前言
最近想学习一下CodeQL,发现25年之后新版的CodeQL还是有很大的不同的,翻阅了以前的文章,很多东西都弃用了,并且有了新的替代方法和规则。最后翻阅了一些文档和尝试,学习了新版的污点分析的代码。
个人后面的打算是代码审计挖一些漏洞,然后尝试开发一款安全方面的项目或工具。再然后是接触其他领域的安全知识,比如云安全,web3等等。嗯….暂时的计划是这样。
希望能找到个个安全研究的实习吧…这年头安全工作有点难找,自己也比较菜(っ╥╯﹏╰╥c)
CodeQL
CodeQL 是一种用于代码分析的查询语言和引擎,由 GitHub(原Semmle)开发。它使得开发者能够编写查询来检查代码库中的潜在问题,包括但不限于安全漏洞、错误和代码异味。CodeQL 的核心理念是将代码视为可以查询的数据集,允许用户通过编写类似于数据库查询的方式来探索和分析代码结构。
安装与配置环境
codeQL安装需要两个部分,一个解析引擎,一个SDK。本次用到的版本是v2.20.5。
codeQL引擎:https://github.com/github/codeql-cli-binaries/releases
codeQL SDK:https://github.com/github/codeql
将其都放到一个目录里。我这里引擎命名为codeql-cli,SDK命名为codeql-codeql-cli-latest。

为引擎目录配置环境变量:
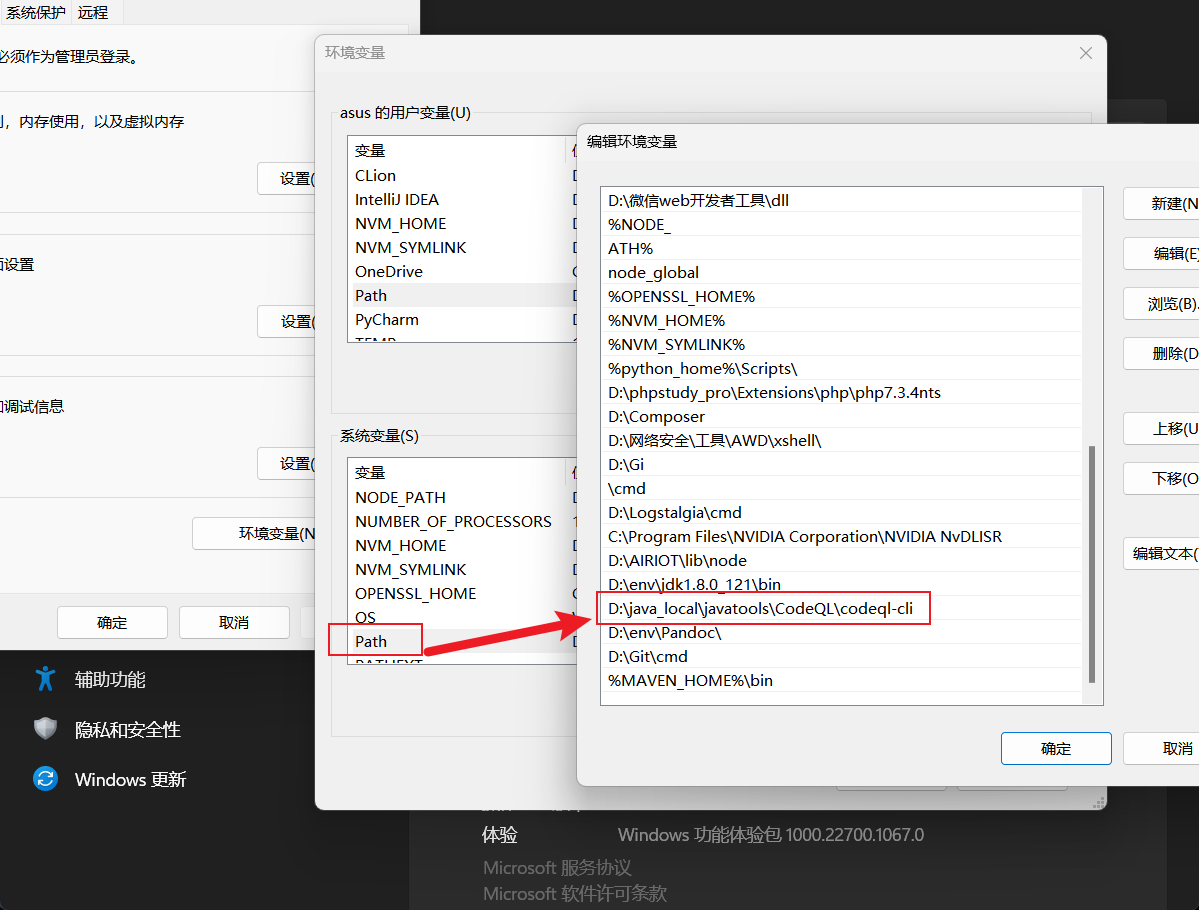
CMD中运行codeql,返回如下结果就是成功了:
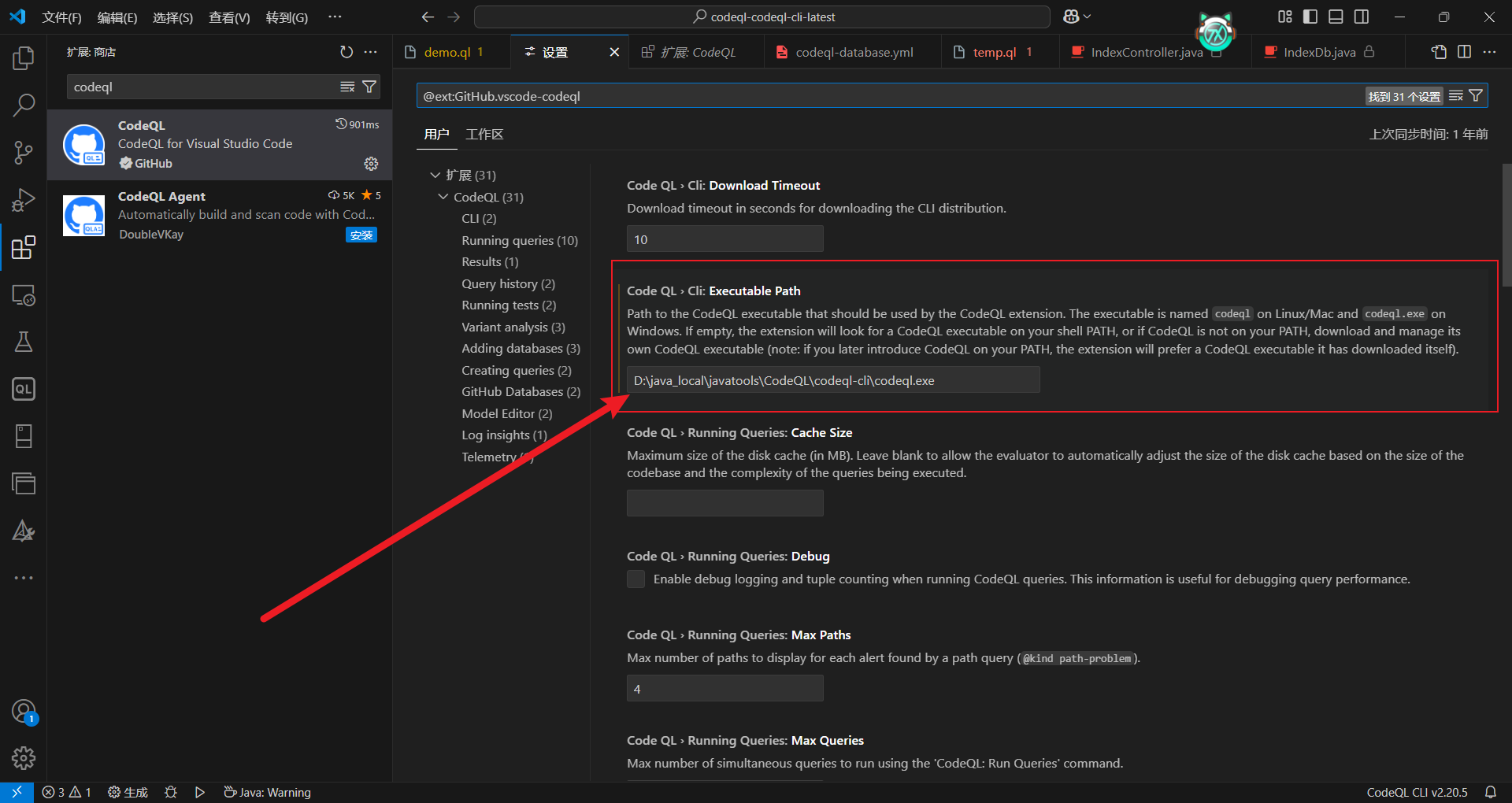
vscode下载插件codeql,并且设置我们引擎的exe文件。
然后再找一个靶场:l4yn3/micro_service_seclab: Java漏洞靶场
1 | database create codeqldemotest --language="java" --command="mvn clean install --file pom.xml" --source-root=D:\java_local\javatools\CodeQL\java_project\micro_service_seclab-main |
该命令是用来创建一个CodeQL数据库的,这个数据库可以用于后续的代码分析。
database create codeqldemotest: 这一部分指定了要创建的CodeQL数据库的名字,这里是codeqldemotest。--language="java": 指定要分析的编程语言是Java。--command="mvn clean install --file pom.xml": 这个选项指定了在创建数据库之前需要运行的命令。这里使用的是Maven构建工具的命令,它将清理项目、编译源代码,并安装生成的包到本地仓库中。--source-root=D:\java_local\javatools\CodeQL\java_project\micro_service_seclab-main: 指定了包含源代码的目录,即项目的根目录。
将生成的codeql数据库目录导入进codeql插件即可。
然后将sdk目录导入到vscode中,在codeql-codeql-cli-latest\java\ql\examples下创建ql文件,或者在该目录下新建一个用来存放我们自己编写的ql文件的目录qlExpression。
随便编写一个输出helloworld的ql文件,用来测试是否能否运行。编写好后右键,选择Run Query on Selected Database选项。
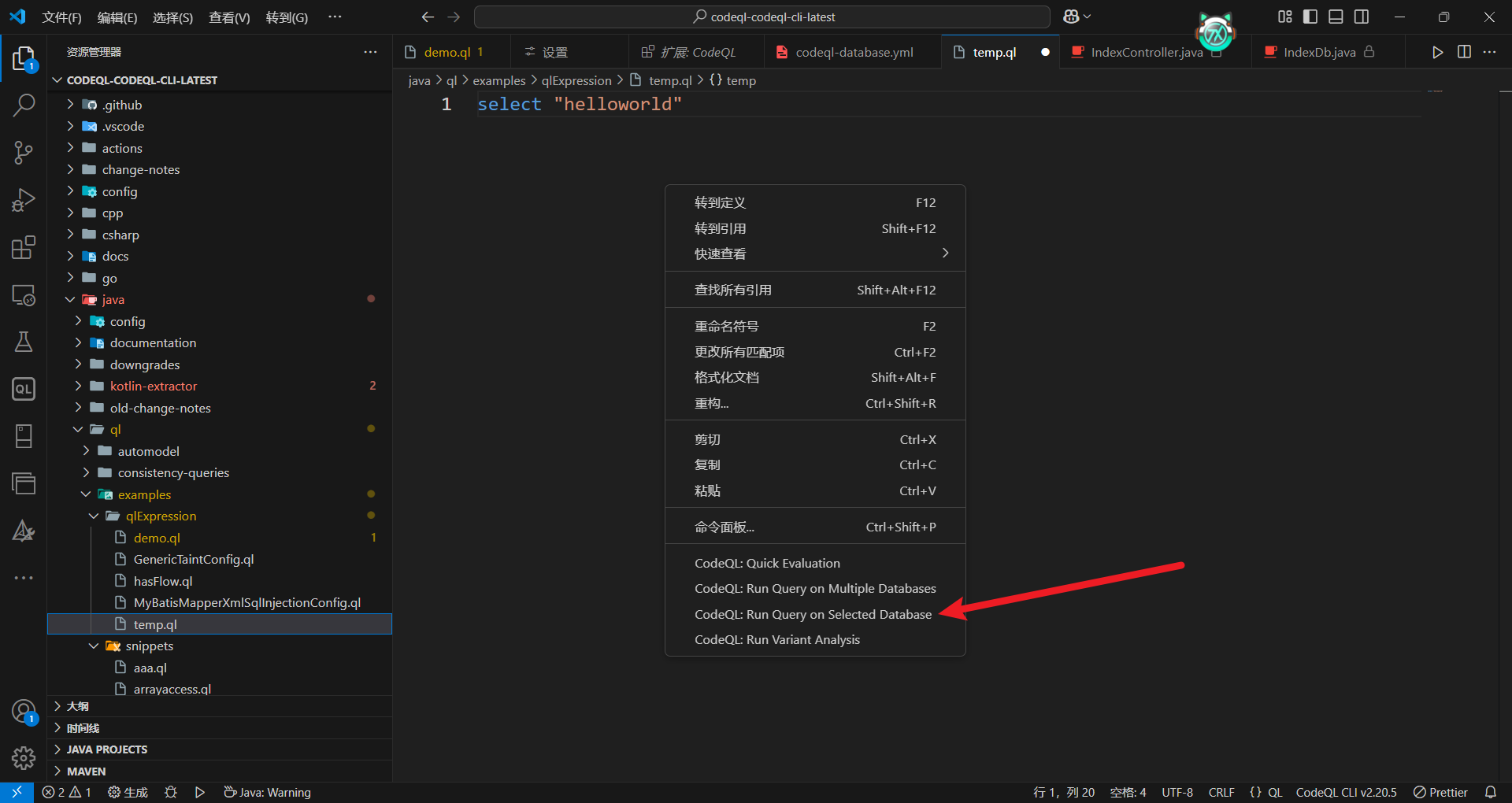
正常运行了,说明环境配置的没问题。
数据流/污点分析模版
关于数据流分析的部分,由于在2024年12月删除了旧版的库,所以在此之前的一些文章中的代码会与现在的代码有所不同。具体可参考下面两条链接:
New dataflow API for writing custom CodeQL queries - GitHub Changelog
在 Java 和 Kotlin 中分析数据流 — CodeQL
在查询了一些资料后编写了当前新版本的一个污点分析的模版:
1 | import java |
一些基本概念一下:
污点源(Source): 污点源是指程序中引入外部输入的地方。这些外部输入可能来自用户、网络、 文件系统等不可信来源。由于这些输入未经验证或清理,因此它们被认为是潜在的不安全数据。在进行污点分析时,首先需要识别并标记这些污点源。
污点汇聚点(Sink): 污点汇聚点是程序中使用污点数据的地方。如果未经过适当的验证或无害处理,直接使用污点数据可能会导致安全问题,如SQL注入、跨站脚本攻击(XSS)等。污点分析的目标之一就是确保所有从污点源到达污点汇聚点的数据都已经过适当的验证和无害处理。
无害处理(Sanitization): 在某些情况下,程序会对污点数据执行特定的操作以消除其潜在风险,比如加密、过滤非法字符等。这样的操作被称为无害处理。如果一个变量经过无害处理后,它的污点标记可以被移除,因为它不再被视为对系统的威胁。(“isBarrier” 替代 “isSanitizer”)
只有当source和sink同时存在,并且从source到sink的链路是通的,才表示当前漏洞是存在的。

对污点分析的模版做一个大概得解释:
首先需要用DataFlow::ConfigSig接口实现一个模块,这个模块用于配置数据流分析的一些要素,比如isSource方法定义哪些节点视为“源”,isSink方法定义哪些节点视为“漏洞出发点”,isBarrier方法过滤一些误报问题。
然后通过TaintTracking::Global根据我们刚刚的配置模块创建一个全局的数据流跟踪引擎,其中包含一些必要的逻辑和方法进行整个程序的数据流分析。比如通过flowPath(source, sink)函数查找从配置模块中符合条件的Source到Sink的所有路径。
SQL
用靶场的SQL漏洞作为例子来学习CodeQL。
1 |
|
可以通过/one传递username参数,然后流向下面方法作为参数,进行数据库的一个查询。因此上方是Source点,下方是Sink点。我们要做的是用codeql的语法连接这两个点。
1 | public List<Student> getStudent(String username) { |
根据上面提到的,我们需要先设置一个配置模块,并且先简单设置一下isSource方法和isSink方法(在CodeQL中又可将方法称为谓词Predicate),用于标记哪些节点视为“源”和“执行点”。
1 | module SQLInjectionConfig implements DataFlow::ConfigSig { |
对于isSource:我们定义了任何属于或继承自RemoteFlowSource类的节点都会被视为一个数据流入点。该类是一个抽象类,我们可以自行申明一个子类,当然官方也自带了一些子类,其中就包含将Spring框架的输入点标记为数据流入点的子类。

对于isSink:用exists关键字找到符合条件的Method和MethodCall实例。首先我们关注的方法是SQL查询的方法,因此需要找到所有名为query的方法。接着借助找到的query方法Method实例,去找到其对应的方法调用MethodCall实例。最后需要满足这些MethodCall实例,也就是query的方法调用,其第一个参数是isSink方法传入的值。
1 | module SQLInjectionFlow = TaintTracking::Global<SQLInjectionConfig>; |
然后就是根据上面的配置模块,创建一个全局的数据流跟踪模块SQLInjectionFlow。通过该模块的flowPath(source, sink)查找从配置模块中符合条件的Source到Sink的所有路径。
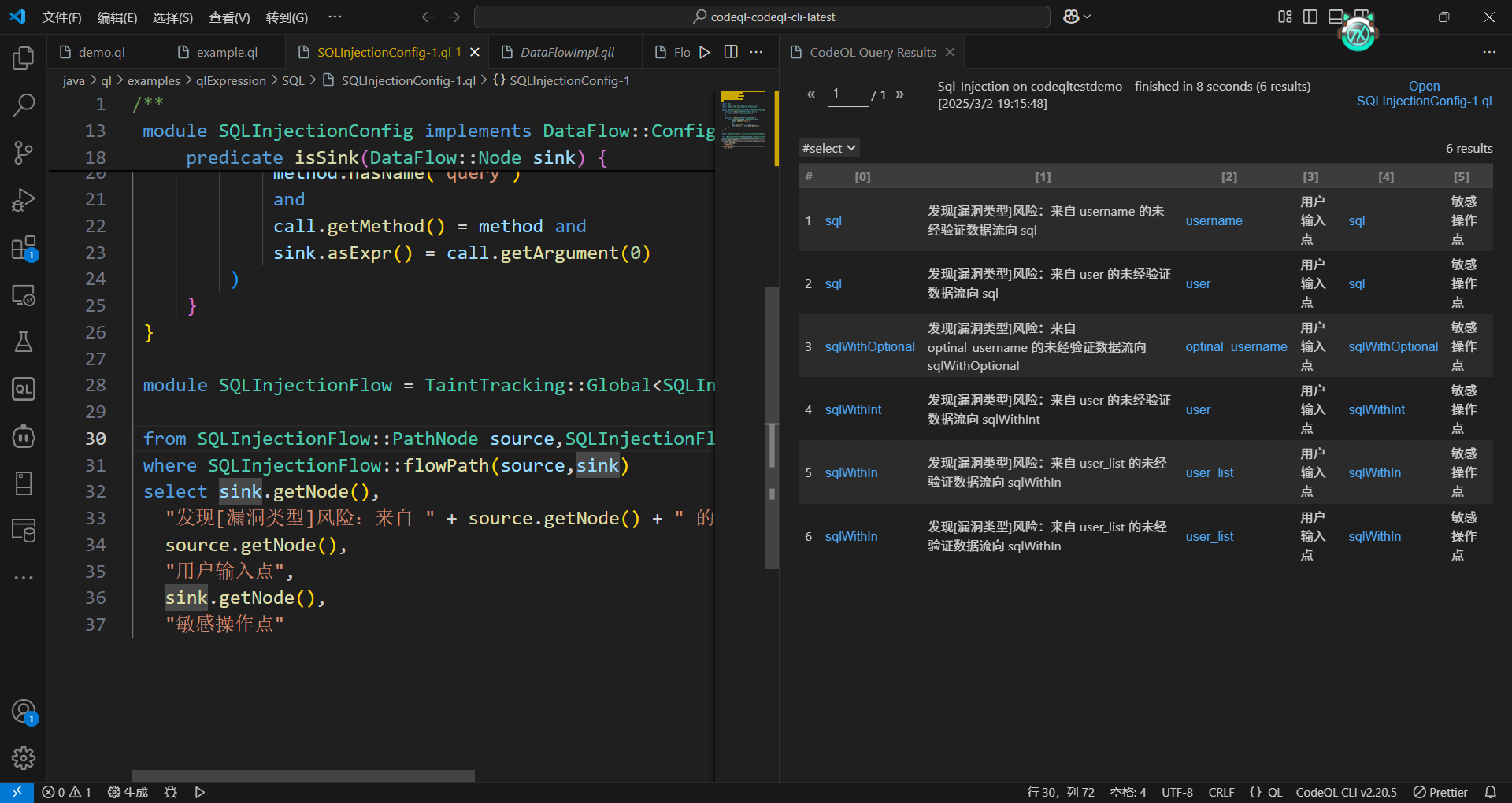
经过上面的查询之后,会发现其中有一个source是误报点。如下:
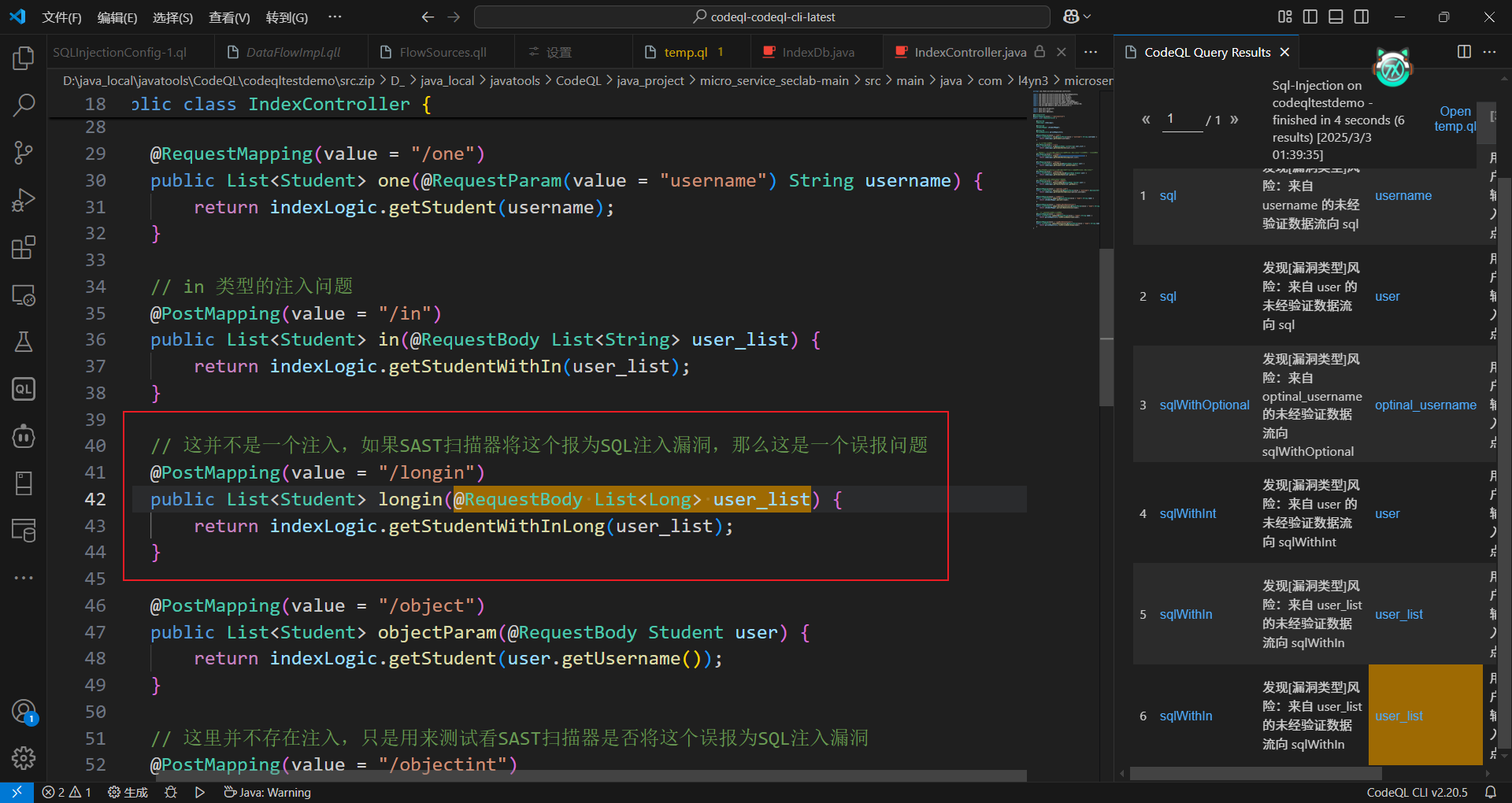
CodeQL标记为Source点,但是可以看到传入的参数类型是List<Long>,这一个Long类型的列表,比如POST发送的数据可以是这样:[1002, 1005, 1007]。而这种传输类型是不会存在SQL注入的问题的。因此我们要做的就是消除误报。而消除误报用到的就是配置模块中的isBarrier方法(谓词)。
isBarrier方法(谓词)被于定义数据流分析中的障碍点(barriers)。这些障碍点是程序执行流程中的某些位置,在这些位置上数据流被预期停止或改变方向。这意味着,如果一个节点被标记为屏障(即 isBarrier 方法返回真),那么数据流将不会通过这个节点继续传播。
1 | predicate isBarrier(DataFlow::Node node) { |
主要对原始类型和泛型类型过滤,node.getType() instanceof NumberType判断节点类型是否是NumberType类型或者其子类,而codeQL中,这个类型对应的就是去识别是否是java中的java.lang.Number,其子类如下,包括Long、Integer等等数字类型。如果是这些类型,数据流就被屏障拦截。

而使用了exists子句的过滤,针对泛型类型(如 List<Long>、Set<Integer>),该子句检查是否存在这样的ParameterizedType实例pt,使得节点的类型等于pt,并且pt的第一个类型参数是NumberType的子类。这样,当数据流经过像List<Long>这样的泛型集合时,由于类型参数是数值类型,就会被屏障拦截,从而消除误报。