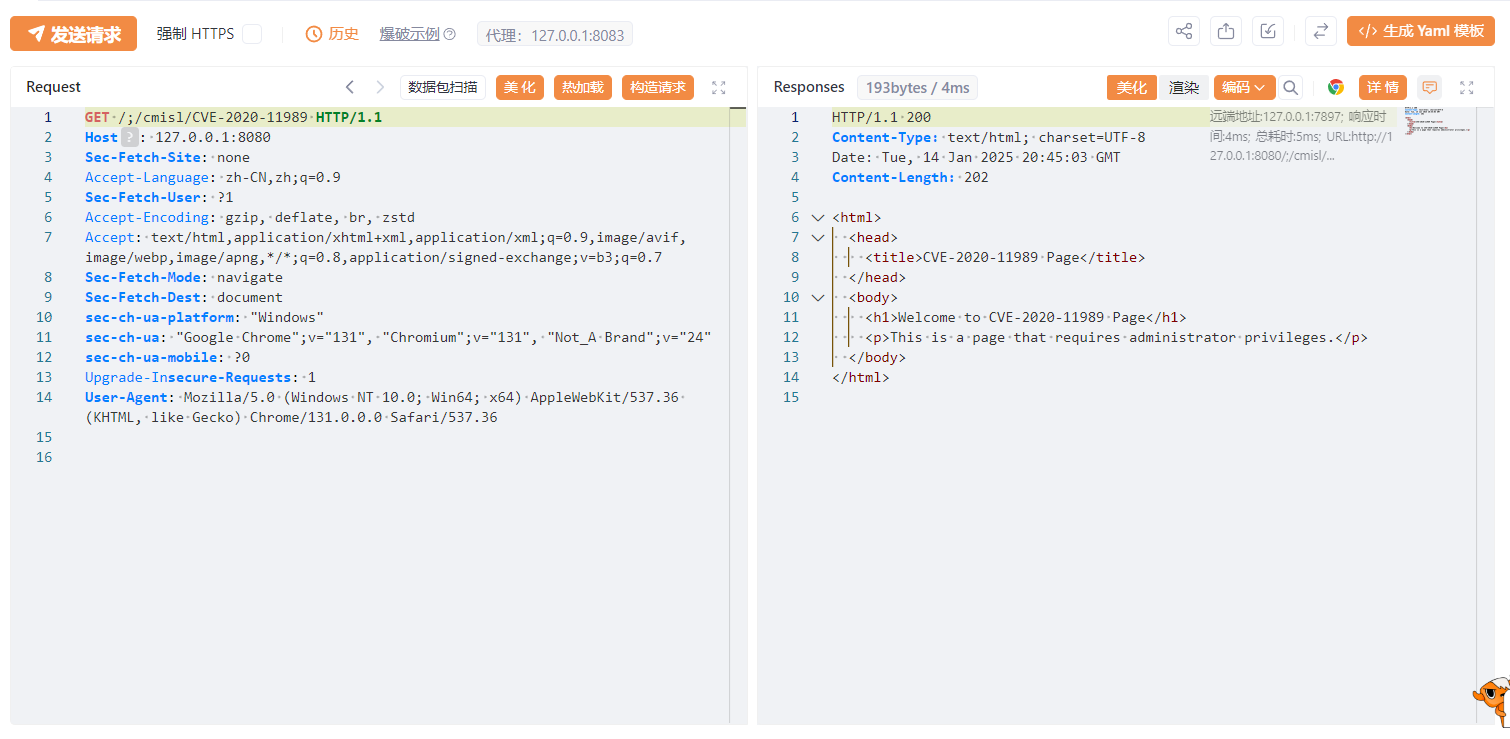
漏洞分析
对于Shiro来说,/;/cmisl/CVE-2020-11989得到的路径经过规范化后,会去掉分号后部分,因此,Shiro得到的路径是/,显然不会与设置的拦截规则不匹配。

而spring解析的路径是/cmisl/CVE-2020-11989,因此可以找到该资源。
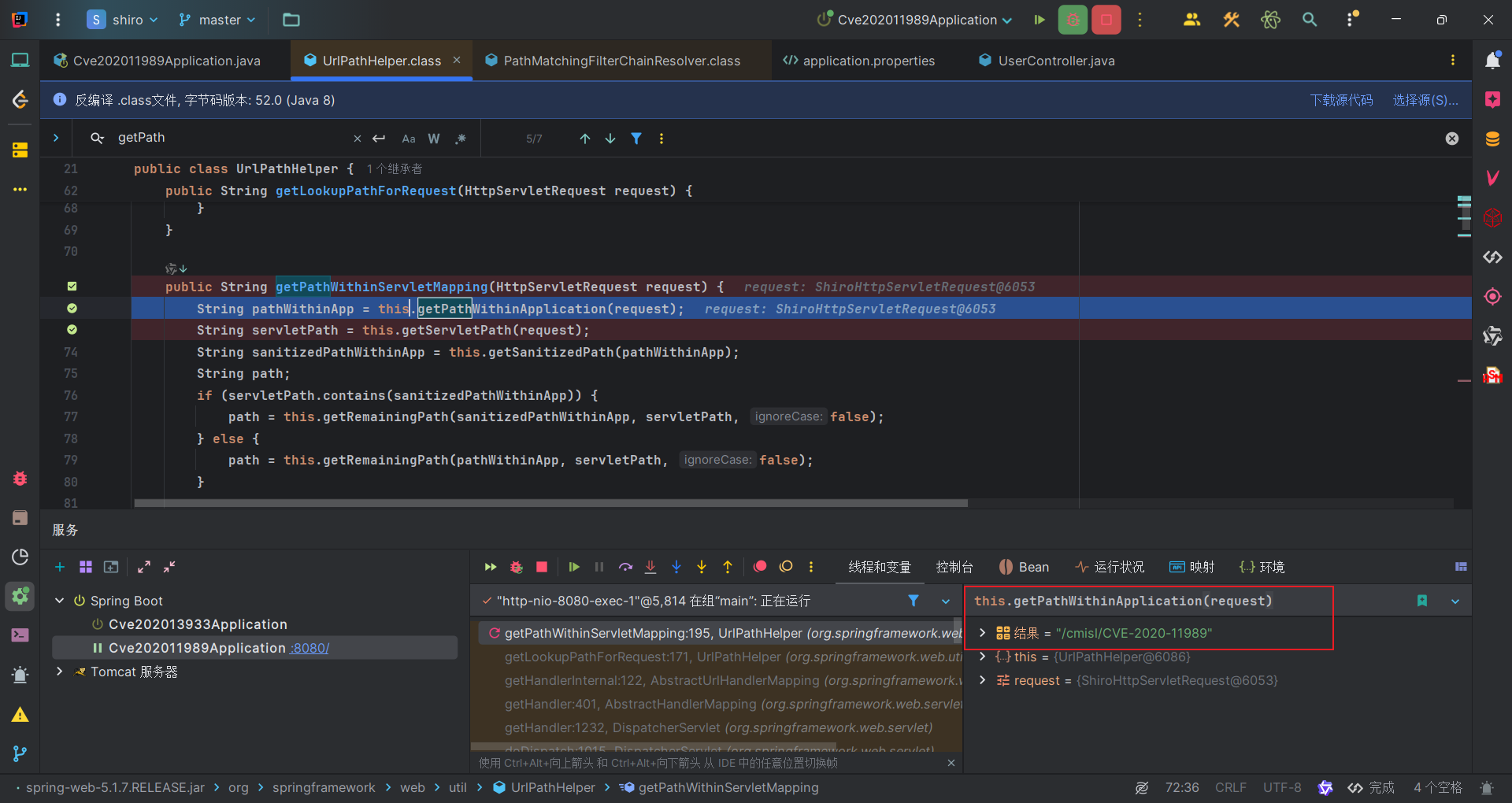
漏洞修复
WebUtils#getPathWithinApplication方法,将原来servletPath、ServletPath、PathInfo组成的requestUri规范化后的结果,减去内容根目录contextPath的方法替换成直接用servletPath加PathInfo后再规范化。
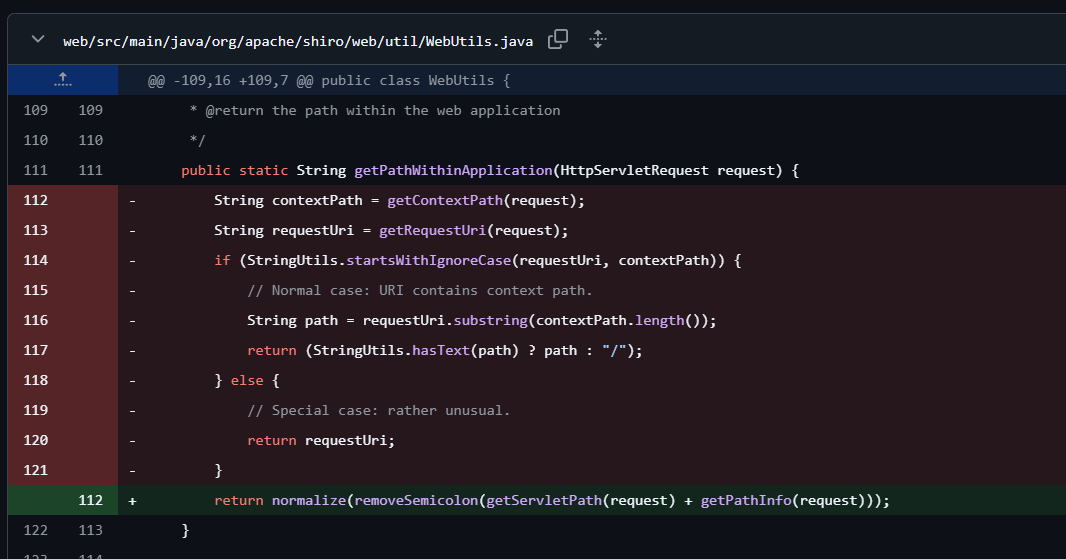
并且WebUtils#getRequestUri方法将上一次漏洞的补丁撤回,直接获取整个路径。不过改方法被标记为已弃用。所以他的修改不会影响后面的绕过,主要关注的还是getPathWithinApplication方法。
参考链接
Apache Shiro 身份验证绕过漏洞 (CVE-2020-11989) - 腾讯安全玄武实验室
CVE-2020-13933
Apache Shiro before 1.6.0, when using Apache Shiro, a specially crafted HTTP request may cause an authentication bypass.
漏洞信息
影响版本:`shiro < 1.6.0
漏洞成因: 在1.6.0之前的Apache Shiro中,使用Apache Shiro时,特制的HTTP请求可能导致身份验证绕过。
漏洞补丁:Add a feature to allow for global filters · apache/shiro@dc194fc
漏洞环境
1 | <!--shiro-spring--> |
添加访问接口:
1 |
|
权限路径配置:
1 | Map<String, String> filterChainDefinitionMap = new LinkedHashMap<>(); |
漏洞复现
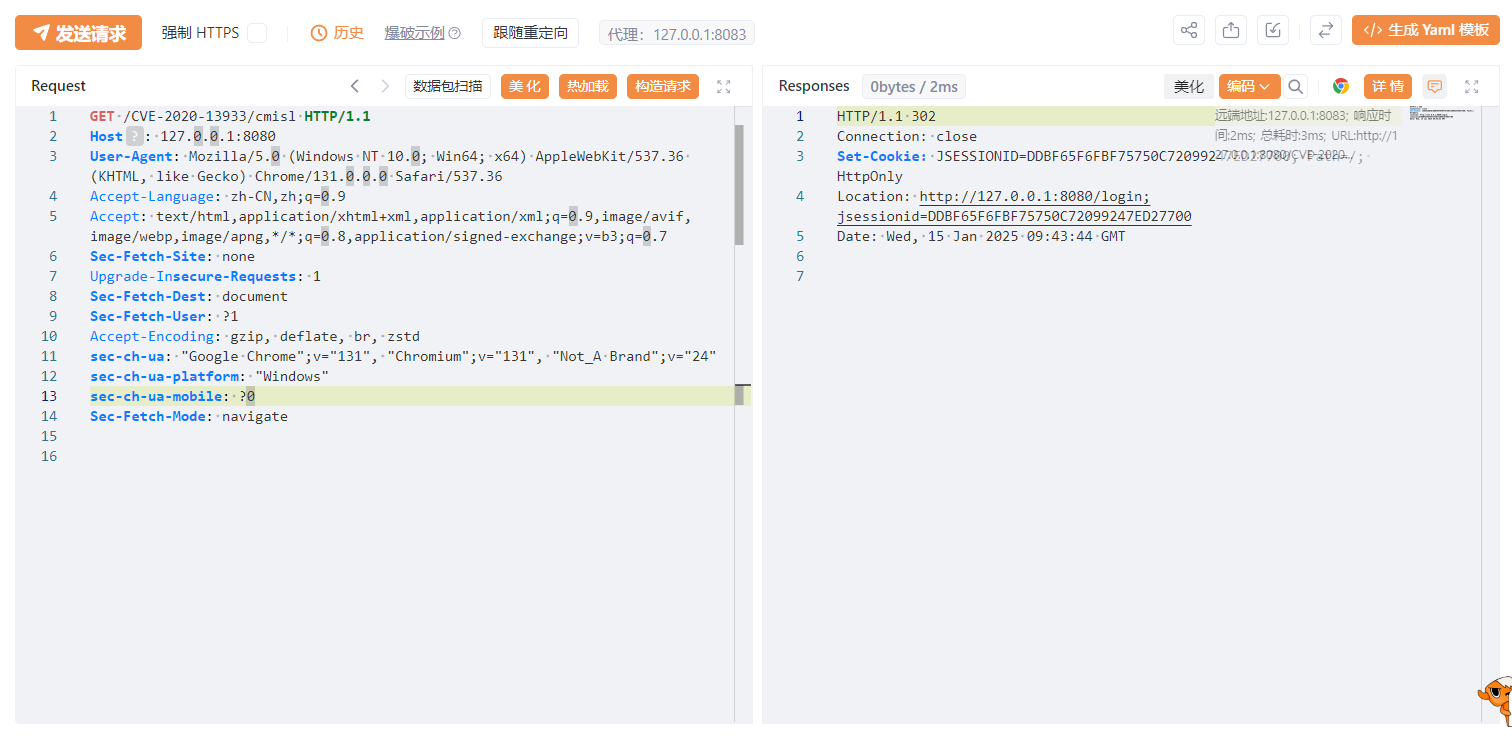
正常访问/CVE-2020-13933/cmisl,会302跳转到登录页面。
访问/CVE-2020-13933/%3bcmisl,可以绕过权限认证,直接访问到需要权限的页面。
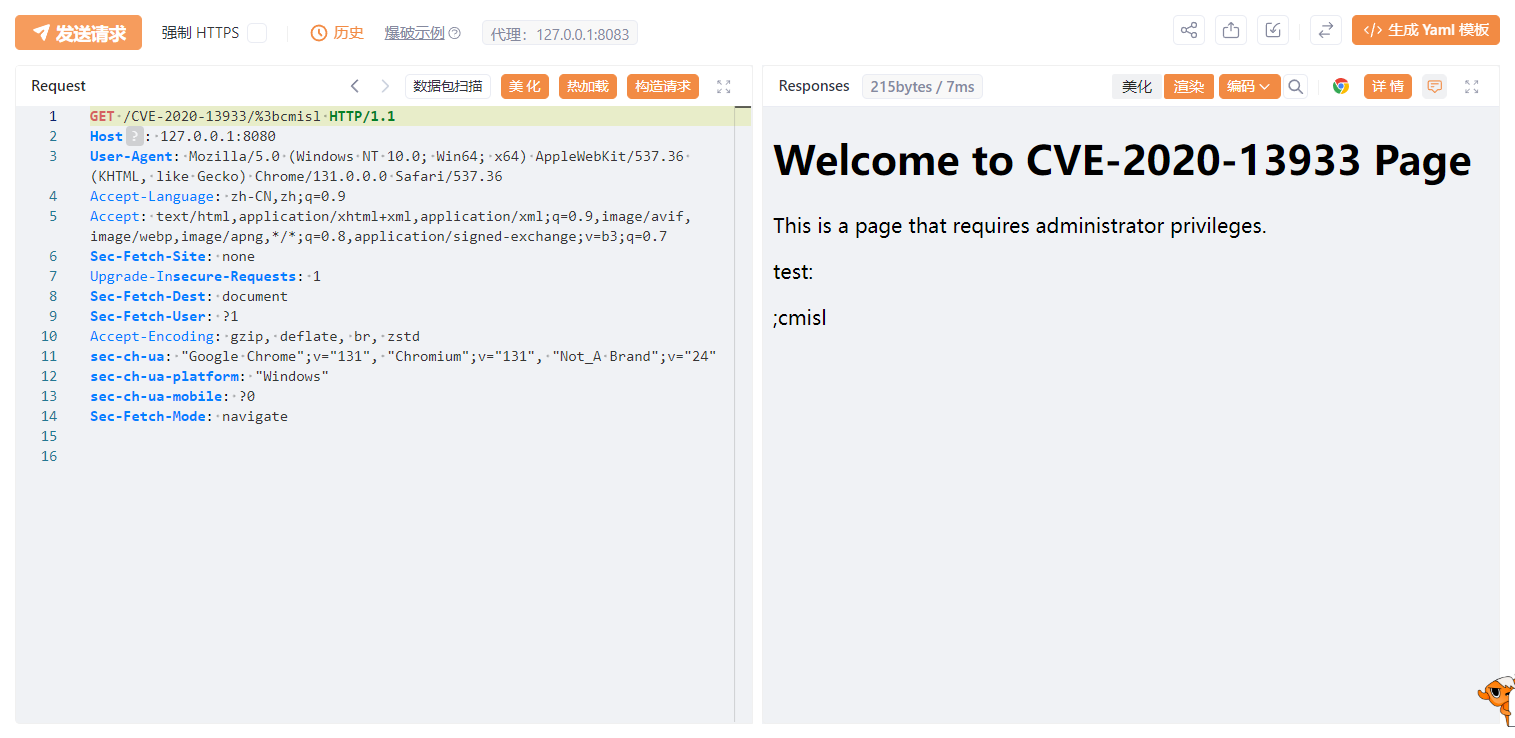
漏洞分析
我们从上一个漏洞修复中知道,WebUtils#getPathWithinApplication方法采用了getServletPath加getPathInfo方法拼接路径,然后用removeSemicolon方法移除分号,最后normalize方法进行规范化得到Shiro将要匹配的请求URI。
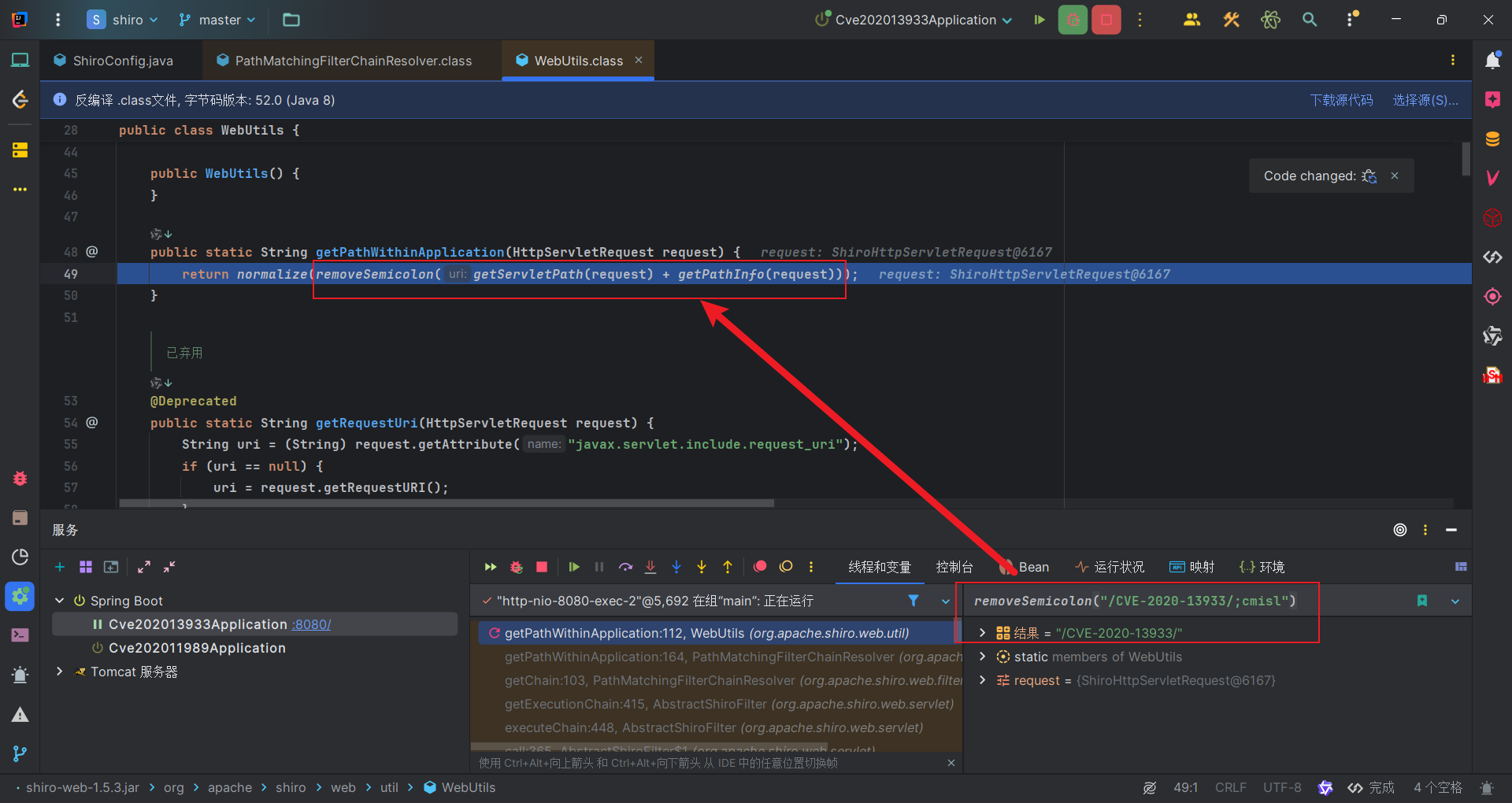
而从上个漏洞的分析中,我们可以知道getServletPath方法获取ServletPath时会进行URL解码,因此我们访问的URI路径/CVE-2020-13933/%3bcmisl经过获取拼接后得到的是/CVE-2020-13933/;cmisl,然后交给removeSemicolon方法处理。
将分号及其后面的内容都去除,返回/CVE-2020-13933/。
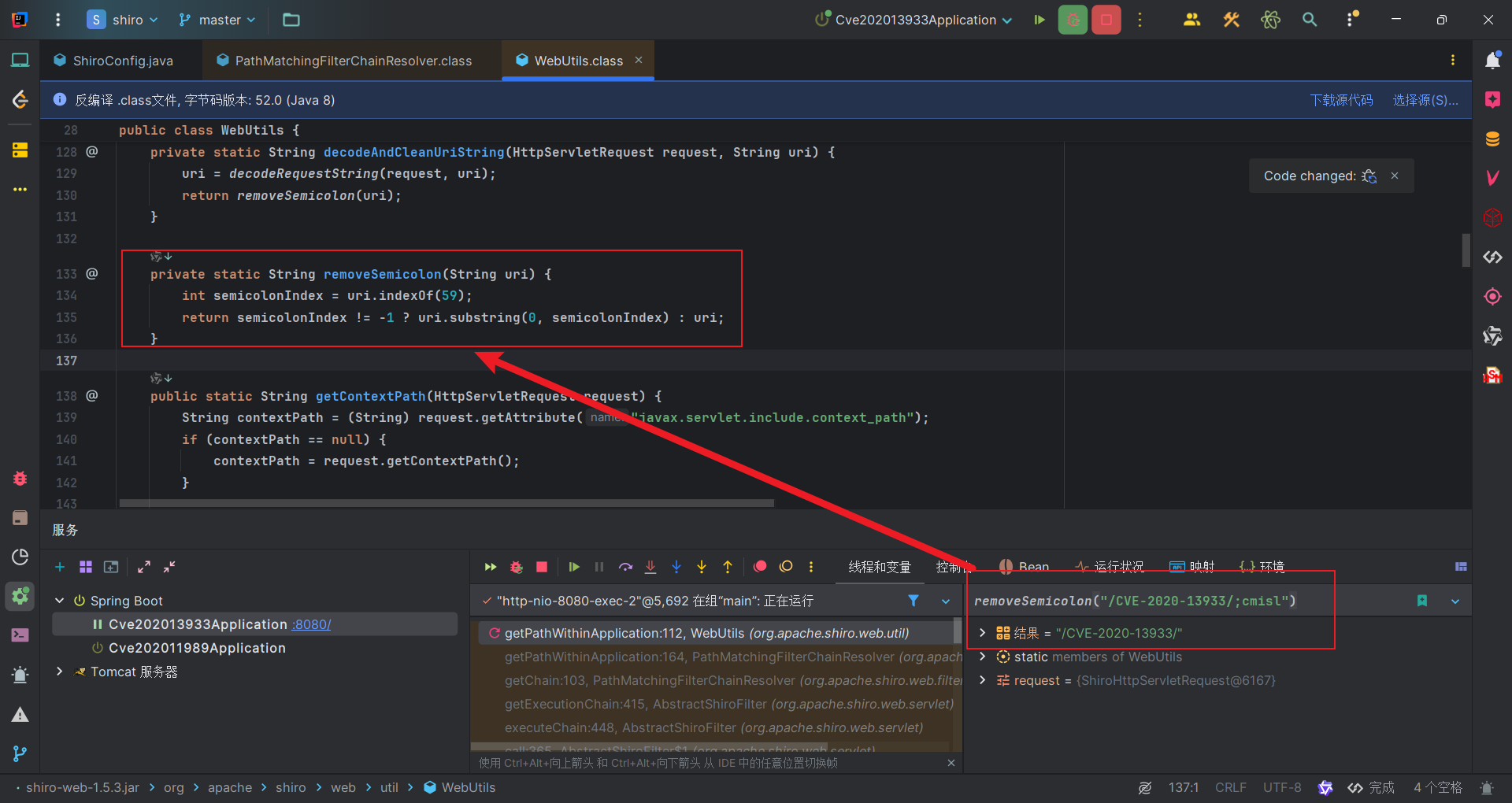
返回后在匹配前会判断URI是否是分隔符/结尾,如果是的话就会去掉分隔符。然后得到的是/CVE-2020-13933。我们的拦截规则是/CVE-2020-13933/*,无法匹配。
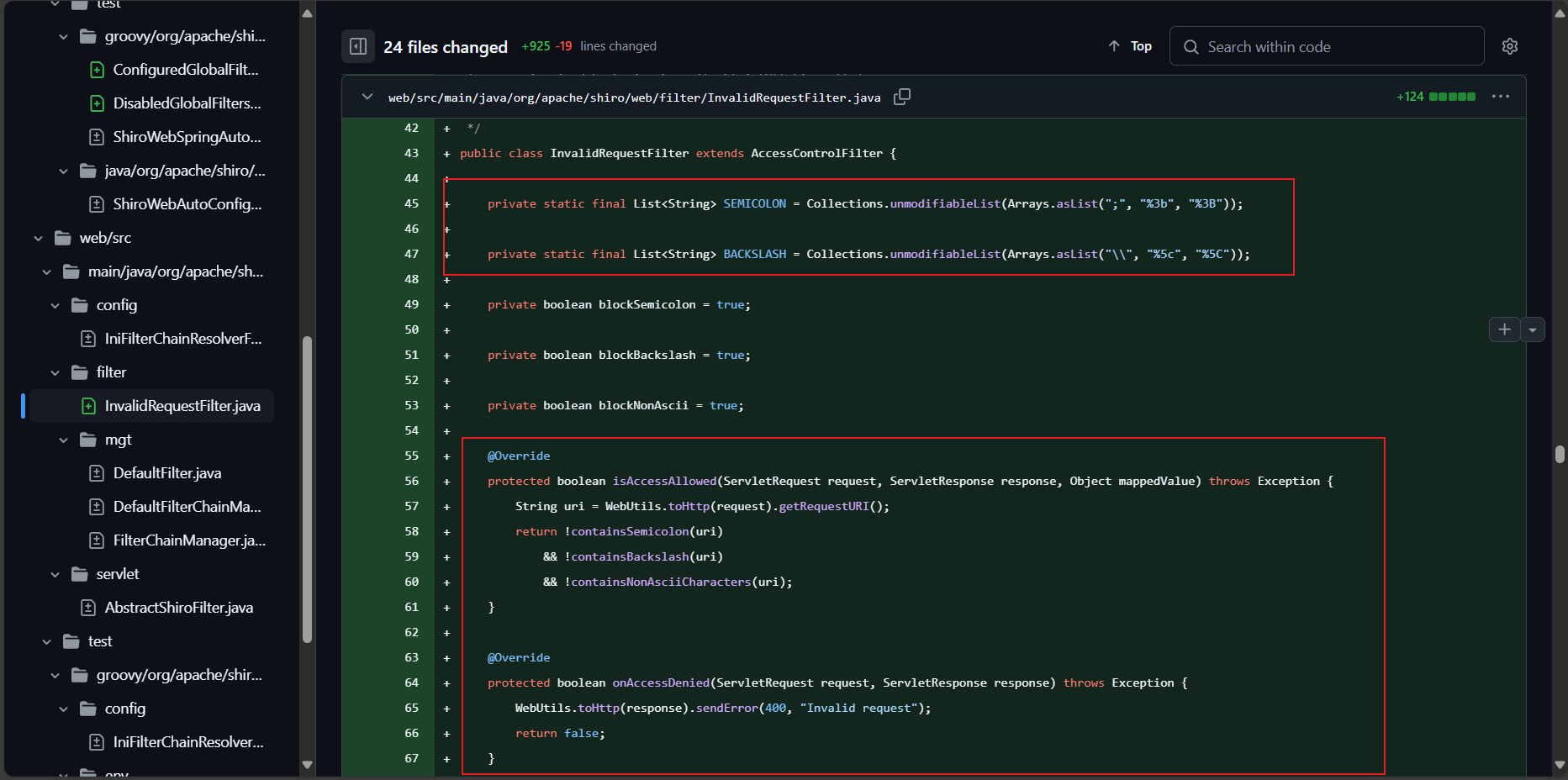
漏洞修复
设置了一个全局过滤器InvalidRequestFilter,主要检测分号和反斜杠以及非ASCII码字符。
参考链接
shiro CVE-2020-11989&CVE-2020-13933复现分析 - 先知社区
CVE-2020-17510
Apache Shiro before 1.7.0, when using Apache Shiro with Spring, a specially crafted HTTP request may cause an authentication bypass.
If you are NOT using Shiro’s Spring Boot Starter (
shiro-spring-boot-web-starter), you must configure add theShiroRequestMappingConfigautoconfiguration to your application or configure the equivalent manually.
漏洞信息
影响版本:shiro < 1.7.0
漏洞成因:Shiro与Spring处理含有%2e路径的差异化导致的绕过。
漏洞补丁:Add ShiroUrlHelper and related Spring configuration · apache/shiro@6acaaee
漏洞环境
1 | <!--shiro-spring--> |
添加接口
1 |
|
权限路径配置:
1 | Map<String, String> filterChainDefinitionMap = new LinkedHashMap<>(); |
漏洞复现
正常访问会302跳转:
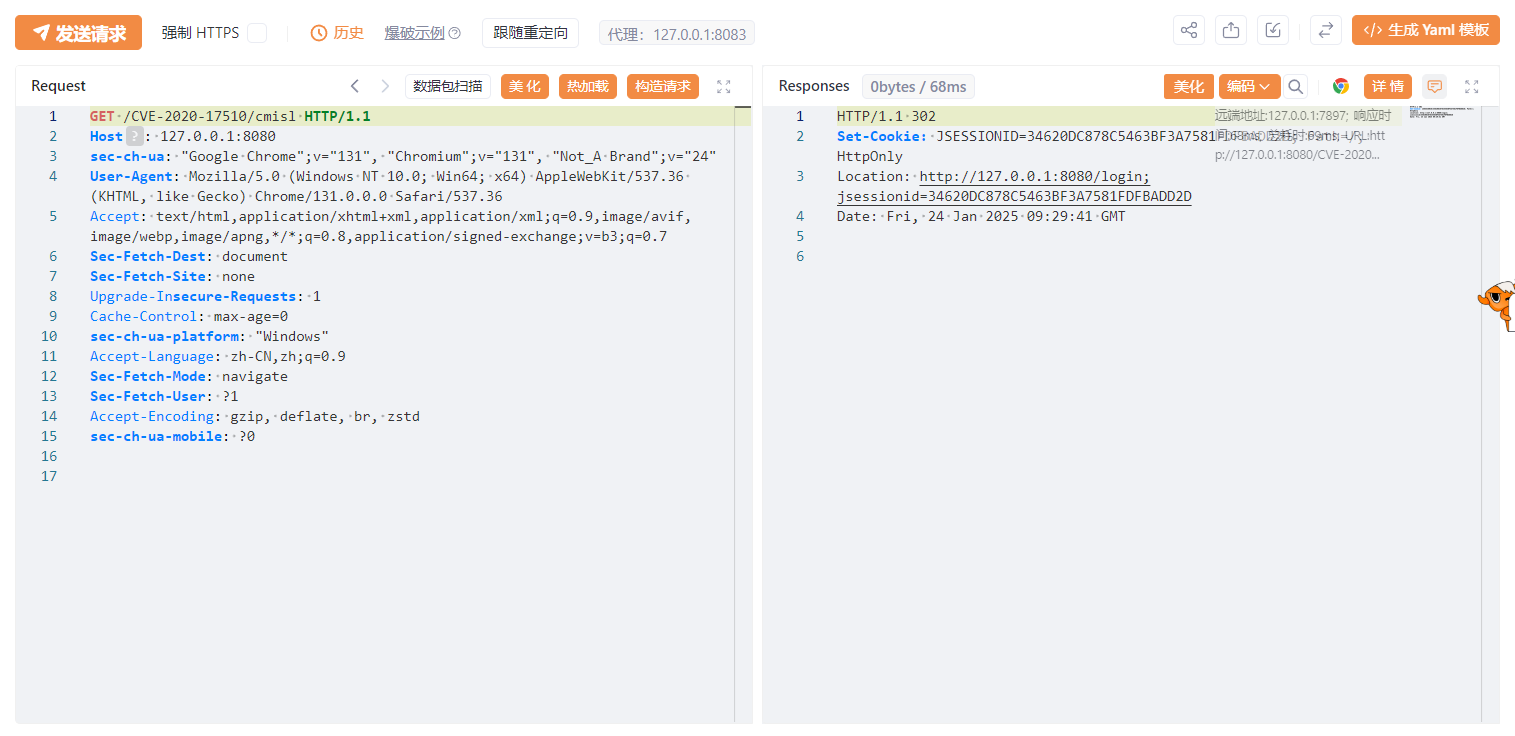
访问/CVE-2020-17510/%2e,可以访问到需要权限的页面:

漏洞分析
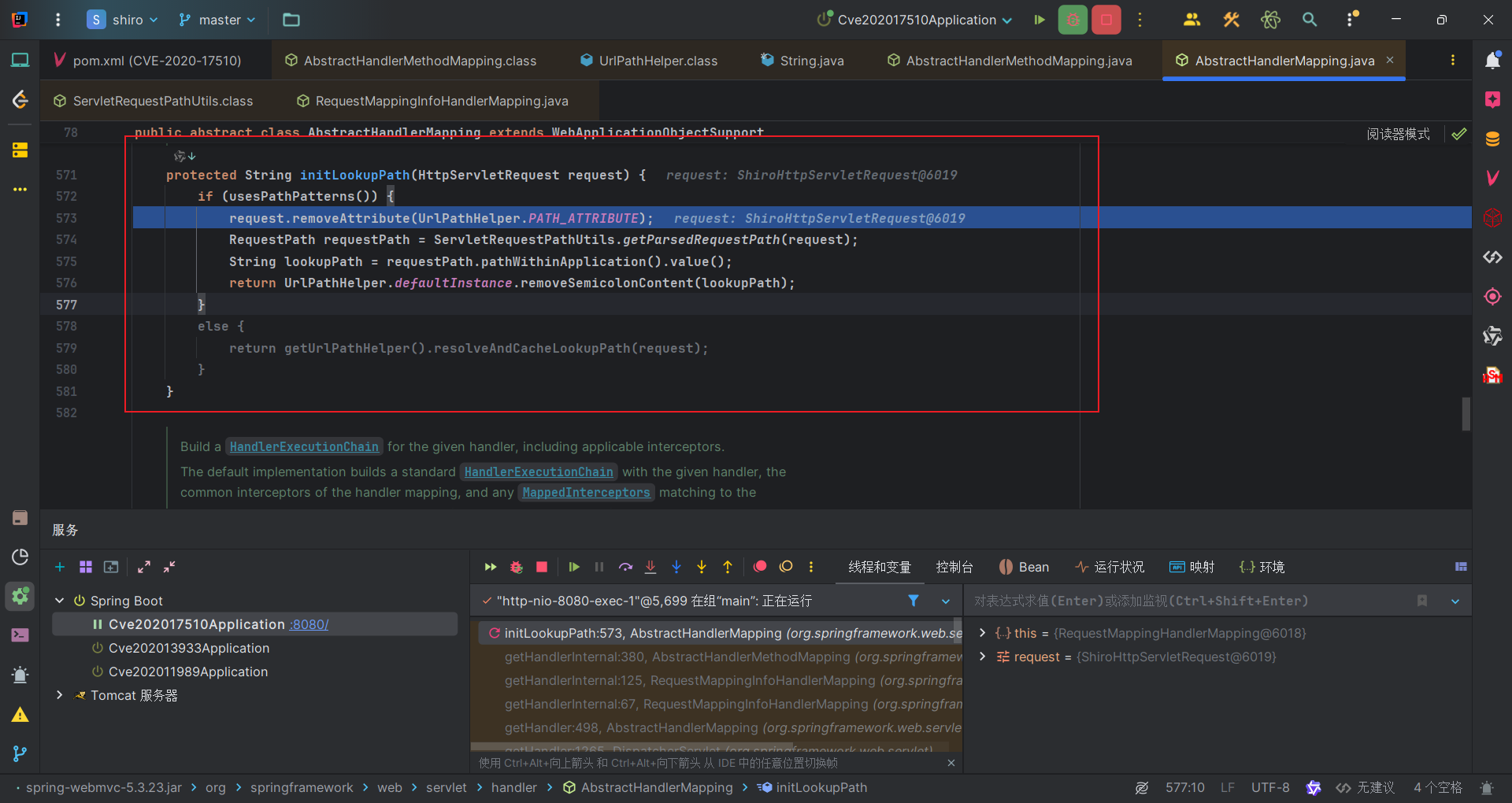
和前两个漏洞类似,和Shiro与Spring处理URI的差异性有关。那么还是先看Shiro部分的。和之前一样在WebUtils#getPathWithinApplication中,获取ServletPath和PathInfo拼接,去掉分号部分后规范化。
在前面我们知道ServletPath是经过URL解码和处理过后的。因此我们的访问URI,/CVE-2020-17510/%2e,在Shiro的获取中如下:
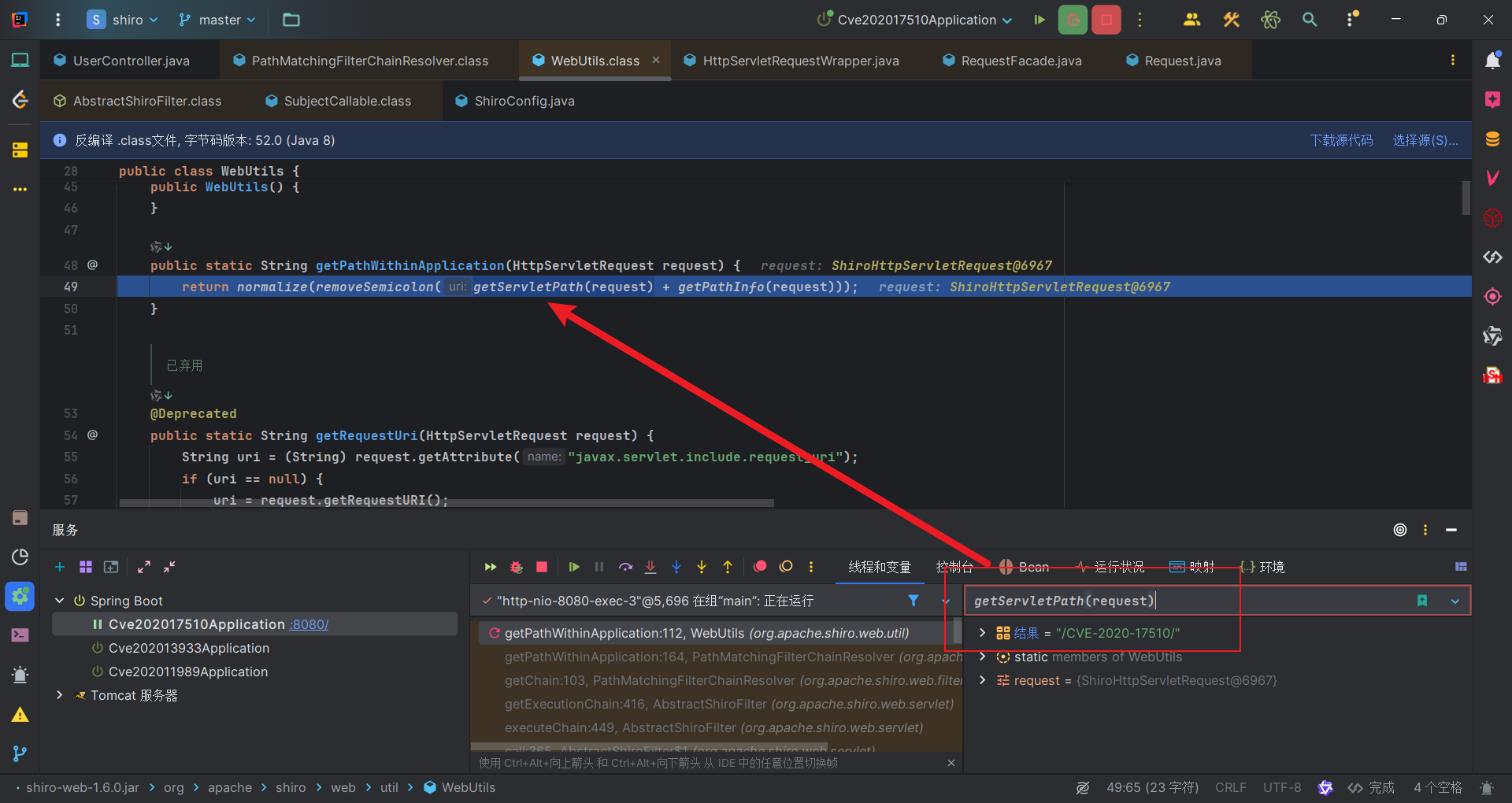
可以看到Shiro得到的ServletPath是/CVE-2020-17510/,后续处理返回的也是这个,然后返回到PathMatchingFilterChainResolver#getChain中,最后以斜杠结尾则去掉斜杠,得到我们访问URI是/CVE-2020-17510,这显然与规则/CVE-2020-17510/*不匹配的。
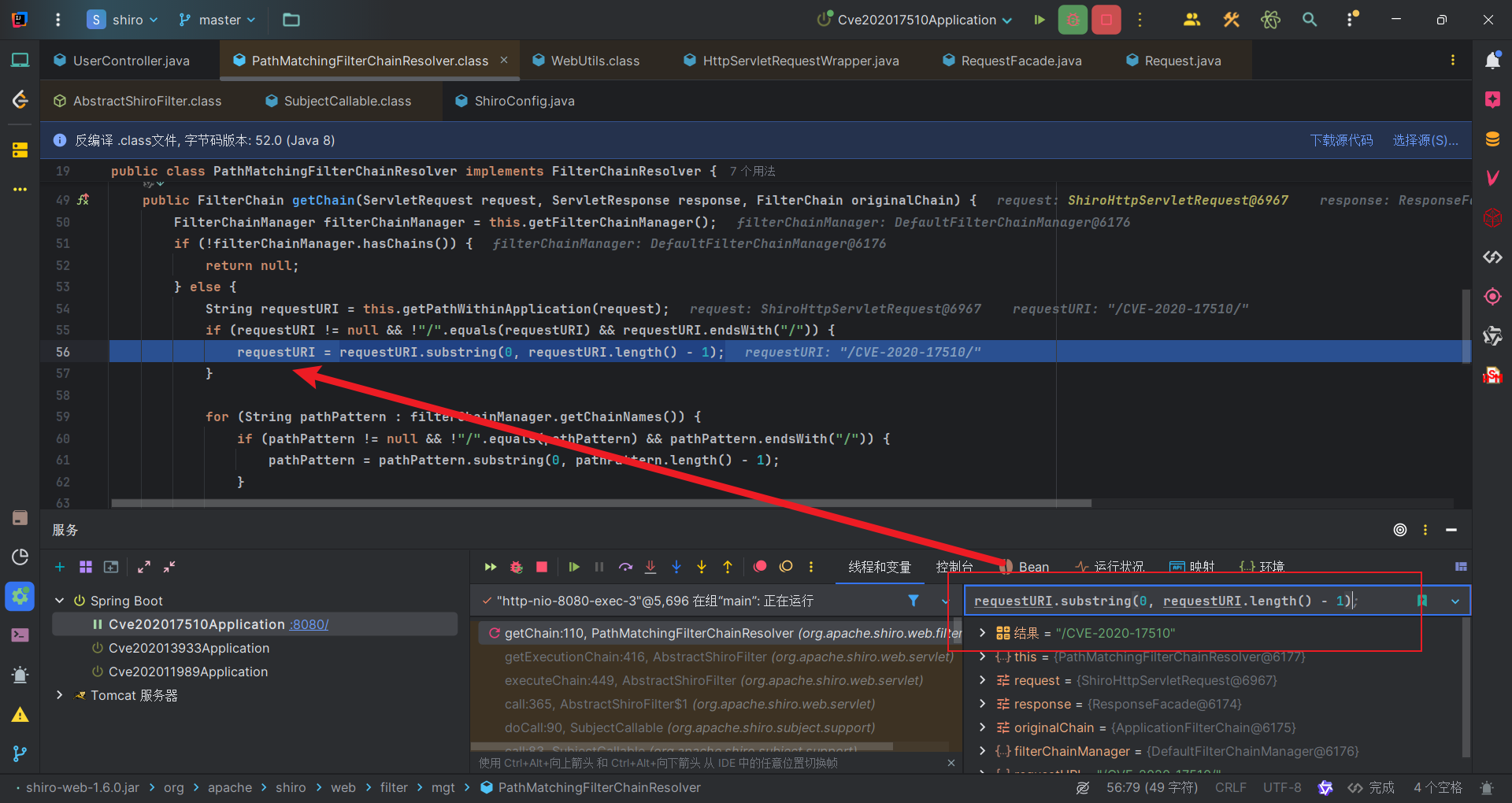
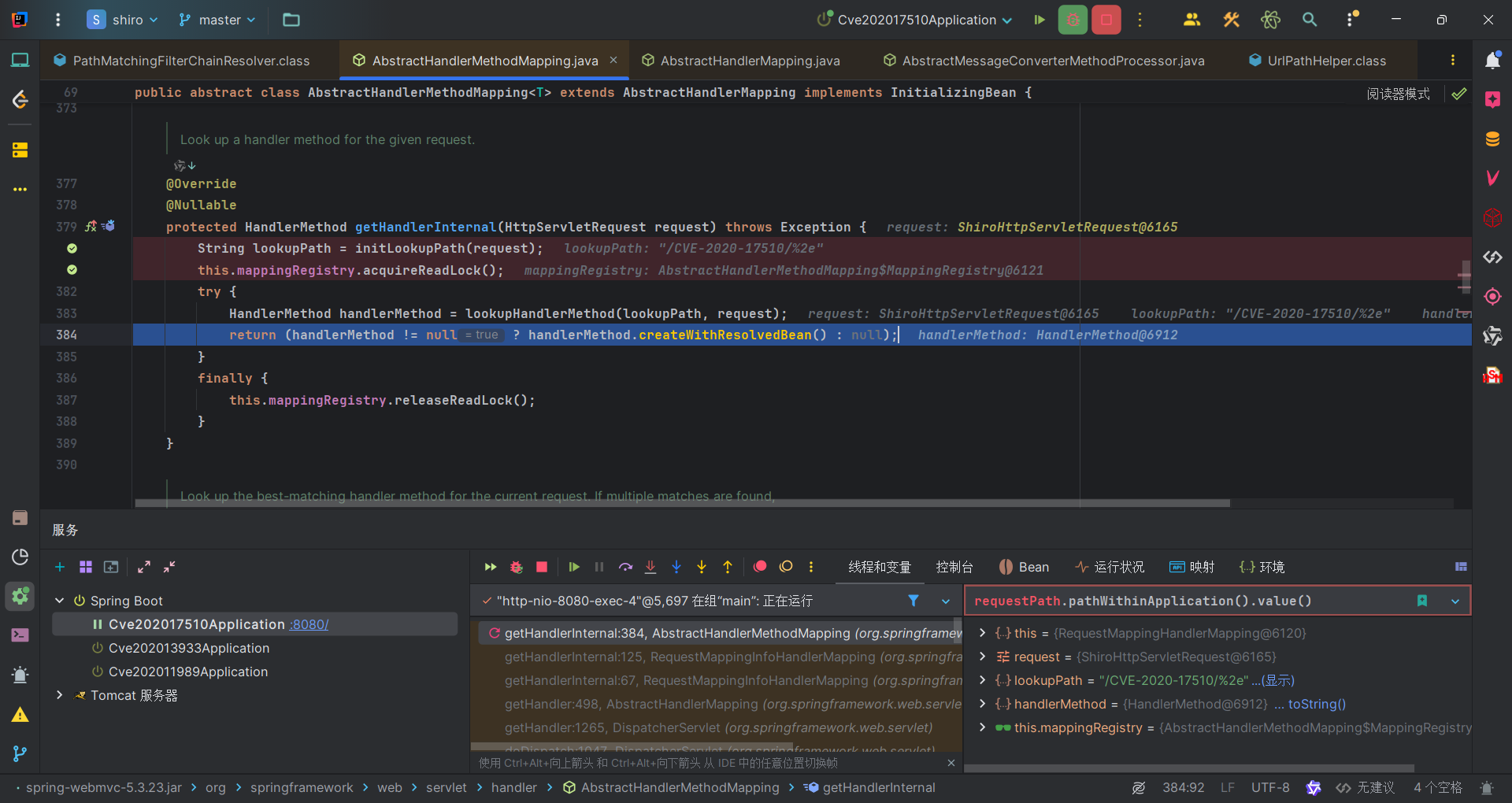
而对于Spring,获得的URI就是/CVE-2020-17510/%2e,因此它会找到对应URI的方法获取资源。
除此之外的payload还有
1 | /CVE-2020-17510/. |
%2e%2e相关的payload可以用的原因是,请求的ServletPath会被处理成根目录,也就是/,自然不会被匹配拦截。
该漏洞需要版本要求:springboot > 2.3.0
当Spring Boot版本在小于等于2.3.0.RELEASE的情况下,
alwaysUseFullPath为默认值false,这会使得其获取ServletPath,所以在路由匹配时相当于会进行路径标准化包括对%2e解码以及处理跨目录

由于小于等于2.3.0.RELEASE的SpringBoot版本alwaysUseFullPath为默认值false,因此会获取 Servlet 映射内的路径,也就是getPathWithinServletMapping方法。具体如下:
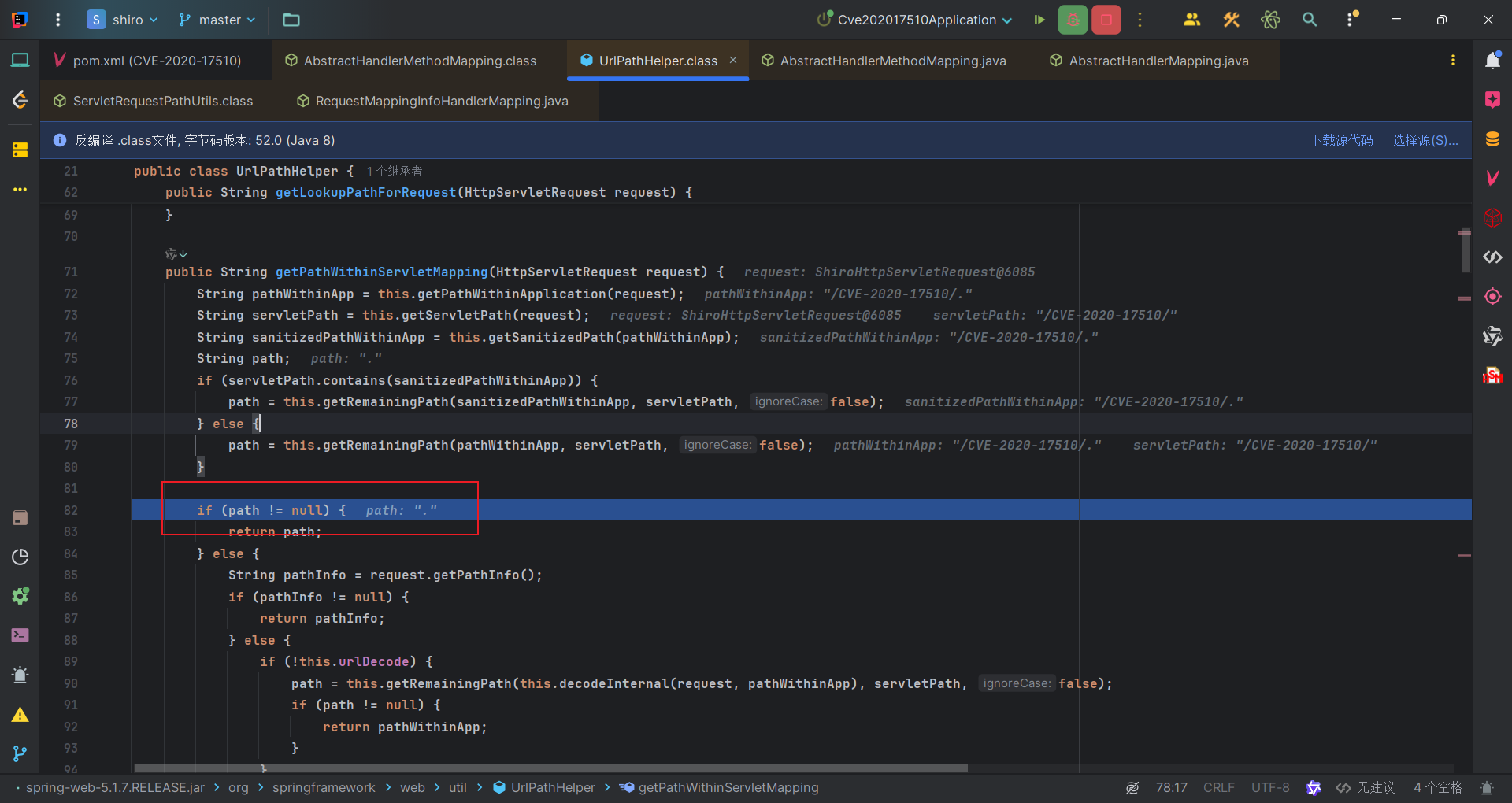
可以看到/CVE-2020-17510/.会先获取应用内的路径 /CVE-2020-17510/.和Servlet路径/CVE-2020-17510,然后将Servlet路径清理后,与应用内路径匹配,得到剩余路径.。
而如果alwaysUseFullPath为true,那么即使Spring Boot版本在小于等于2.3.0.RELEASE也能出现该漏洞。
漏洞修复
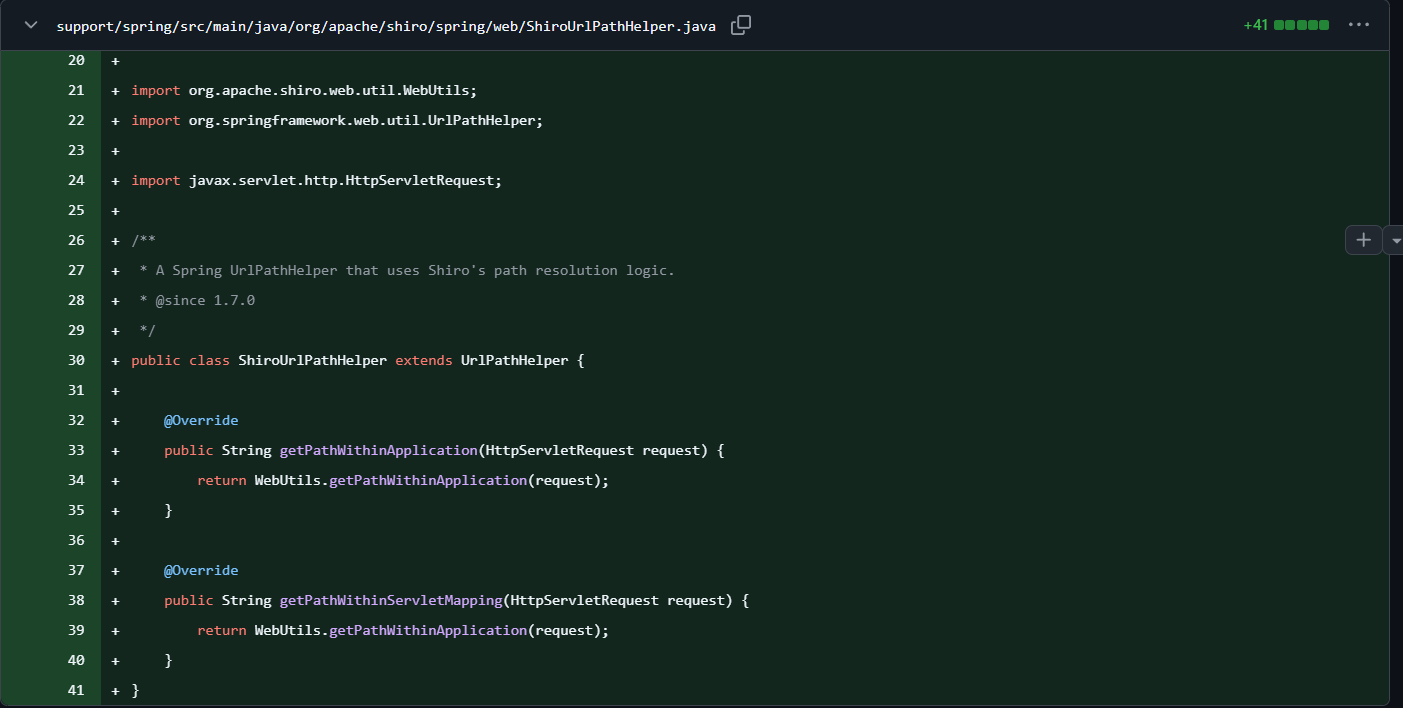
Shiro新增了一个ShiroUrlPathHelper类,是UrlPathHelper的子类,重写了 getPathWithinApplication 和 getPathWithinServletMapping两个方法,也就是让Spring处理URI的方式用了和Shiro一样的WebUtils#getPathWithinApplication方法。让Shiro和Spring以相同的方式处理URI,避免差异化导致的问题。
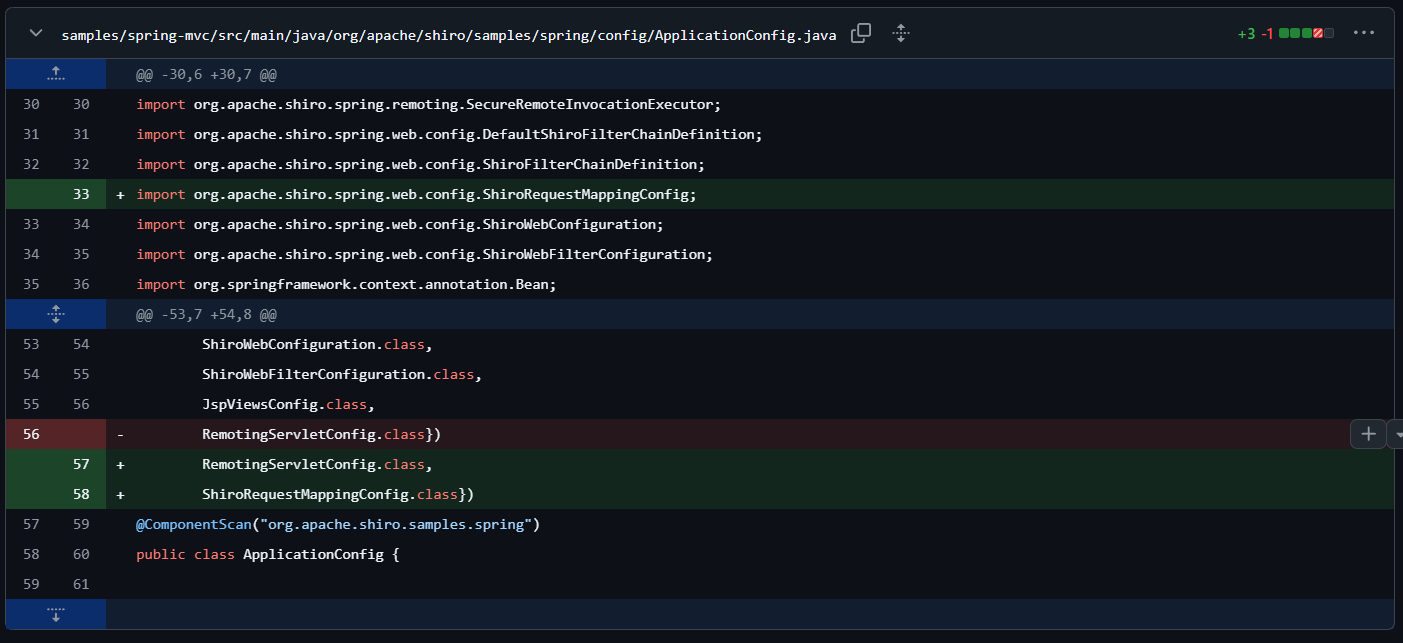
在配置类import导入了ShiroRequestMappingConfig类。
这个类就会将RequestMappingHandlerMapping#urlPathHelper设置ShiroUrlPathHelper。使得Spring会用ShiroUrlPathHelper类,也就是Shiro的处理方式去处理路径。
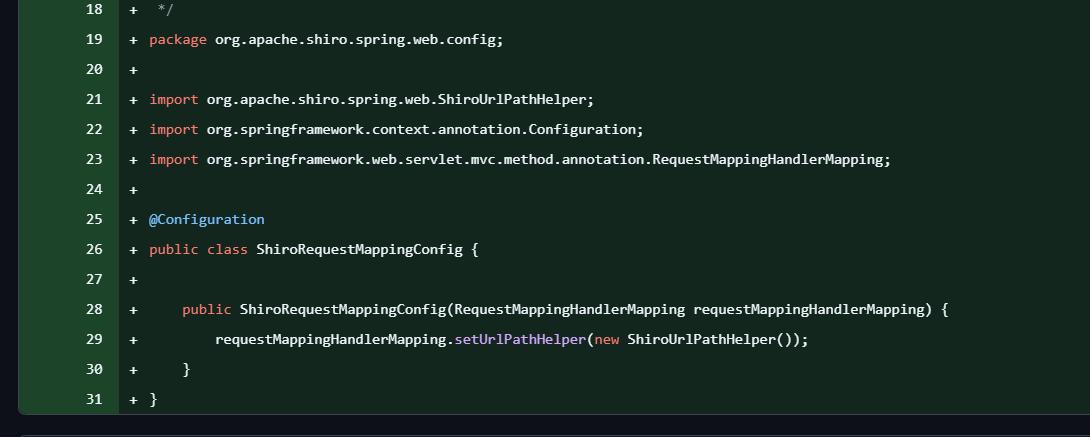
看起来修复的很完美,但在Spring的高版本中,patternParser默认值是true,因此会走默认的UrlPathHelper.defaultInstance来处理,而不是ShiroUrlPathHelper。
所以这个漏洞不能Spring版本太高或太低,如果太低,由于alwaysUseFullPath为false会获得Servlet路径清洗处理后的剩余路径。如果版本太高,又会因为patternParser默认值是true走走默认的UrlPathHelper.defaultInstance。
参考链接
Spring Boot中关于%2e的Trick - Ruilin
CVE-2020-17523
漏洞信息
影响版本:`shiro < 1.7.1
漏洞成因:Shiro匹配URI对应过滤器时对含有%20路径的处理存在绕过。
漏洞补丁:Improving tests for path matching logic · apache/shiro@ab1ea4a
漏洞环境
1 | <!--shiro-spring--> |
添加接口
1 |
|
权限路径配置:
1 | Map<String, String> filterChainDefinitionMap = new LinkedHashMap<>(); |
漏洞复现
和之前一样正常访问302跳转:
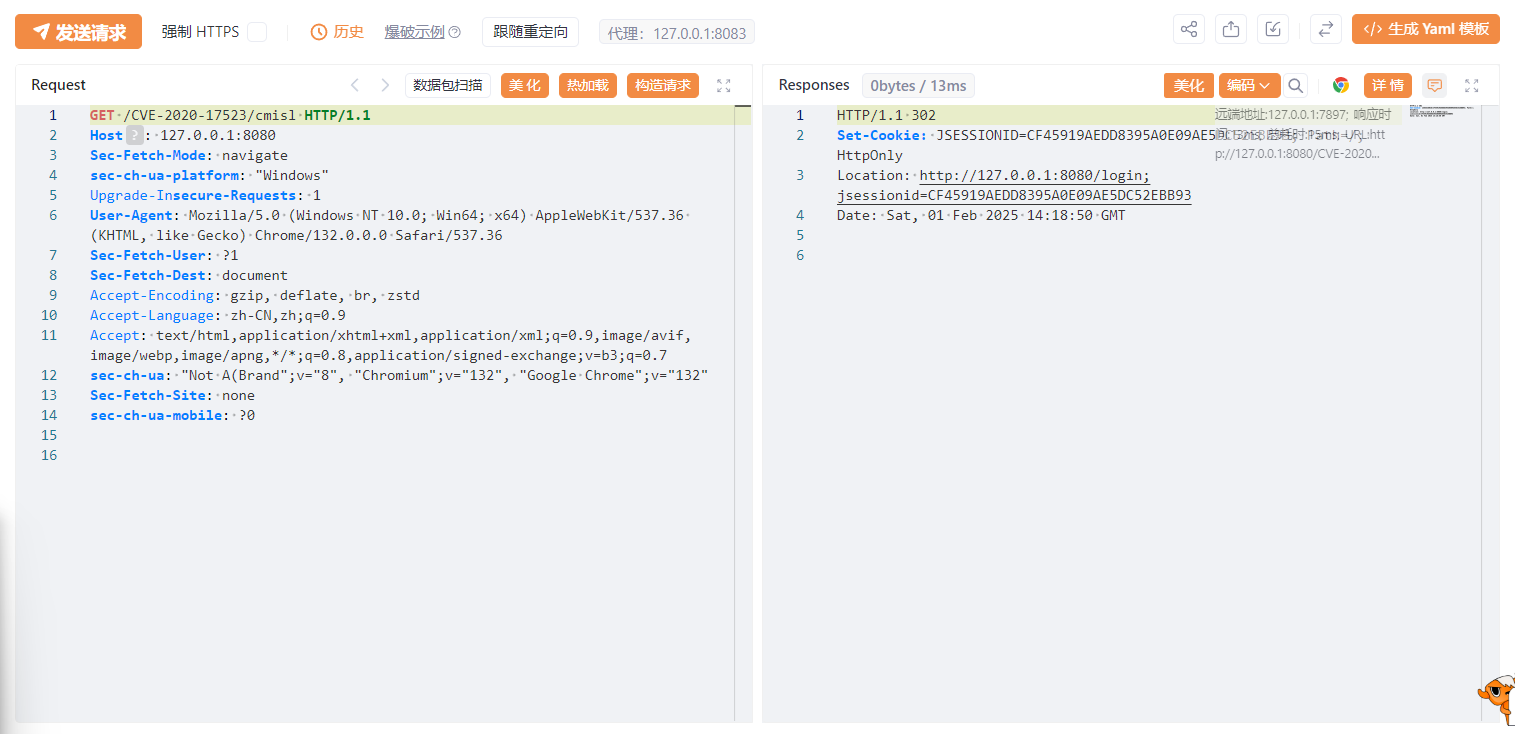
但是访问/CVE-2020-17523/%20,可以访问到需要权限的页面:

漏洞分析
首先看Shiro处理后的路径是什么,还是来到熟悉的PathMatchingFilterChainResolver#getChain方法中。Shiro得到的路径是/CVE-2020-17523/ 。因为会URL解码,之前已经了解过。
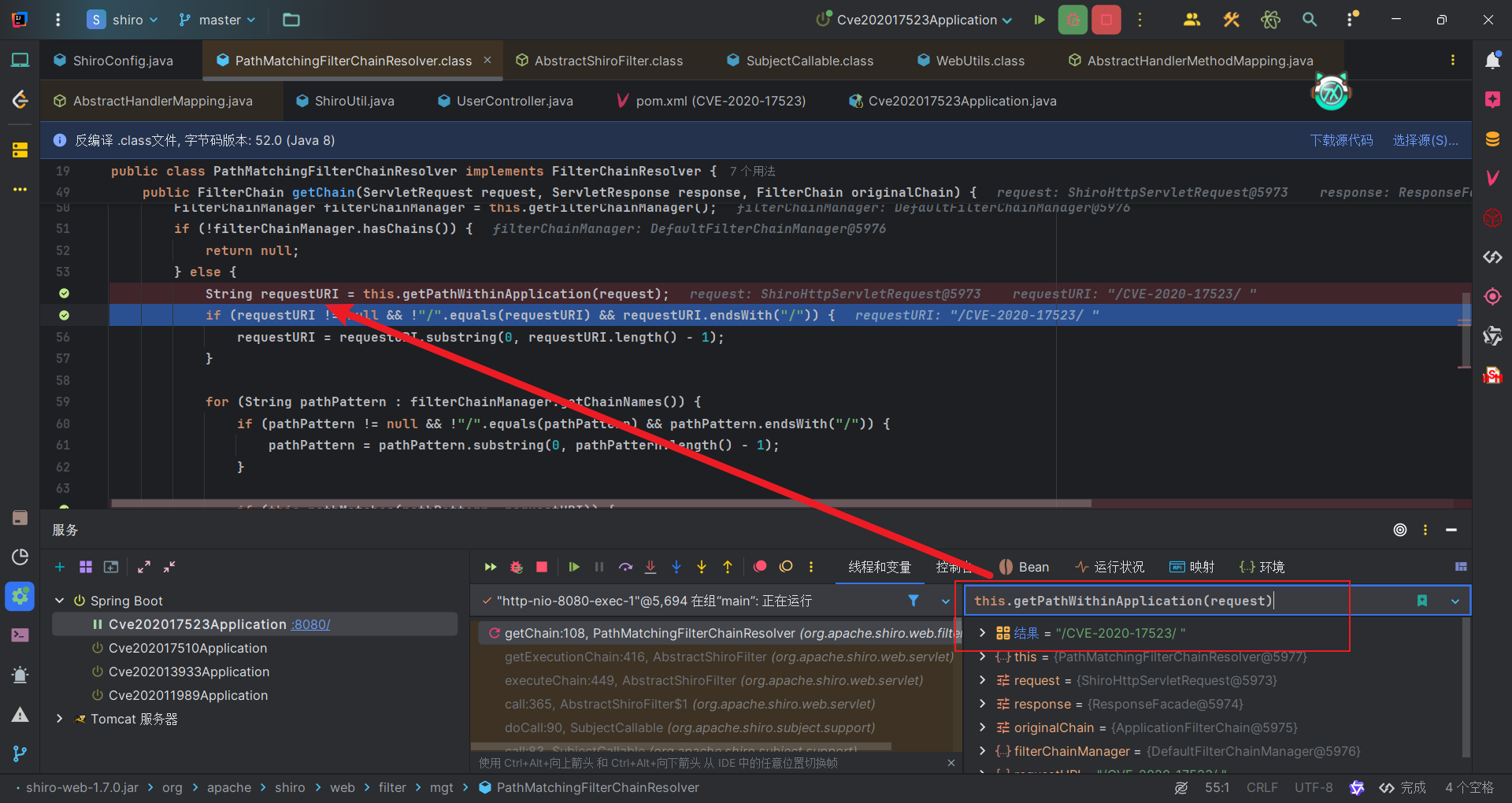
而Shiro得到的/CVE-2020-17523/ 为什么与规则匹配不上,我们可以跟进到AntPathMatcher#doMatch。具体调用堆栈如下:
1 | doMatch:109, AntPathMatcher (org.apache.shiro.util) |
会将得到的URI和拦截规则都处理成字符串数组,而对于该处理方法,/CVE-2020-17523/ 和/CVE-2020-17523是等价的。因此可以认为,Shiro虽然得到的是/CVE-2020-17523/ ,但是在后续匹配过程中,在匹配方法中认为的URI就是/CVE-2020-17523。因此匹配不上也是很自然的事情了。

而这个具体的处理方法,将URI根据分隔符斜杠分割成一个个token,/CVE-2020-17523/ 就会被分割成CVE-2020-17523和空格,每个token会用trim函数处理,也就是去掉首尾空格,第二个token由于就是一个空格,因此处理之后就没有字符了,因此无法添加到tokens中,后续将tokens转成字符数组也就没有第二个token了,因此只剩下了CVE-2020-17523,所以返回的字符数组就只有CVE-2020-17523一个元素。
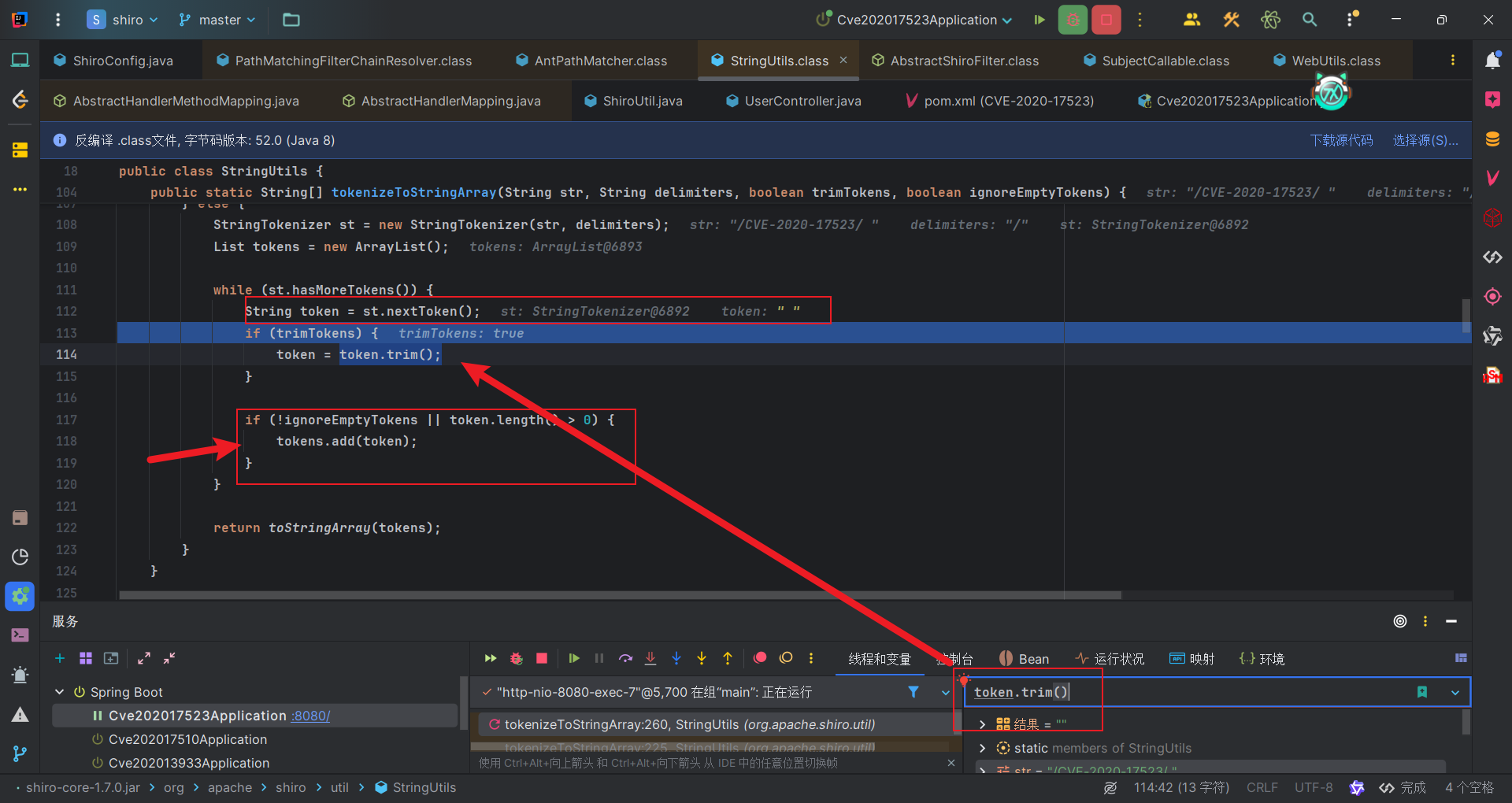
Spring虽然在上次补丁使用了Shiro的处理URI的方法,但是匹配Handler时并没有处理URI中的空格,所以访问的URI为/CVE-2020-17523/ 是可以获取资源的。
漏洞修复
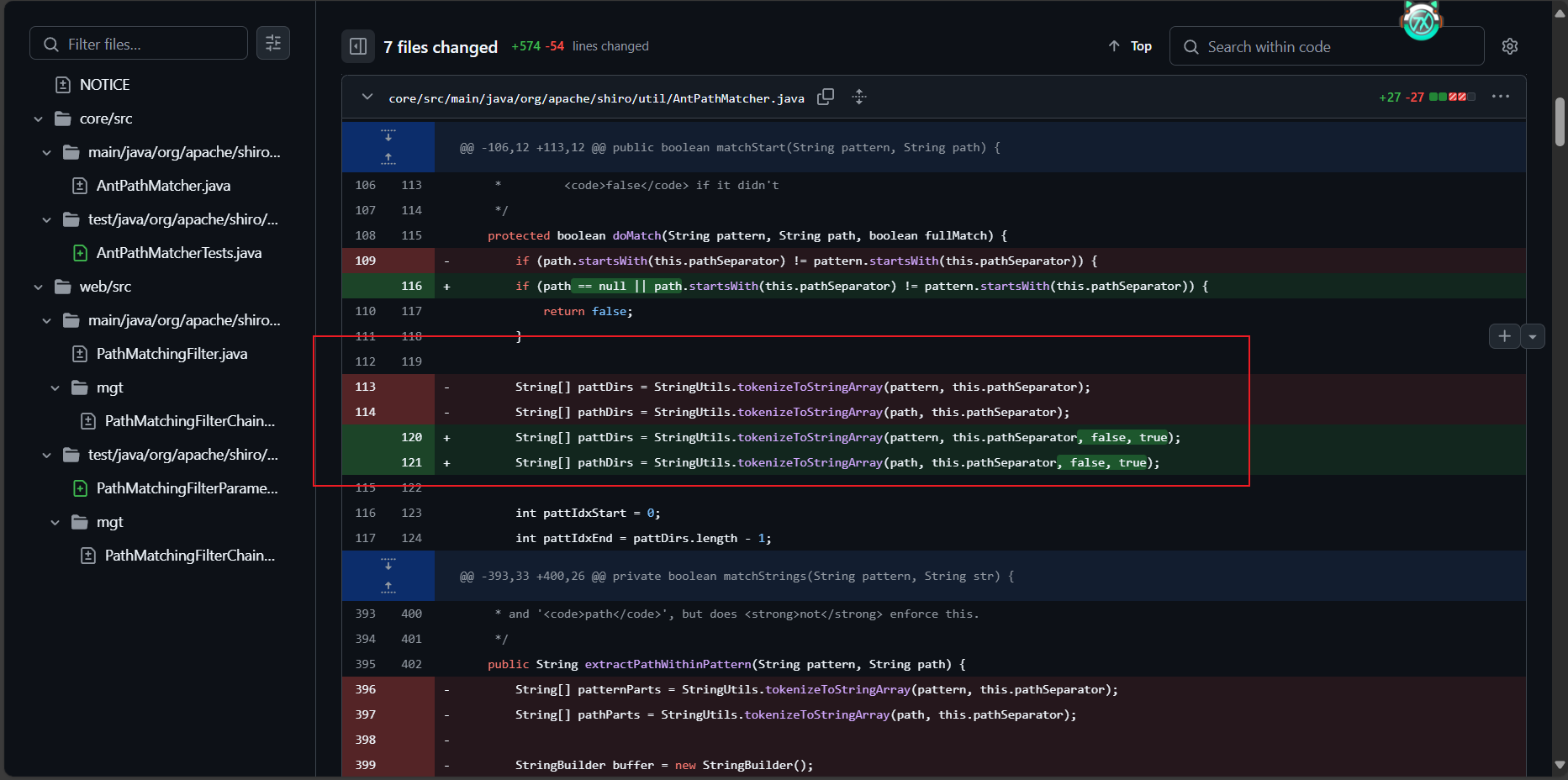
指定 StringUtils#tokenizeToStringArray 的第三个参数 trimTokens 为 false,就是不处理每个token的首尾空格了。
参考链接
CVE-2021-41303
Apache Shiro before 1.8.0, when using Apache Shiro with Spring Boot, a specially crafted HTTP request may cause an authentication bypass.
漏洞信息
影响版本:`shiro < 1.8.0
漏洞成因:误将处理后的URI作为拦截规则的过滤器添加进过滤链。
漏洞补丁:Backport SHIRO-825 · apache/shiro@4a20bf0
#### 漏洞环境
1 | <!--shiro-spring--> |
添加接口
1 |
|
权限路径配置:
1 | Map<String, String> filterChainDefinitionMap = new LinkedHashMap<>(); |
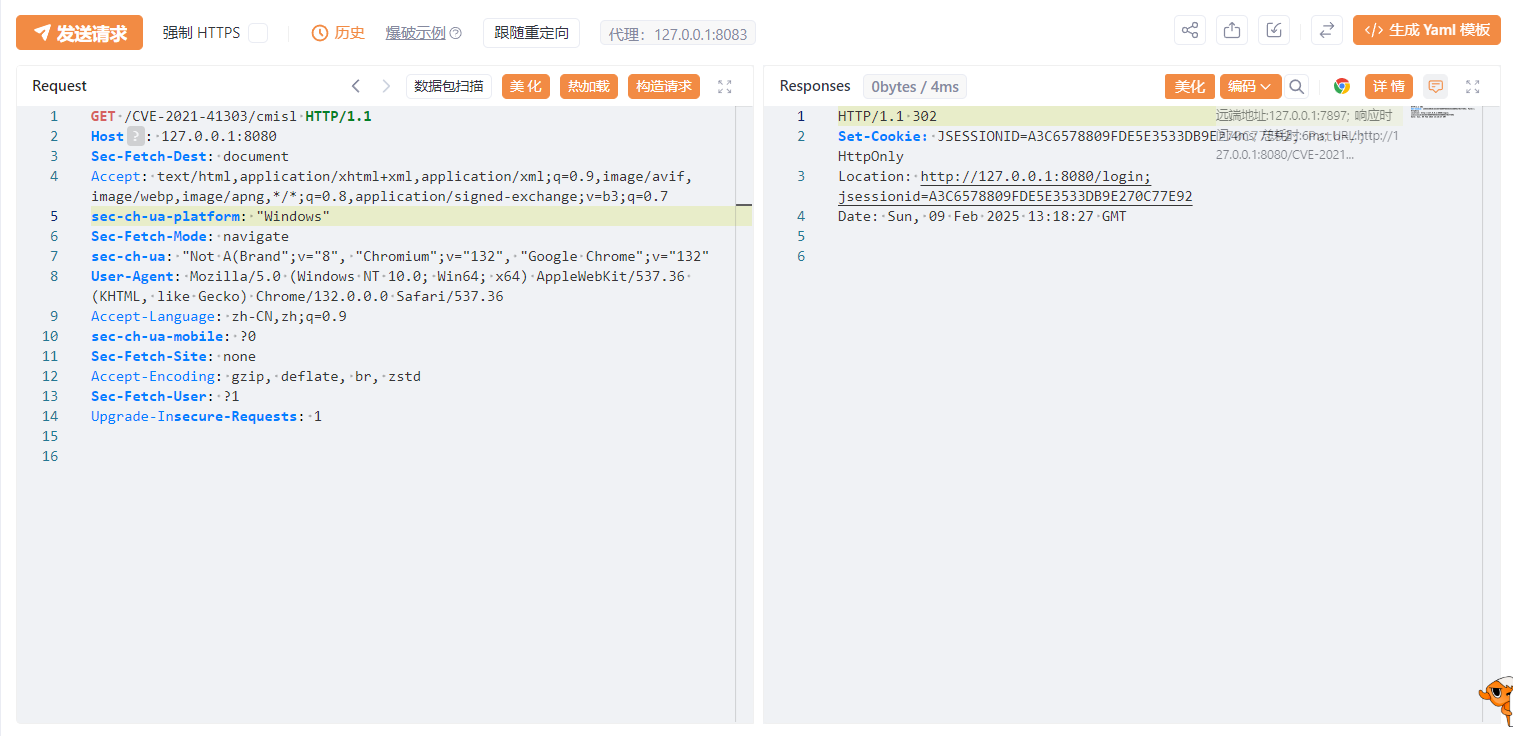
漏洞复现
访问/CVE-2021-41303/cmisl,302跳转到登录页面。
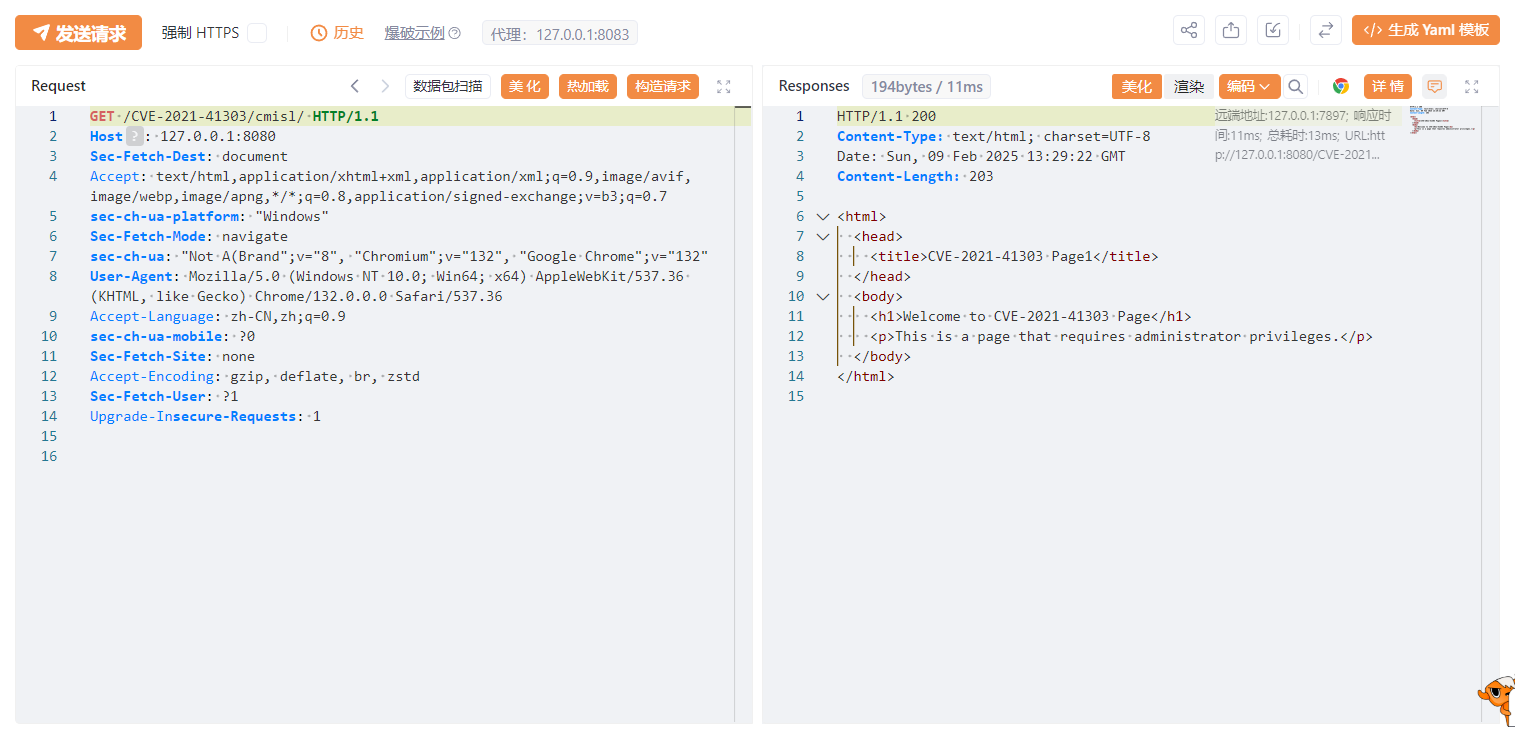
访问/CVE-2021-41303/cmisl/,可以访问到资源。
漏洞分析
还是看到PathMatchingFilterChainResolver#getChain方法,shiro1.7.0更新之后,该方法发生了一些变化,如下图,左边是Shiro1,.7.0,右边是Shiro1.7.1:
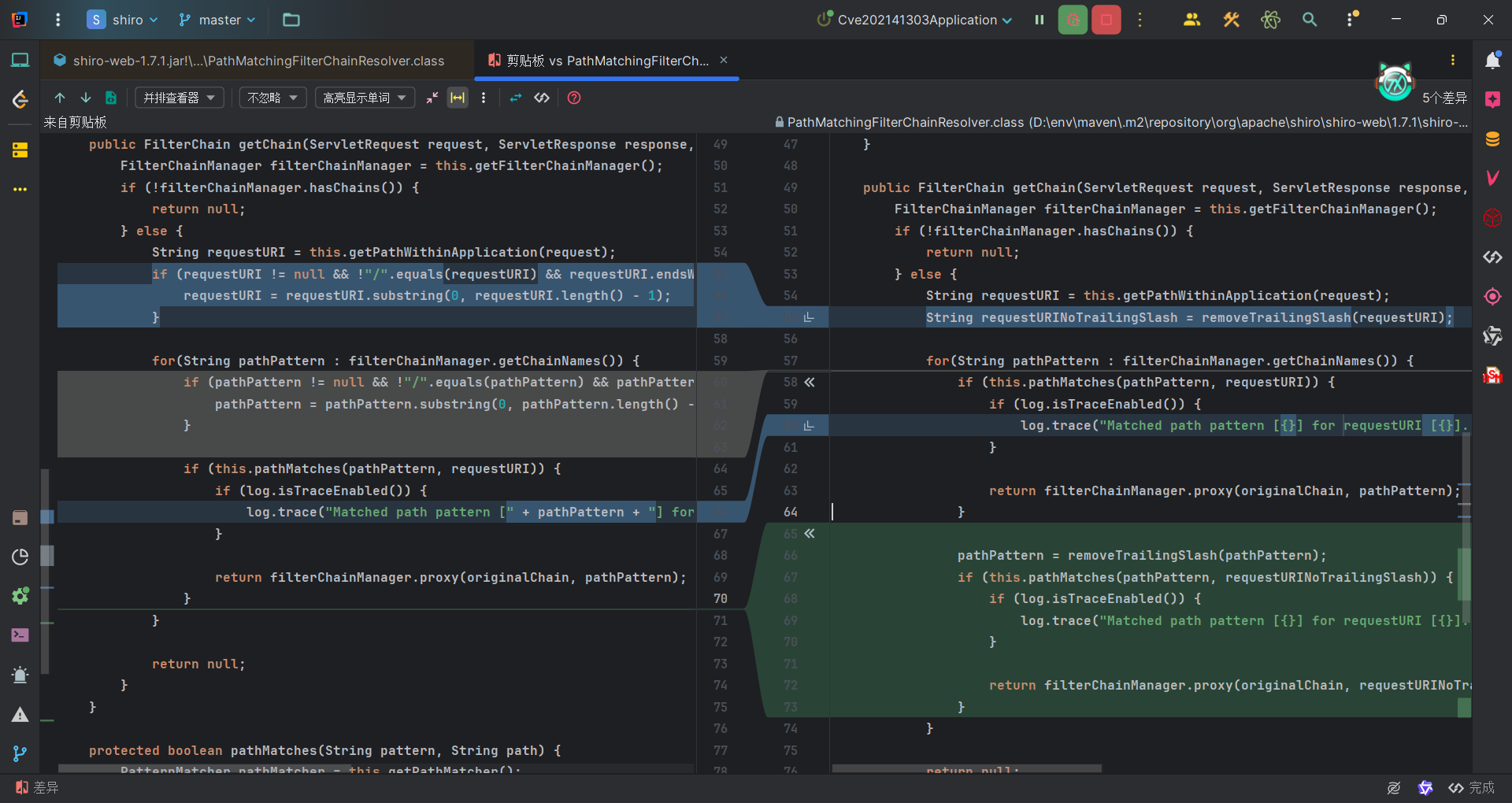
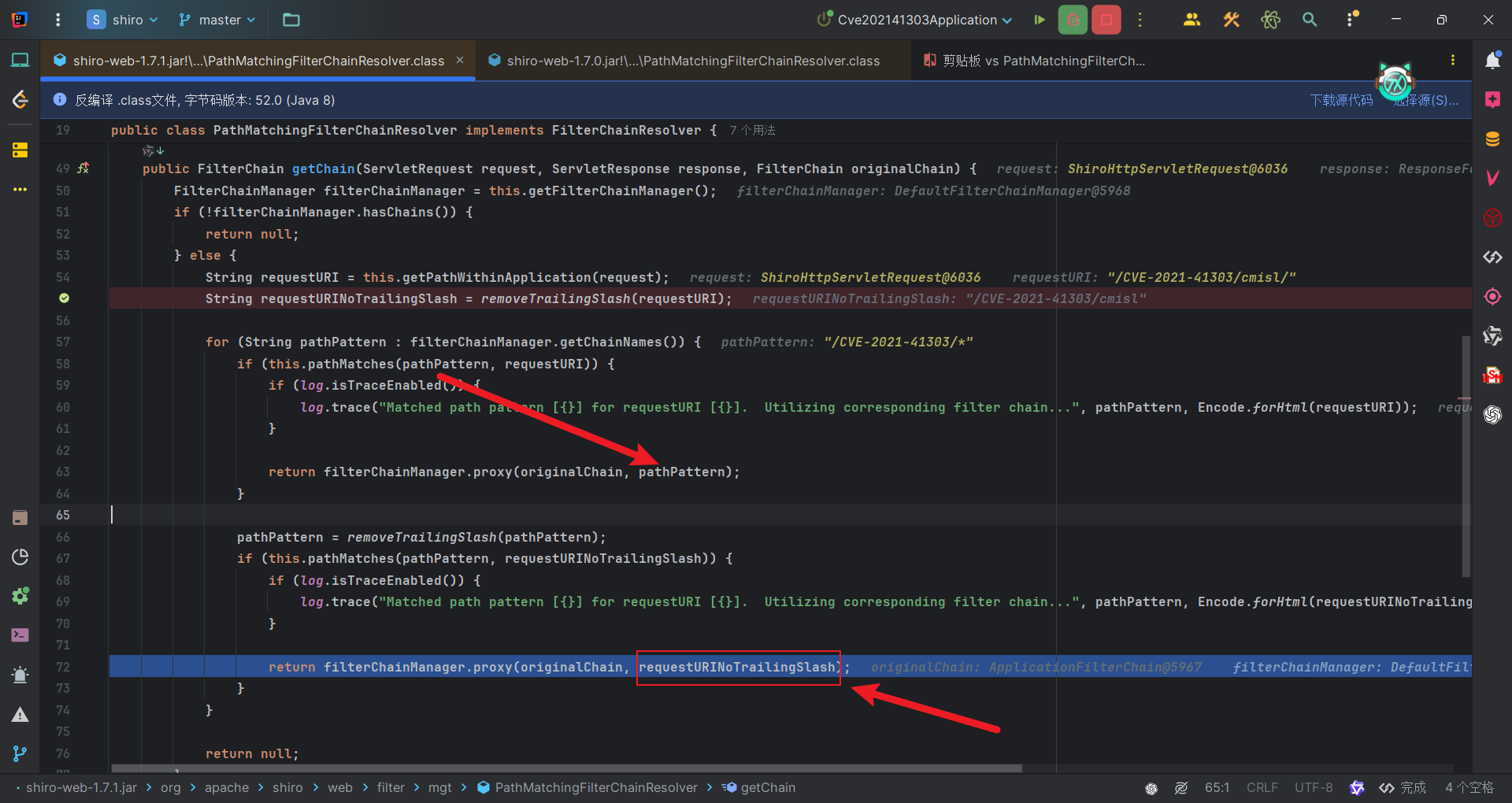
在原来的基础上添加了一层判断逻辑,原来的是先判断请求URI是否是 “/“结尾,如果是去掉 “/“再匹配,更新后的逻辑是,首先将请求URI直接匹配,如果匹配不上,在将经过removeTrailingSlash方法的URI进行匹配,这个方法就是去掉末尾的”/“。
而新增的代码其实就存在漏洞,仔细看就会发现,新增的代码中,如果匹配成功,添加的过滤器并不是匹配成功的结果,而是将经过removeTrailingSlash方法的URI作为过滤规则的过滤器添加到链中。
漏洞需要拦截规则如下:
1 | Map.put("/CVE-2021-41303/*", "authc, roles[admin]"); |
比如我们的请求URI是/CVE-2021-41303/cmisl/,此时我们会有一个原始的URI和一个处理后的/CVE-2021-41303/cmisl,首先/CVE-2021-41303/cmisl/与/CVE-2021-41303/*匹配失败,然后新增部分代码会用/CVE-2021-41303/cmisl与/CVE-2021-41303/*匹配,这是可以匹配上的。
因此按理说是可以匹配需要鉴权的规则,但是更新的代码问题,我们匹配上了/CVE-2021-41303/*,但是添加过滤器的时候,我们是将requestURINoTrailingSlash值作为拦截规则添加其对应的过滤器的,该值就是原始URI去掉”/“,也就是/CVE-2021-41303/cmisl,根据配置,该路径是可以匿名访问的。因此添加的是匿名过滤器,无需权限。

在我看来该漏洞意义并不大,既然拦截规则特地将/CVE-2021-41303/cmisl设置为匿名访问,那么在管理者看来,这个资源就是应该无需权限就可以访问的。
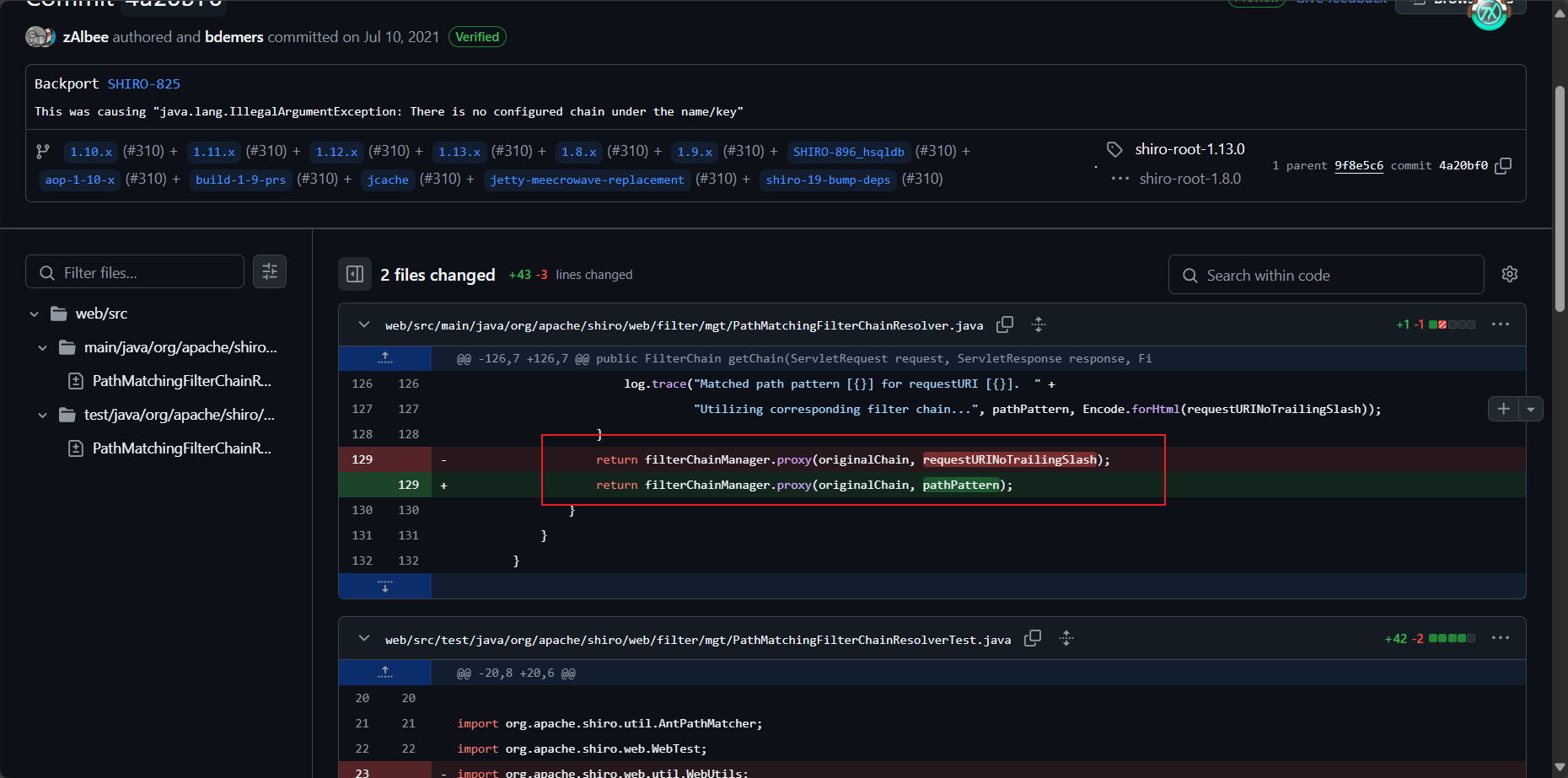
漏洞修复
通过上面分析就知道有问题的代码位置,那么修复也很简单,将匹配到的规则添加进过滤链即可。
CVE-2022-32532
Apache Shiro before 1.9.1, A RegexRequestMatcher can be misconfigured to be bypassed on some servlet containers. Applications using RegExPatternMatcher with
.in the regular expression are possibly vulnerable to an authorization bypass.
漏洞信息
影响版本:shiro < 1.9.1
漏洞成因:在1.9.1之前的Apache Shiro中,RegexRequestMatcher可能会在某些Servlet容器中被错误配置,从而导致绕过。使用包含.的正则表达式的RegExPatternMatcher的应用程序可能会面临授权绕过的风险。
漏洞补丁:Add support for case-insensitive matching to RegExPatternMatcher · apache/shiro@6bcb92e
漏洞环境
漏洞环境可以直接用4r1an师傅的:Lay0us/CVE-2022-32532: Apache Shiro CVE-2022-32532
1 | SecurityManager securityManager = this.getSecurityManager(); |
myFilter过滤器添加到匹配路径模式/permit/.*的过滤链中。设置了PathMatchingFilterChainResolver使用的路径匹配器为RegExPatternMatcher,它支持正则表达式匹配路径。因此所有以/permit/开头的URL请求都会经过myFilter过滤器。
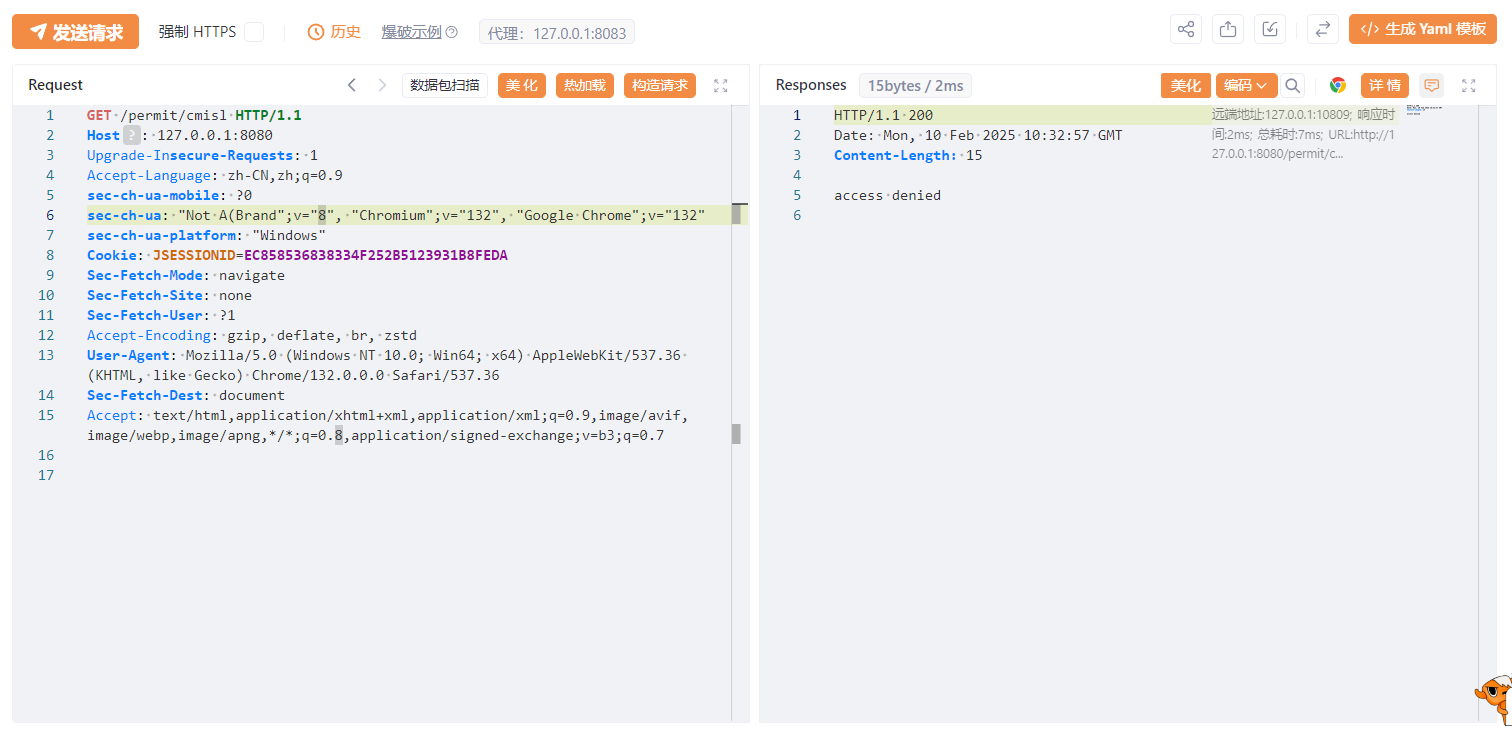
漏洞复现
直接访问/permit/cmisl,由于匹配上拦截规则,返回access denied表示没有权限。
访问/permit/cm%0aisl,发现返回success,表示访问到资源了。
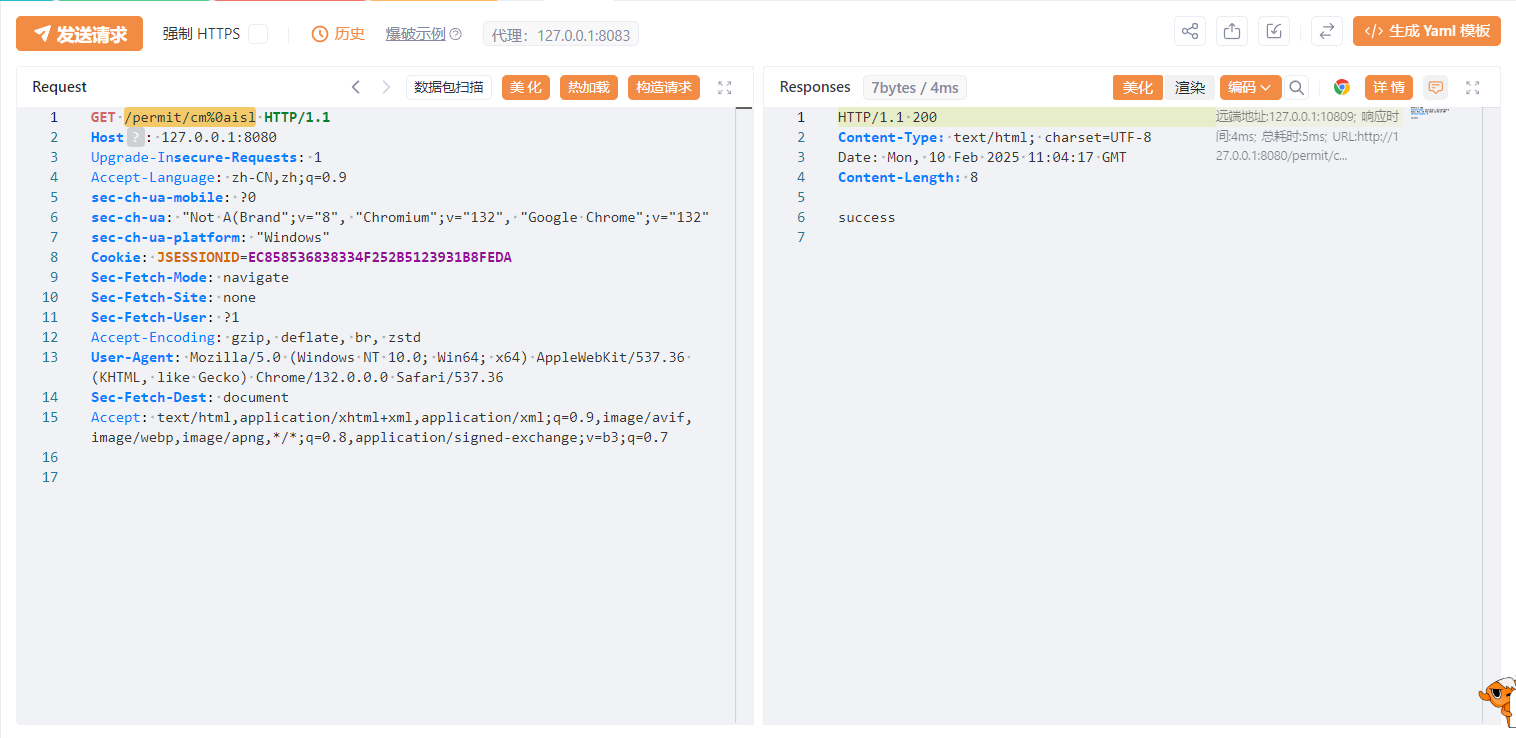
漏洞分析
我们先了解一下java中的正则匹配,因为漏洞原因出现在正则表达式模式匹配器。
Java中的正则默认情况下.并不包含\r和\n字符,不过有Pattern.DOTALL标志位,用于修改正则表达式的匹配行为。使得.字符能够匹配包括换行符在内的所有字符。
1 | public static void main(String[] args) { |
而Shiro中有一个类,RegExPatternMatcher,代码如下,很显然没有Pattern.DOTALL标志位,因此会出现匹配不到换行符的问题。
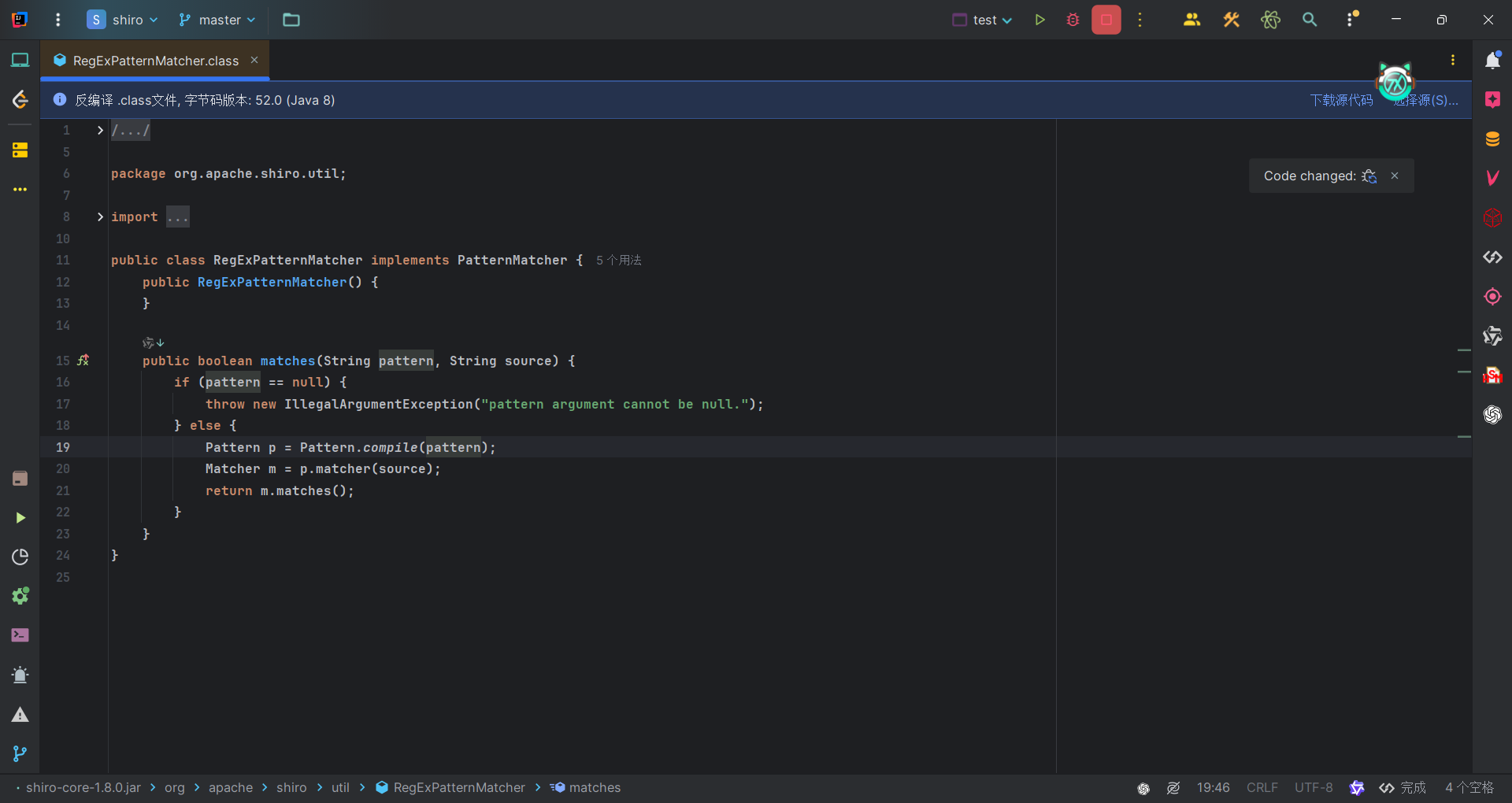
调试结果也如分析一样。

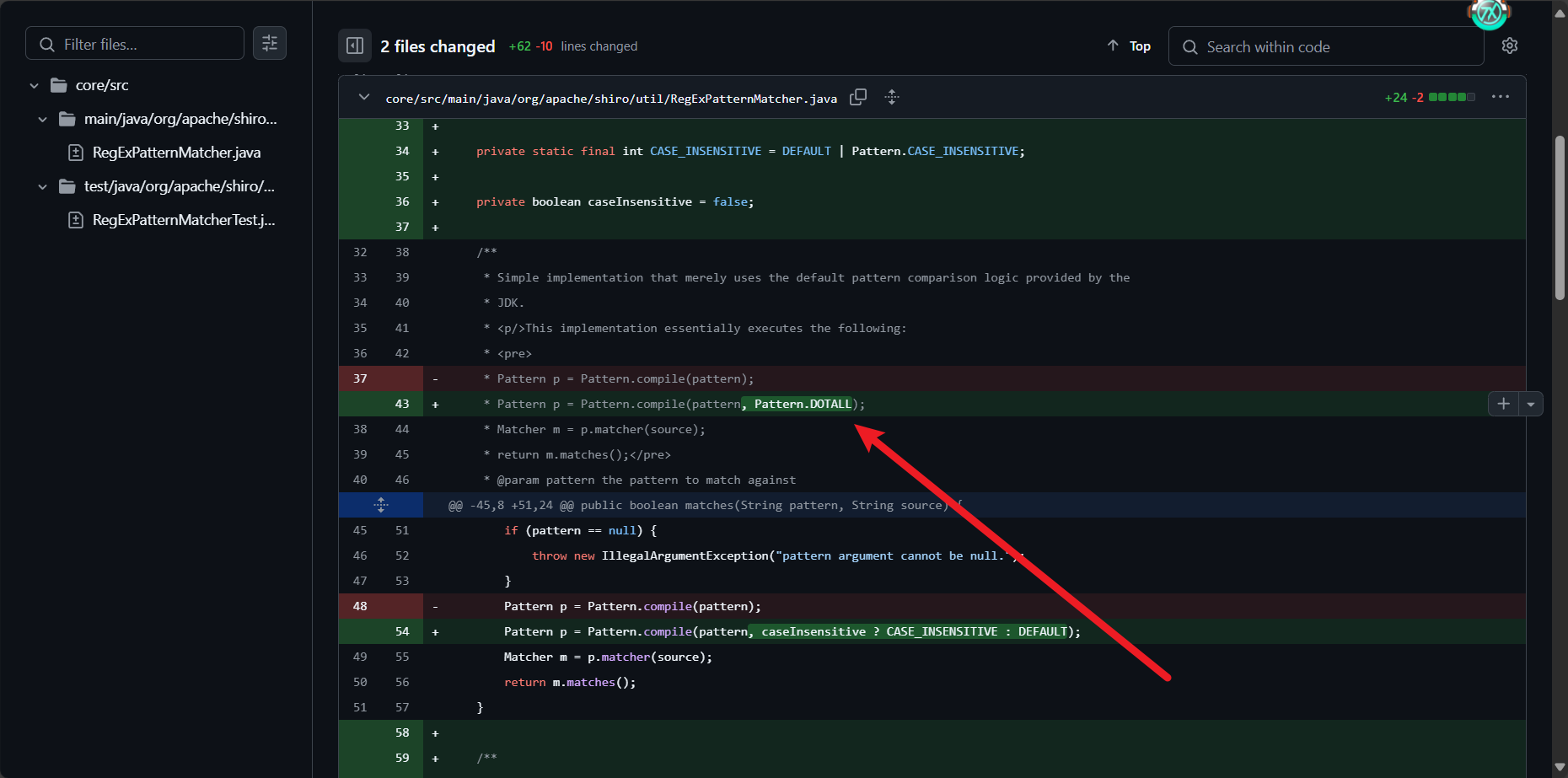
漏洞修复
设置了Pattern.DOTALL标志位
参考链接
https://mp.weixin.qq.com/s/eFUbnTTxL-_aU0AcIg5edQ
Lay0us/CVE-2022-32532: Apache Shiro CVE-2022-32532
CVE-2022-40664
Apache Shiro before 1.10.0, Authentication Bypass Vulnerability in Shiro when forwarding or including via RequestDispatcher.
漏洞信息
影响版本:shiro < 1.10.0
漏洞成因:经过forward的请求不会调用SpringShiroFilter进行过滤。
漏洞补丁:Allow for direct configuration of ShiroFilter through WebEnvironment · apache/shiro@d9a75a4
漏洞环境
1 | <!--shiro-spring--> |
添加接口
1 |
|
配置类如下
1 |
|
shiroFilterRegistration方法的配置是为了保证forward和include的请求也能经过SpringShiroFilter,因此如果没有这个配置,哪怕本身代码没有该漏洞中的bug,也能直接绕过。
权限路径配置:
1 | Map<String, String> filterChainDefinitionMap = new LinkedHashMap<>(); |
根据上面的配置,/CVE-2022-40664是需要管理员权限的,因此访问是会重定向到登录页面,而/cmisl是无限权限的,不过他会重定向到/CVE-2022-40664。
漏洞复现
直接访问/CVE-2022-40664,由于没有权限302跳转:

访问/cmisl,可以直接获取/CVE-2022-40664中的资源:
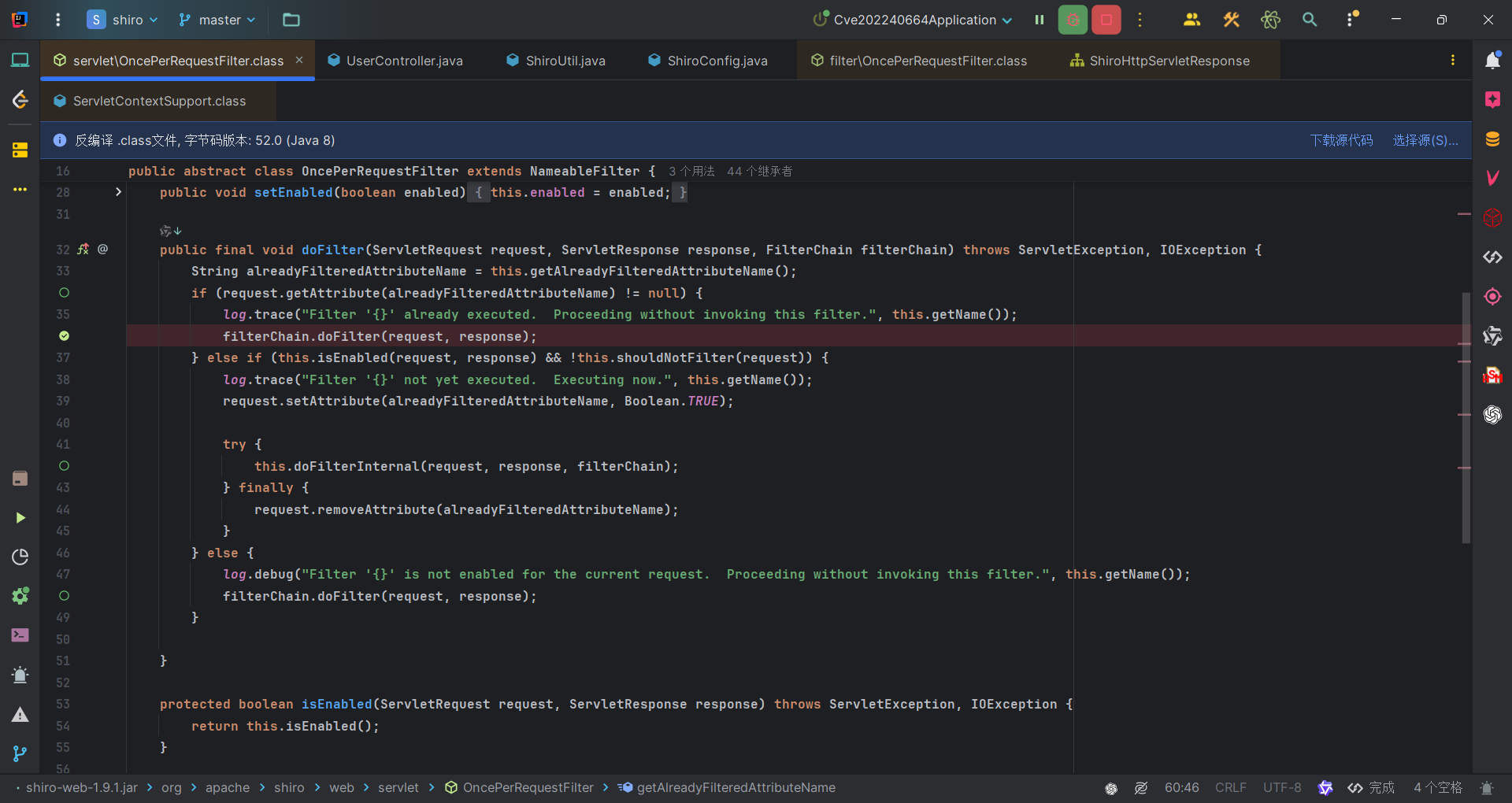
漏洞分析
问题出在OncePerRequestFilter类,该类的作用是确保每个请求只执行一次过滤器逻辑。通过检查请求属性判断是否已过滤,若未过滤且启用状态为真,则调用 doFilterInternal 方法执行具体过滤逻辑。
具体逻辑如下:
1 | flowchart TD |
我们的请求是/cmisl,首先if语句会判断springShiroFilter.FILTERED属性是否null,不是的话这个请求会进入到第二个if语句里,并且会将请求添加shiroFilter.FILTERED=true属性。
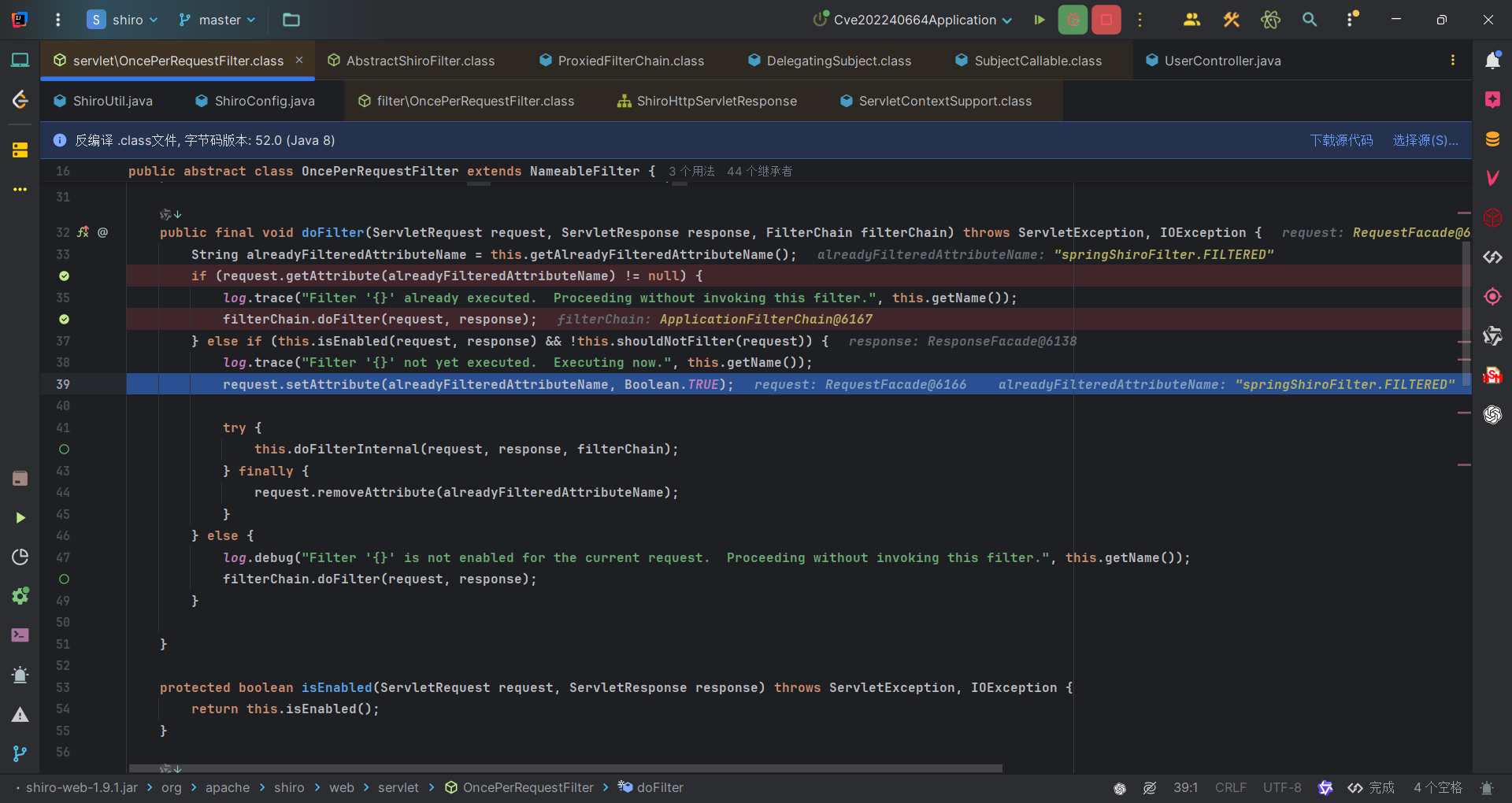
而经过forward转发的请求,其实和之前的还是一个请求对象,而刚刚我们在第二个if语句中为请求添加了添加shiroFilter.FILTERED=true属性,因此转发请求/CVE-2022-40664是会进入第一个if语句中,而第一个if语句是认为请求已经经过了SpringShiroFilter过滤器的过滤了,记录日志之后调用下一个过滤器。所以转发后的请求是没有调用SpringShiroFilter。
漏洞修复
在第一个if语句判断请求是否已过滤时,除了原来shiroFilter.FILTERED属性不为null之外添加filterOncePerRequest也为True的这个条件保证转发后的请求也会调用SpringShiroFilter。

参考链接
【漏洞分析】Apache Shiro身份验证绕过漏洞(CVE-2022-40664)
Shiro CVE-2022-40664 请求转发导致的验证绕过 - FreeBuf网络安全行业门户
关于filter过滤器为何不能过滤转发的请求 - mrsl - 博客园
CVE-2023-22602
When using Apache Shiro before 1.11.0 together with Spring Boot 2.6+, a specially crafted HTTP request may cause an authentication bypass. The authentication bypass occurs when Shiro and Spring Boot are using different pattern-matching techniques. Both Shiro and Spring Boot < 2.6 default to Ant style pattern matching.
Mitigation:** Update to Apache Shiro 1.11.0, or set the following Spring Boot configuration value:
1 | spring.mvc.pathmatch.matching-strategy = ant_path_matcher |
Credit: Apache Shiro would like to thank v3ged0ge and Adamytd for reporting this issue.
漏洞分析
从Spring Boot 2.6开始,默认的匹配策略已经改为PathPatternParser。(原来是AntPathMatcher)
该漏洞就是CVE-2020-17510补丁因为SpringBoot版本过高而失效造成的,因此payload相同,我们回顾一下CVE-2020-17510的漏洞修复分析:
Shiro新增了一个ShiroUrlPathHelper类,是UrlPathHelper的子类,重写了 getPathWithinApplication 和 getPathWithinServletMapping两个方法,也就是让Spring处理URI的方式用了和Shiro一样的WebUtils#getPathWithinApplication方法。让Shiro和Spring以相同的方式处理URI,避免差异化导致的问题。
在配置类import导入了ShiroRequestMappingConfig类。
这个类就会将RequestMappingHandlerMapping#urlPathHelper设置ShiroUrlPathHelper。使得Spring会用ShiroUrlPathHelper,也就是Shiro的处理方式去处理路径。
看起来修复的很完美,但在Spring的高版本中,patternParser默认值是true,因此会走默认的UrlPathHelper.defaultInstance来处理,而不是ShiroUrlPathHelper。
所以这个漏洞不能Spring版本太高或太低,如果太低,由于alwaysUseFullPath为false会获得Servlet路径清洗处理后的剩余路径。如果版本太高,又会因为patternParser默认值是true走走默认的UrlPathHelper.defaultInstance。
所以在学习CVE-2020-17510的过程中就已经顺带学习到了该漏洞,不过多赘述。
漏洞修复
匹配模式改为ANT_PATH_MATCHER使得patternParser值为false,走向ShiroUrlPathHelper来处理。

CVE-2023-46750
URL Redirection to Untrusted Site (‘Open Redirect’) vulnerability when “form” authentication is used in Apache Shiro.
Mitigation: Update to Apache Shiro 1.13.0+ or 2.0.0-alpha-4+.
漏洞信息
影响版本:shiro < 1.13.0
漏洞成因:在使用 Apache Shiro 的“表单”身份验证时,存在 URL 重定向到不受信任网站(“开放重定向”)的漏洞。
漏洞补丁:Add tests for SavedRequest redirects · apache/shiro@d62387d
漏洞环境
1 | <!--shiro-spring--> |
1 |
|
漏洞复现
访问//baidu.com,会302跳转到登录接口,同时设置Cookie。
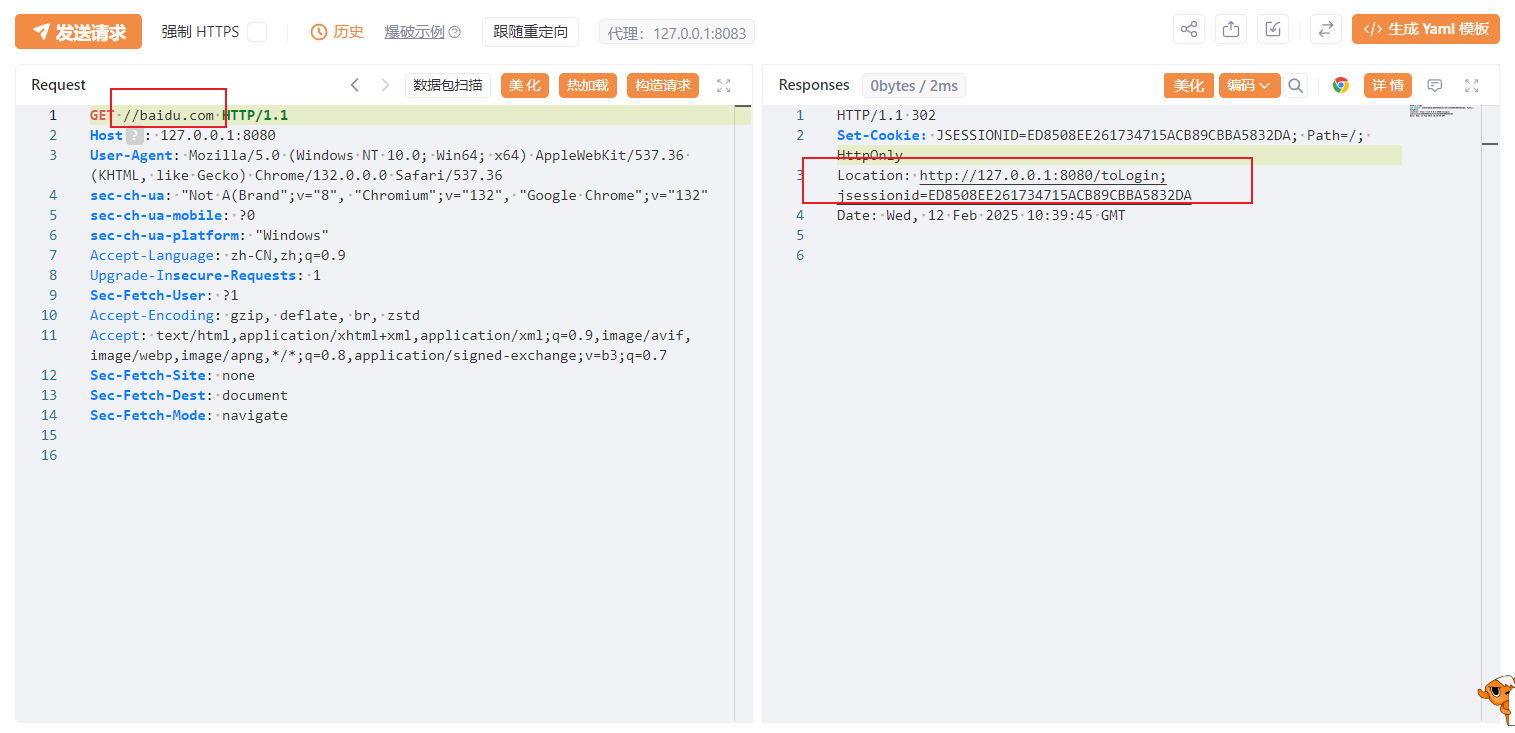
然后将跳转到登录接口的数据包发送,带上上一次返回包的Cookie,通过返回包可以看到是要将我们重定向到http://baidu.com
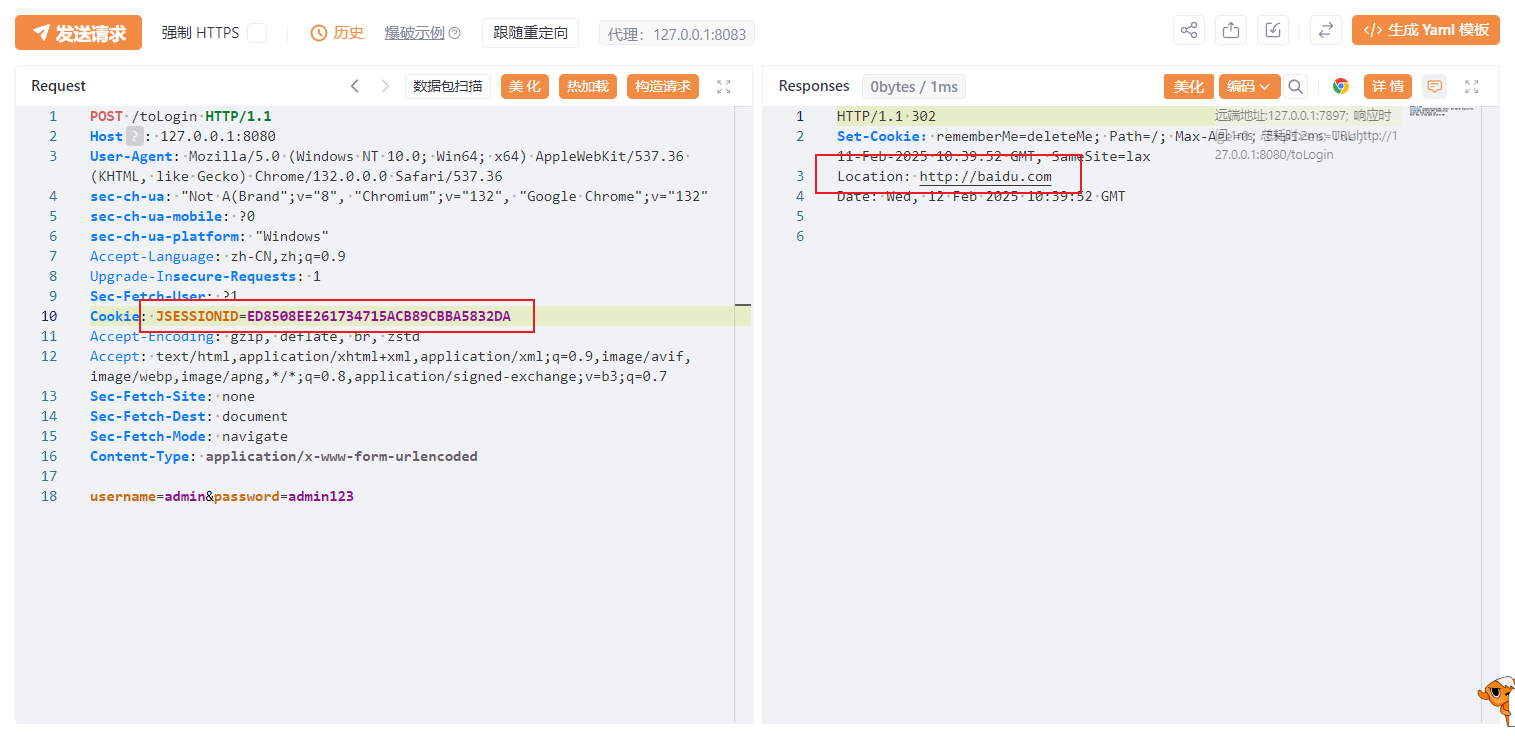
因此这里是存在一个重定向的漏洞。
漏洞分析
根据官网漏洞描述,漏洞主要来源于 “form” authentication,在使用 Apache Shiro 的“表单”身份验证时,存在 URL 重定向到不受信任网站(“开放重定向”)的漏洞。所以可以把目光集中在org.apache.shiro.web.filter.authc.FormAuthenticationFilter上。
我在在核心方法onAccessDenied上打上断点,这个方法主要是做一些拒绝访问的一些后续操作,比如拦截之后,需要将你重定向到登录页面,登录之后再让你返回你之前想要访问的页面,问题就出在我们可以在请求中访问任意网站,在登录后可以重定向到我们输入的网站。
打上断点我们访问//baidu.com,首先就是判断这是不是一个登录请求,是的话进入if语句中,否则进入else语句。显然我们访问的不是。于是进入else。这里主要是执行了一个saveRequestAndRedirectToLogin方法,从方法名不难看出这是保存请求并重定向到登录页面。
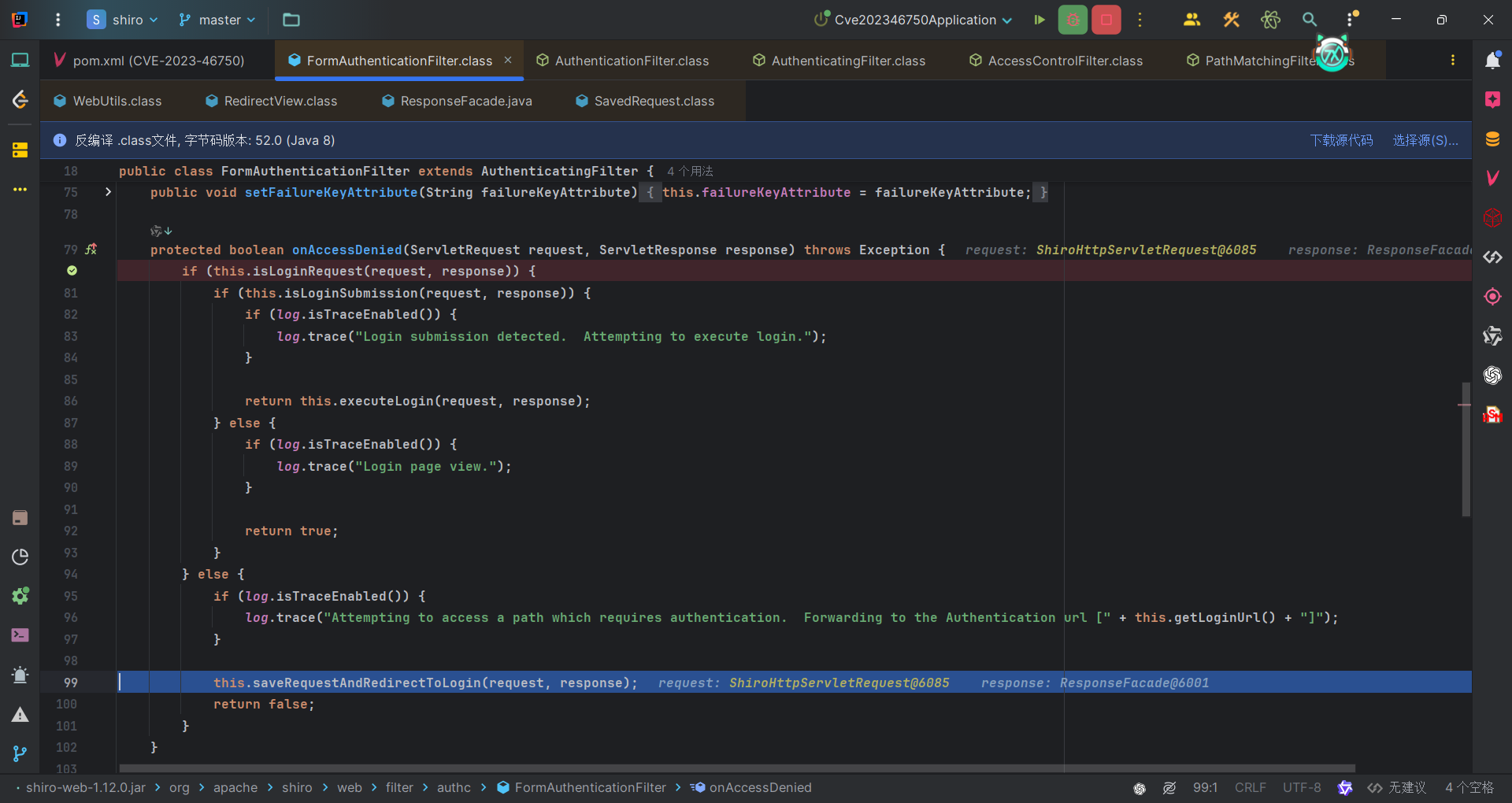
分为两步,先用WebUtils.saveRequest方法保存请求,再用WebUtils.issueRedirect方法去重定向到登录页面。
1 | protected void saveRequestAndRedirectToLogin(ServletRequest request, ServletResponse response) throws IOException { |
进入WebUtils.saveRequest方法,创建了一个会话session,然后将请求处理成SavedRequest类的一个实例,很简单的一个类,里面三个参数分别是请求类型,请求参数和请求URI。然后将这个实例保存为会话session的shiroSavedRequest属性。

然后是重定向到登录页面。通过WebUtils.issueRedirect方法后续调用到ResponseFacade#sendRedirect方法完成重定向。

接着我们发送登录的数据包,带上刚刚302跳转时给我们的Cookie。
还是在FormAuthenticationFilter#onAccessDenied方法。这次因为是登录请求,所以可以直接进入if语句。
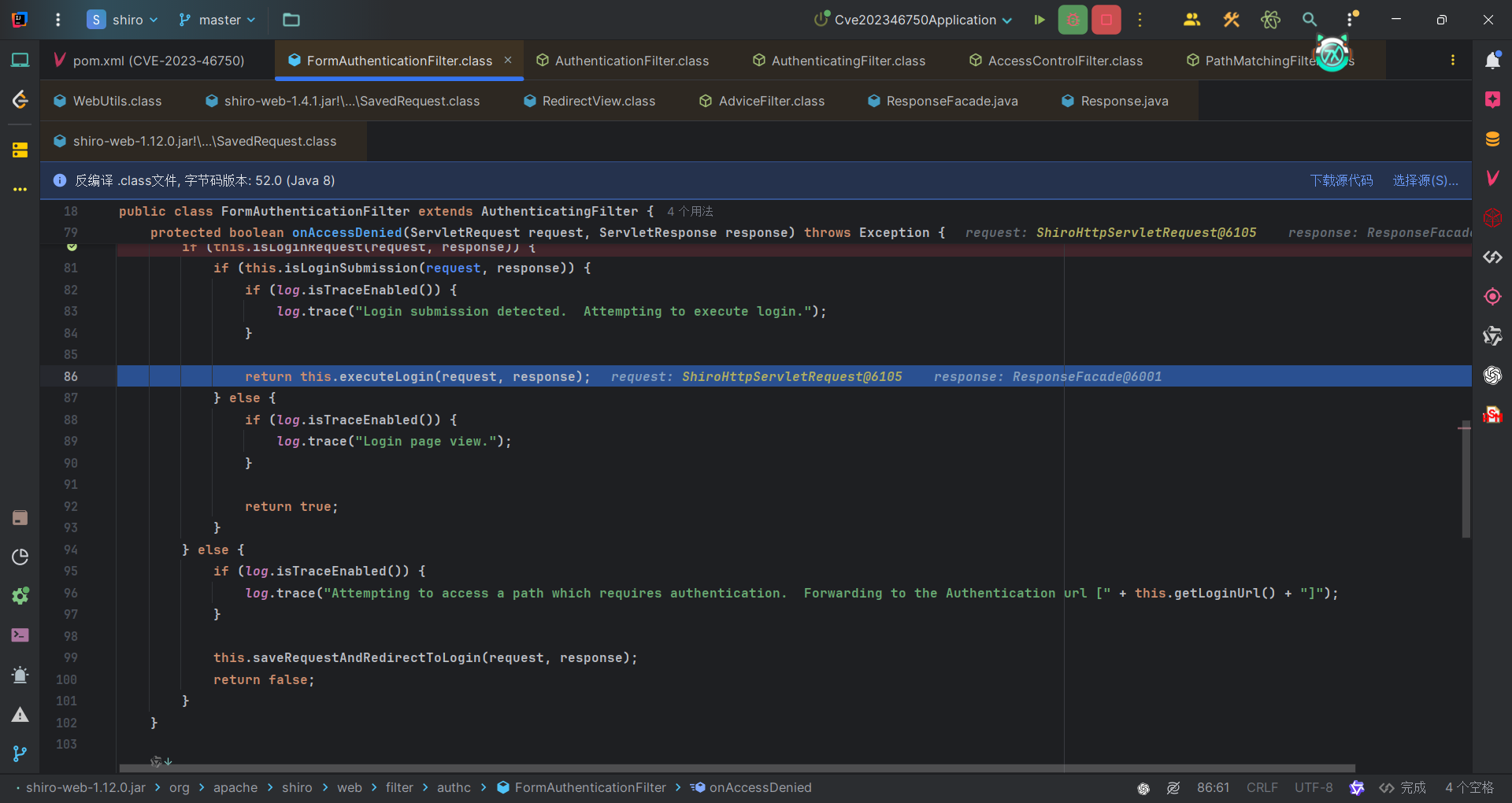
主要是调用了AuthenticatingFilter#executeLogin方法执行登录逻辑。首先获取token,也就是登录凭证,比如账号密码,验证身份。成功后调用onLoginSuccess方法
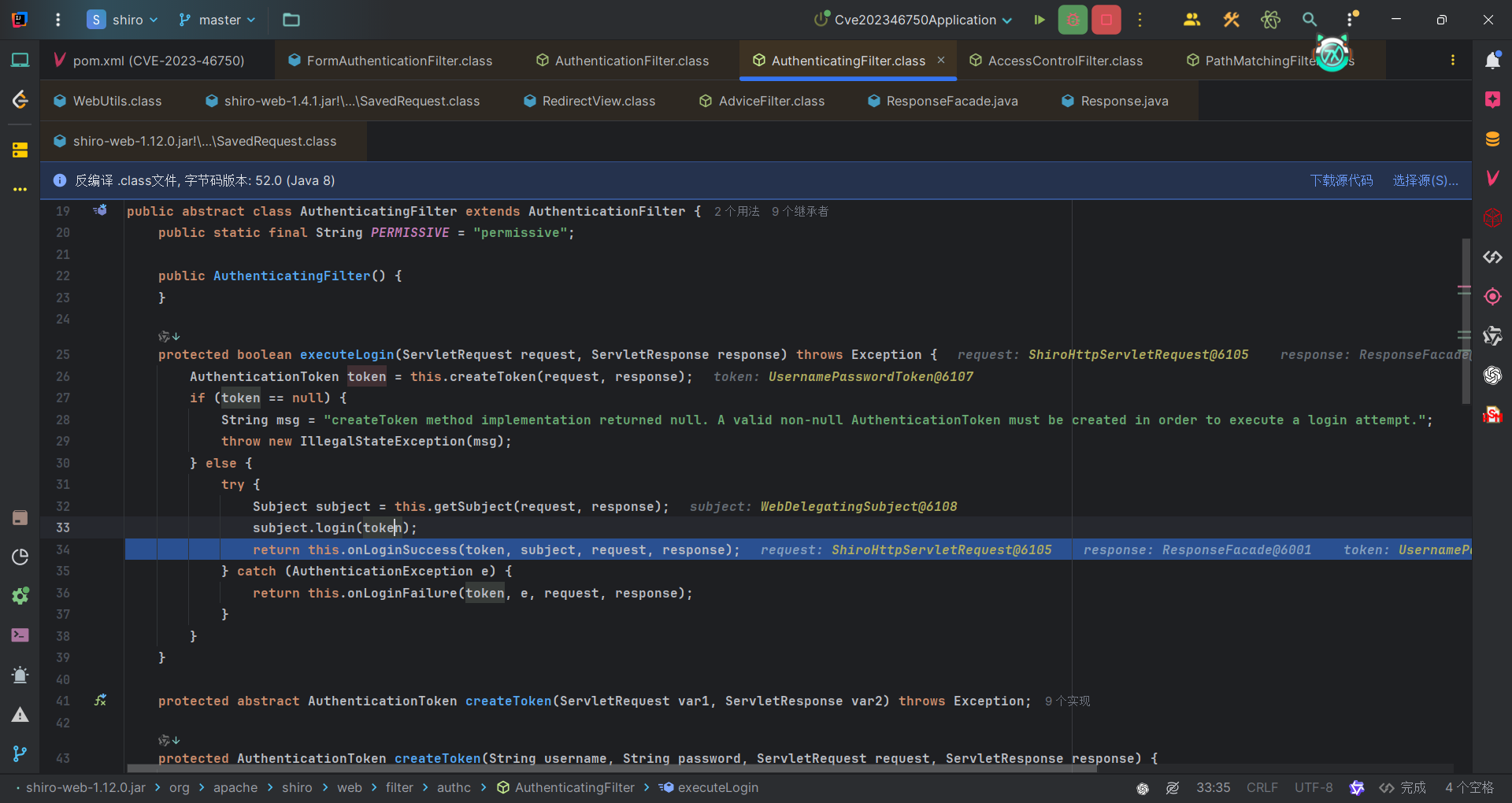
这个方法调用了WebUtils#redirectToSavedRequest,重定向到savedrequest,也就是登录之后会重定向去savedrequest的URI,也就是我们之前保存的请求。
1 | protected boolean onLoginSuccess(AuthenticationToken token, Subject subject, ServletRequest request, ServletResponse response) throws Exception { |

其中几个方法代码如下,先获取用户主体的会话session,然后从session中获取shiroSavedRequest属性,正是我们之前保存的SavedRequest实例。这个实例中的RequestUrl属性就是我们之前保存的请求URI,也就是//baidu.com。
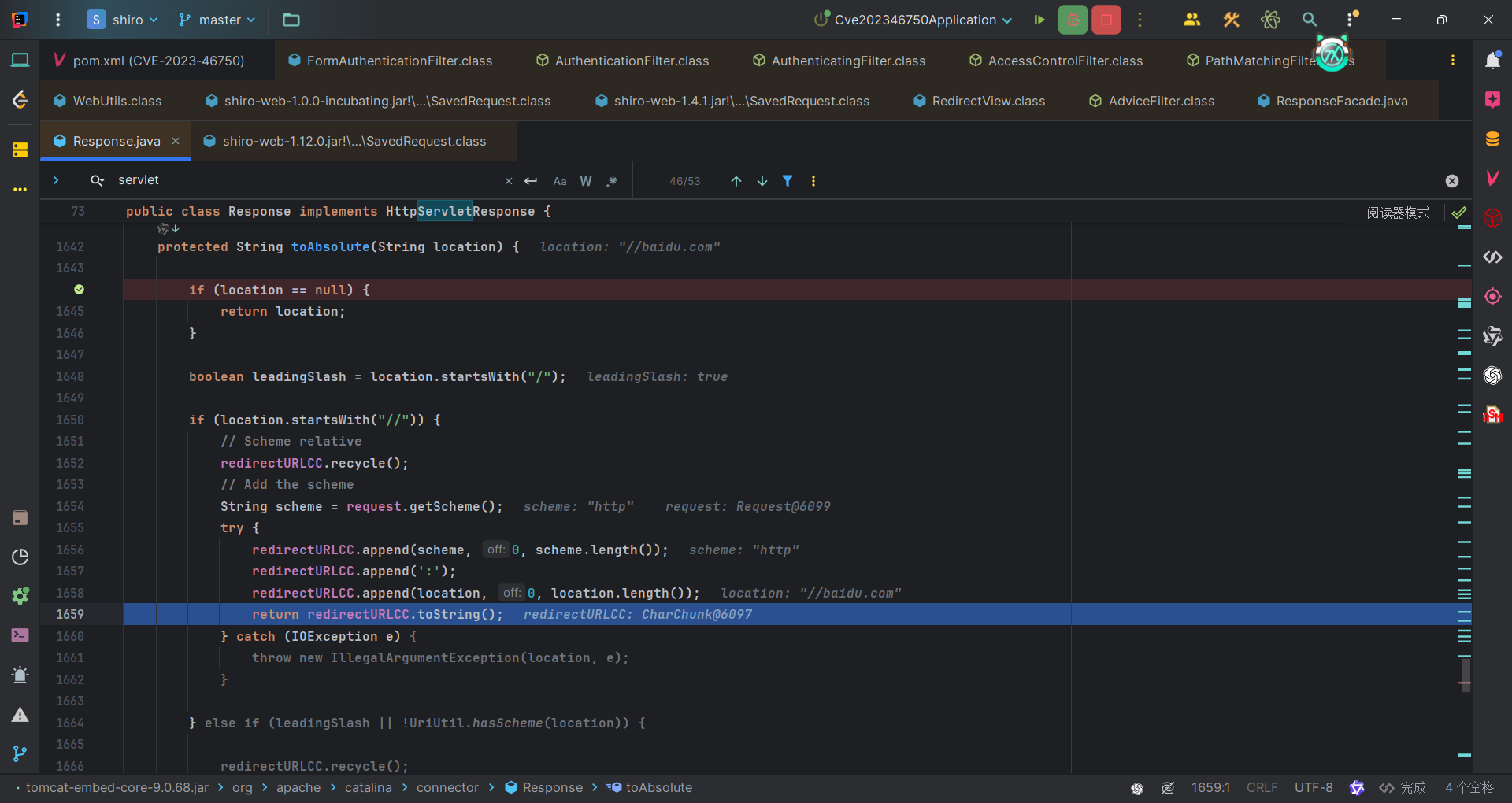
1 | public static SavedRequest getAndClearSavedRequest(ServletRequest request) { |
然后就和之前一样,拿着该URI进行一个重定向。Response#sendRedirect方法会对URI进一步处理,比如//baidu.com,没有协议头后续在Response#toAbsolute方法会添加协议头。
漏洞修复
在获取保存URI时去掉多余的斜杠”/“。

参考链接
Apache Shiro FORM URL Redirect漏洞(CVE-2023-46750)-CSDN博客
后续
暂且先学习这些吧,大概还有2-3个还未分析,但有些累了,之后有余力再补上。